


リンクをクリップボードにコピー
コピー完了
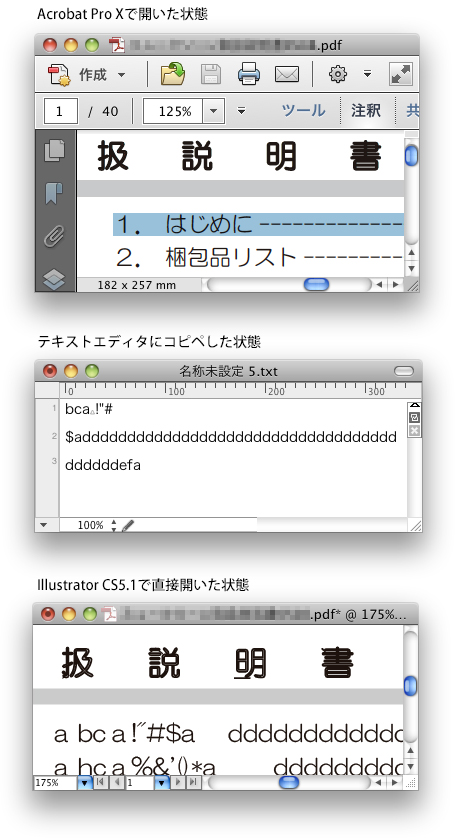
PDFのテキストを取り出したいのですが文字化けします
クライアントから原稿として支給されたPDFから
テキストを取り出したいのですが文字化けしてしまいます。
Acrobatで開いたときは可読状態なのですが、
テキストを選んでコピー → テキストエディタにペーストすると
文字化けしてしまうのです。
IllustratorでPDFを直接開く等いろいろ試してみたのですが
どれも文字化けしてしまいお手上げ状態です。
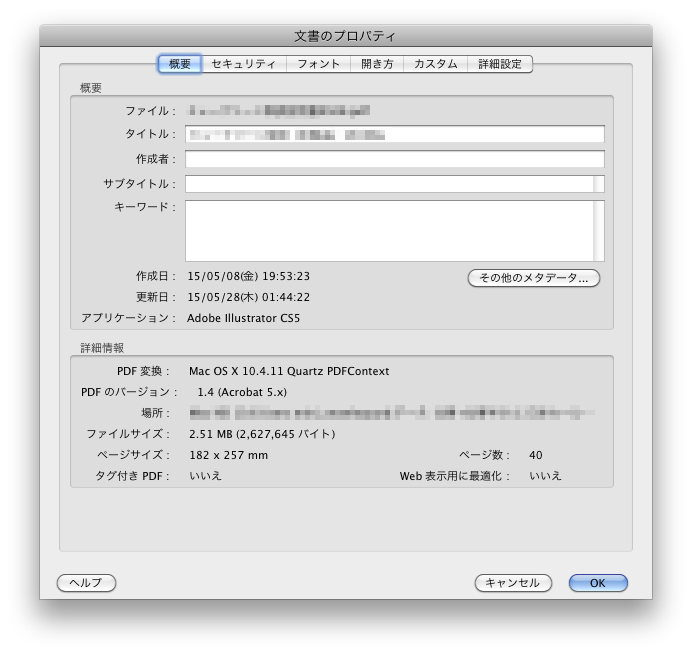
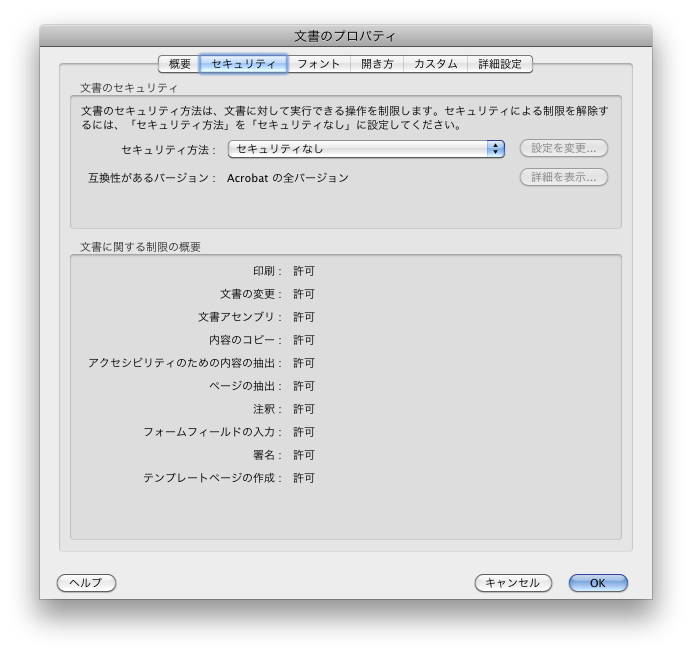
PDFにセキュリティは設定されておらず、
テキストは制限なくコピーできるはずです。
全てが文字化けするわけではありません。
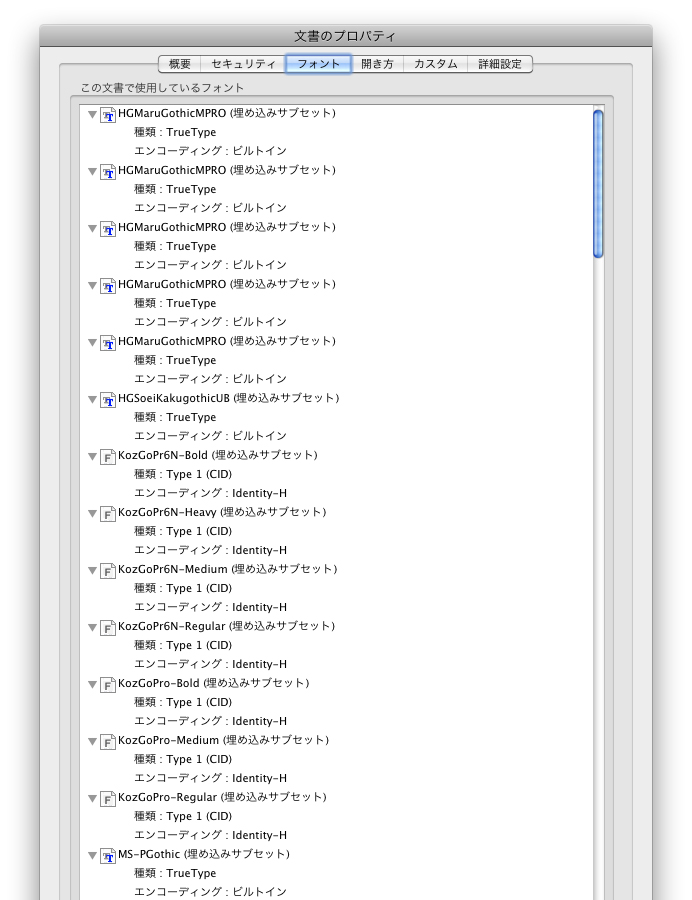
Acrobatのプロパティ → フォントで確認すると
文字化けするのは
HGMaruGothicMPRO(埋め込みサブセット)など
種類:TureType
エンコーディング:ビルトイン
文字化けしないのは
KozGoPro-Regular(埋め込みサブセット)など
種類:Type 1(CID)
エンコーディング:Identity-H
となっています。
このエンコーディングが「ビルトイン」がアヤシイと思いググってみたところ
「ビルトイン」で同じように悩んでいる方がいらっしゃるようなのですが、
「そういうPDFは文字化けするから注意しよう」とか
「画像に変換してOCR認識させてしまおう」などの記事がヒットし、
直接の解決方法を見つけることができませんでした。
元データはIllustratorで作っているらしいのですが、
諸般の事情で支給できないと言われてしまいました。
