意図されることと合致するかどうかですが、特定ページだけをテキスト認識させることは可能です。
「テキスト認識」で「このファイル内」を選んだ後に「設定」を押すことによって、
表示ページや範囲としての設定を行うことができるようになっています。
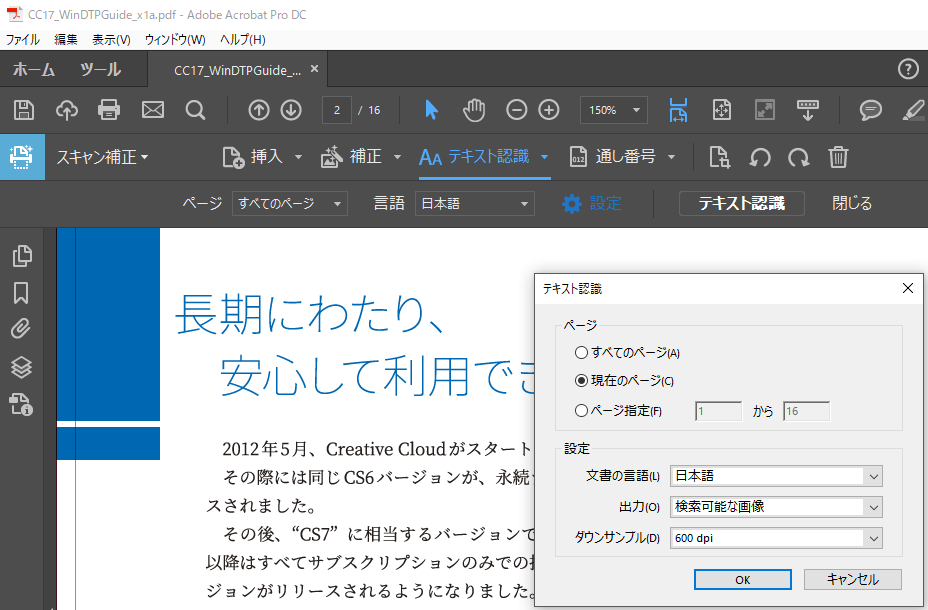
ただし、飛び石的なページ指定はできませんから、あくまでも範囲指定のみです。
他に行うとしたら、一度抽出してから認識させて、戻してしまう、くらいでしょうか。
なお質問される際はOSバージョンや具体的な利用バージョンなどを記載しましょう。
(ジャパンフォーラムのトップページ右上のテンプレートを最低限の基準として下さい)




 2
返信
2
返信


 AdChoices
AdChoices