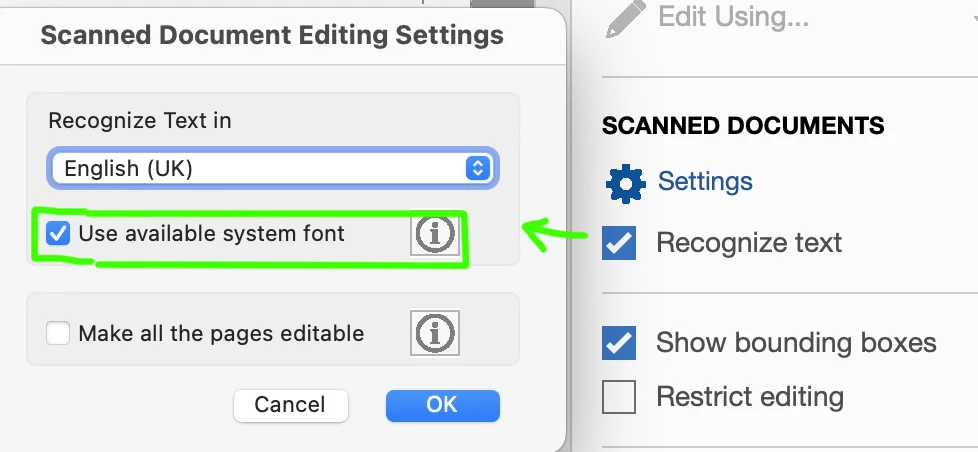
Acrobat Pro OCR ends up with different fonts to system fonts.
I have scanned a document into a pdf file. I then use Acrobat Pro Edit PDF tool, to recognise the text in the document.
It finds all the text in the document, but the fonts it uses/embeds have a number at the end of the font name.
So for example, text that is Times Roman font, will be Times Roman-13009 or Times Roman 13009 as the font name in Edit PDF font section.
What then happens, is that when I go to edit the text, such as delete or change a word, the new text doesn't match and looks different.
What is causing this to happen, why does the Recognise text function make the font name with a number after it?
Under Document Properties/Font, it says the font is embedded, which I am assuming it says that because my system does have standard Tines Roman font installed. But having the number after it in the font name is like its a different font.
Does anyone know about this issue and how to fix it /prevent it from happening?
Thankyou..