何か良い方法をご存じの方、ご教示ください。
または、解決方法なんて存在しないから諦めろというトドメでも結構です。
【PDFのプロパティ】
【当方の環境】
Mac OS 10.6.8
Acrobat X Pro(10.1.14)
Illustrator CS3〜CS6
Jedit X 1.47
テキストエディット 1.6(264)
プレビュー 5.0.3(504.1)
FireFox(38.0.5)
Safari 5.1.10(6534.59.10)
【試して失敗した方法】
Acrobatで開いてテキストを選択しコピー、Jeditにペースト。
(Jeditのエンコーディングは日本語(Mac OS))
OS付属のテキストエディットにペースト。
プレビューで開いてコピー、Jeditとテキストエディットにペースト。
PDFを直接Illustratorで開く。
フォントがインストールされていても文字化け。
Acrobatの別名保存 → リッチテキスト形式で保存、Jeditで開く。
開くときにエンコーディングを自動判定にせず
日本語以外(全く関係なさそうな外国語)にも切り替えてみましたが全滅。
Acrobatの別名保存 → テキスト(アクセシブル) → Jeditで開く。
(エンコーディングは自動判定/日本語(Mac OS))
Acrobatの別名保存 → テキスト(プレーン) → Jeditで開く。
内容が空っぽでした。
Acrobatの別名保存 → EPS → Illustrator CS5.1で開く。
文字化けしてない!と喜んだのもつかの間、
全てアウトライン化されていました…。
Acrobatの別名保存 → HTML → FireFoxとSafariで開く。
開いた後、文字エンコーディングを切り替えてみましたが、
どれも文字化け状態。
メッセージ編集者: rrm 2015/06/15 19:11画像を変更しました


