
Question
Autotagged tags in Tags panel, Content Panel, and Read Order do not match
On Windows 10 with Acrobat Pro DC version 2019.012.20040 (latest):
When I autotag a document, tags in the Tags panel may appear reasonably correct, but when the Read Order structure labels and Content types do no not match the Tags.
Shown is a fresh autotag of a PDF from InDesign. In the Tags panel, the title and "United States" are both H1, but according to the Read Order tool as well as the Contents Panel, they are both Paragraphs. When I read this with NVDA, they are both paragraphs, not headings.
The document may be downloaded at
https://www.cdc.gov/drugoverdose/pdf/pubs/2018-cdc-drug-surveillance-report.pdf
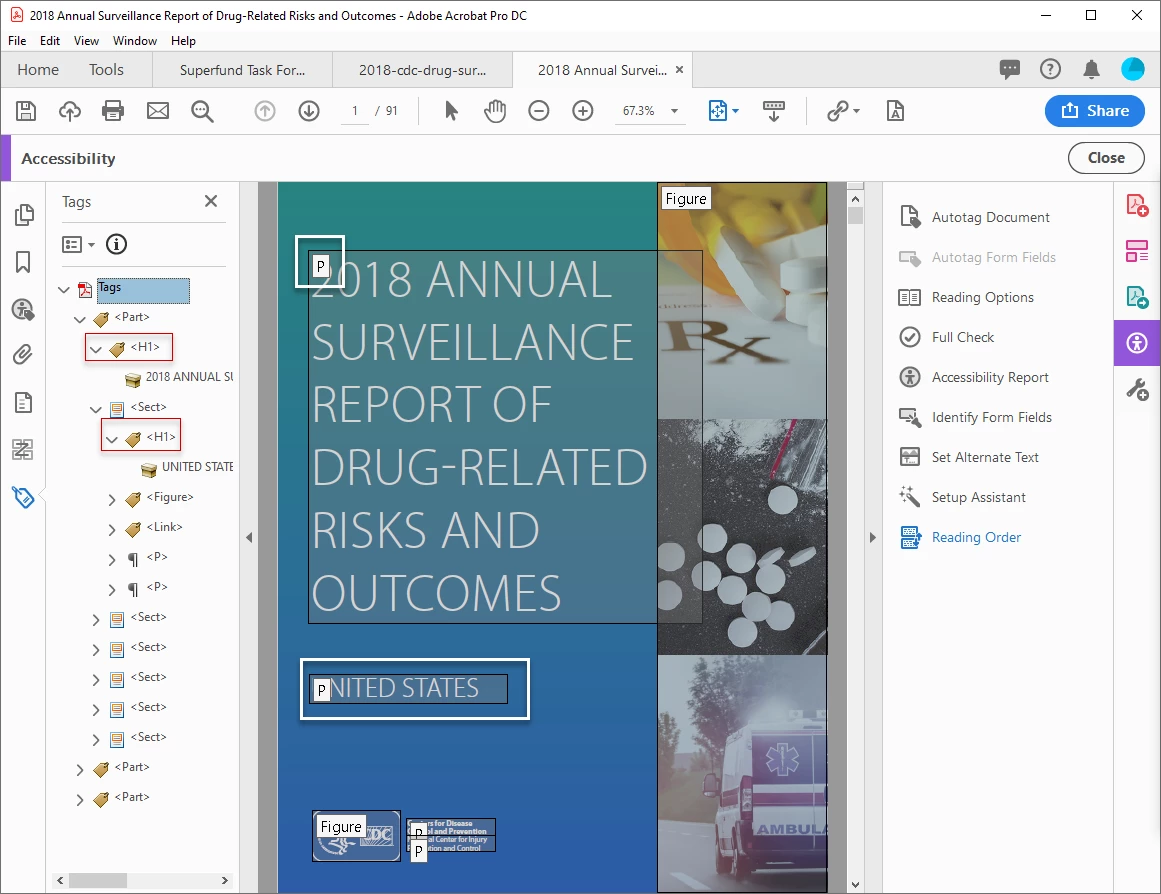
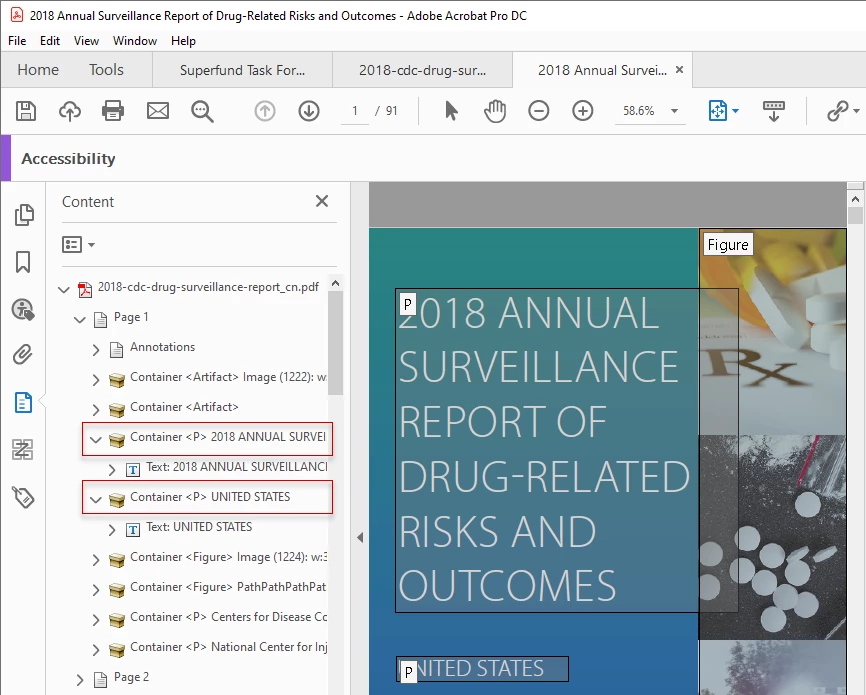
All of these mismatches have to be retagged manually.