I have extracted the attached pdf file and got a json & excel tables.
The tables are extracted perfectly. (The attached pdf has removed sensitive numbers in the table)
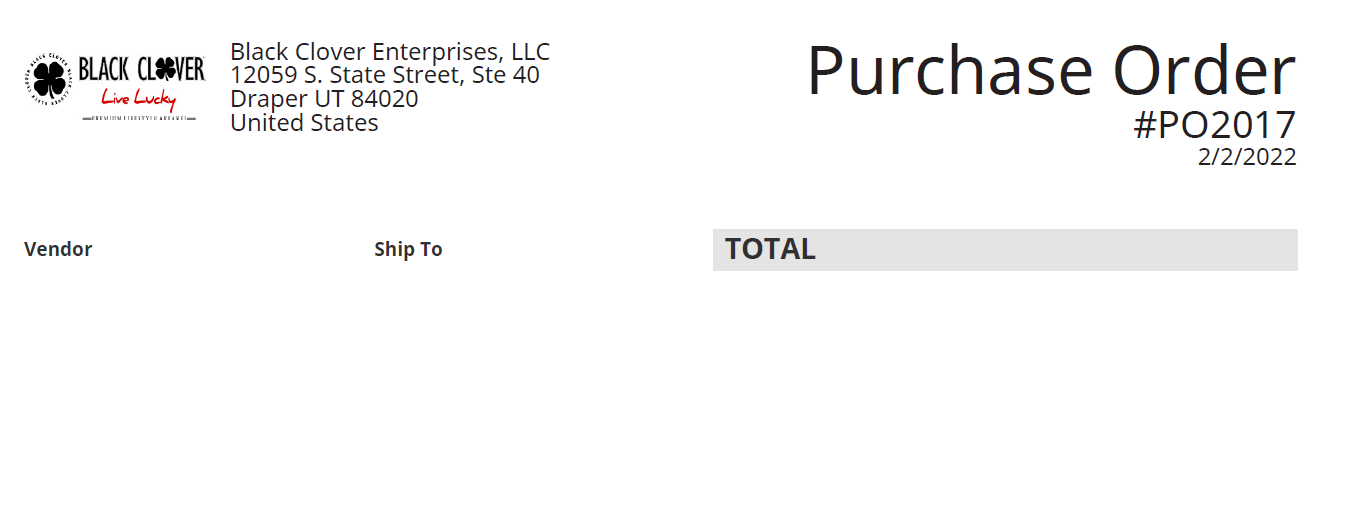
But it seems to be ignoring the header (attached pic) completely,
including the part below.
"Purchase Order
#PO2017
2/2/2022"
Other simple tools have no problem extracting the text from the pdf file.
I think this issue is related to the link below.
"not extracting text from footer"
https://community.adobe.com/t5/document-services-apis-discussions/using-the-extract-not-getting-some...
the only difference is that mine is a header (a little bit long header)
Can anyone help with this?



 3
Replies
3
Replies




 AdChoices
AdChoices
{kind=link}