 1 件の正解
1 件の正解

 3
返信
3
3
返信
3
リンクをクリップボードにコピー
コピー完了
エンコーディングに問題があるために正常に文字列として抽出できない状態です。
PDF変換をOS XのQuartz経由で行っているのが原因でしょう。
既にそのおつもりのようですが、あれこれ処理することを試行錯誤するよりも、
紙原稿とみなして文字入力したほうが早い状態だと思います。
追記します。
案だけなのでうまくいくかわかりませんが、
一旦AcrobatからPostScriptファイルに書き出して、DIstillerで変換してみてはどうでしょうか。
リンクをクリップボードにコピー
コピー完了
assause様、早速の回答ありがとうございます。
> PDF変換をOS XのQuartz経由で行っているのが原因でしょう。
そこが原因なんですね…。
せっかくIllustratorで作ったんだから、
別名保存するなりDistiller使うなりして
PDFにしてくれればいいのに…。
と愚痴っても仕方がないのですが。(^_^;)
> 一旦AcrobatからPostScriptファイルに書き出して、
> DIstillerで変換してみてはどうでしょうか。
試してみましたが、残念ながらダメでした。
今までコピペすると「bca」「dddefa g」と文字化けしていたところが
「CDB」「EEEFGB H」と、1文字ずつずれて大文字になるという、
さらに謎の文字化けを発症しています。
文字化けするフォントのプロパティは、
HGMaruGothicMPRO(埋め込みサブセット)
種類:Type 1(前はTureType)
エンコーディング:カスタム(前はビルトイン)
に変わりました。
そして、元々化けない文字は、やっぱり化けません。
Illustratorに配置 → EPSで保存 → DistillerでPDFに変換
も試してみましたが、同様に1文字ずれて大文字の文字化けになりました。
最初に書くのを忘れたのですが、他にも
Illustratorに配置 → リンクを埋め込み
Illustratorに配置 → PDFとして別名保存
InDesign CS5.5に配置 → PDF書き出し
も試して失敗に終わっています。
ここまで試行錯誤して、
他の方法も提案していただきましたが、
現状では無理ということで今日のところは諦めて、
OCRを使うなり手打ちするなりで
テキストを自前で用意することにします。
ただ、今後同様の事案が発生したときのためにも、
もしかしたら
この世のどこかに解決策をご存じの方が
いるかもしれないという一縷の望みにかけて、
しばらく未回答のままにさせてください。

リンクをクリップボードにコピー
コピー完了
私もクライアントから提供されるpdfの文字化けに悩まされていた1人です。
私の解決方法ですが、pdfを開いて「ファイル」→「書き出し形式」→「スプレッドシート」→「MicrosoftExelブック」で保存。
その後Numbersで開いて抽出しています。全てのケースに当てはまるかは解りませんが、一例として報告しておきます。

 AdChoices
AdChoices