
powershell -- using the Acrobat COM object to access metadata
I have related posts at powershell -- iterate over a collection of PDFs looking for those with specific info.subject and at the TechNet Powershell forum powershell -- iterate over a collection of PDFs looking for those with specific info.subject
A user on the TechNet forum suggested using the Acrobat COM object and posting here. Is there any documentation about using Acrobat.dll as a COM object (hopefully with examples)?
Again, my goal is to be able to iterate over a collection of PDFs looking for those with specific values stored in the metadata.
I work at a DoD site, so it's very difficult to get any 3rd-party software approved, but if I can use Acrobat.dll as a COM object, hopefully I won't need any 3rd-party software.
As you can see in the screenshot below, someone has figured out how to access PDF metadata from the OS level, presumably without any additional software.
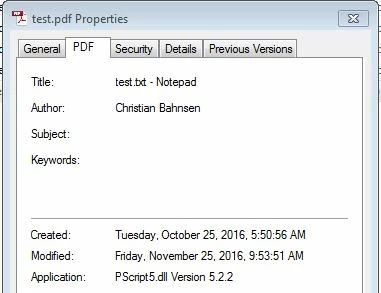
Thanks,
Christian Bahnsen
