 Adobe Community
Adobe Community
- Home
- Acrobat SDK
- Discussions
- extraction of TOC details/Splitting PDF as per TOC
- extraction of TOC details/Splitting PDF as per TOC
extraction of TOC details/Splitting PDF as per TOC

Copy link to clipboard
Copied
I have some PDF files and would like to split them into different pdfs as per the TOC given in the file. Using JavaScript, would like to create an action which can read TOC from the pages it is available upto and then split the files as per the TOC.
I am new to JS on acrobat. Any help would be appreciated!!
Thanks,


 8
Replies
8
8
Replies
8

Copy link to clipboard
Copied
There is no "out of the box" solution for this. It will have to be custom-developed to match the structure of the TOC in your files.
I've developed similar scripts in the past and would be happy to take a look at a sample file and let you know if I think it's doable or not, and if so for how much. You can contact me privately (try6767 at gmail.com) to discuss it further.
Copy link to clipboard
Copied
try67: Thanks, will contact you on the given mail id.

Copy link to clipboard
Copied
You should use the Acrobat Pro "Split" feature in an Action (Action Wizard) or in a Custom Command.
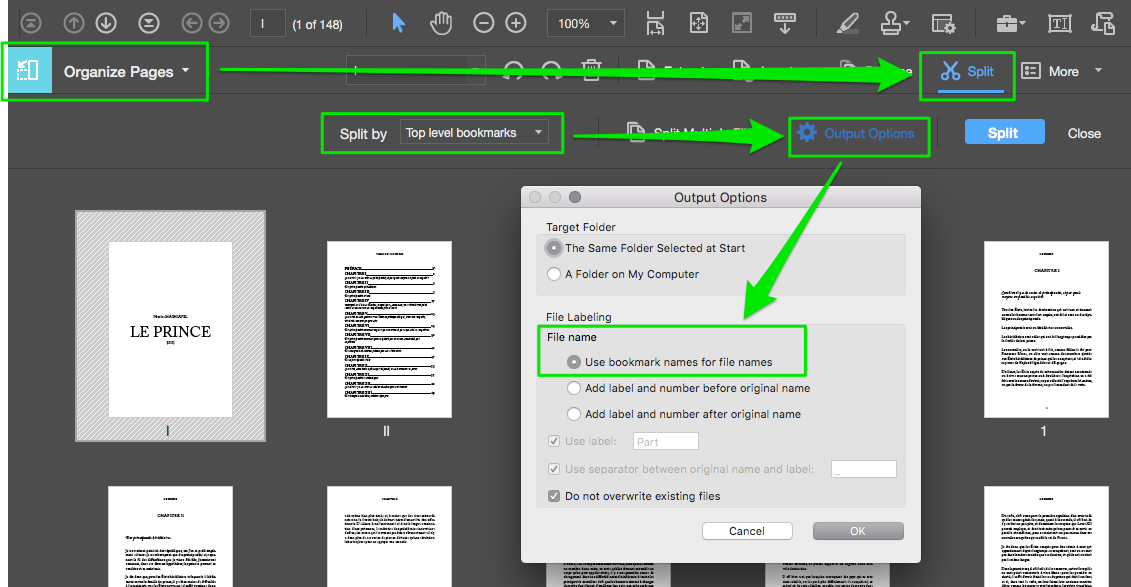

Copy link to clipboard
Copied
This is possible when there are bookmarks in the file.
Copy link to clipboard
Copied
Sorry, I misunderstood the question.


Copy link to clipboard
Copied
I just recently wrote a script that parses the TOC out of a PDF and builds a set of matching bookmarks. In the past I've also written a plug-in, in which part of it's functionality was to find and read a TOC. There were several issues with this process.
- The format/layout of the TOC varies wildly across documents. If you want to do this with JS on your docs, they need to have a very consistent format.
- The TOC starting and ending page numbers need to be known up front. Either the location needs to be consistent, or the user will need enter this data.
- TOC page numbers do not necessarily match real page numbers, and there are often lettered sections such as A1 or ii. If this is the case with your PDFs, then the script will also need to search all the pages for the related anchor numbers.
Message me if you would like some consulting/development on this topic.
Use the Acrobat JavaScript Reference early and often
Copy link to clipboard
Copied
Hello Thom,
The file format is consistent and the start page numbers are written in front of the title ( right hand side of the document) in numeric format. The length of TOC changes though. I have developed a python script which can split the document; however, I need to do it in Acrobat JavaScipt so that the same can be added to the Actions of Acrobat.
Thanks,
Bhoopendra S
Copy link to clipboard
Copied
Well then, all you need to parse the bookmarks and detect the page numbers is the "this.getPageNthWord" and "this.getPageNthWordQuad" functions. These give you the word and the words location on the page. Be warned, words are not necessarily returned in the order they appear on the page. Usually they do, but not always. I always sort the words into lines, and then order the lines.
Here's the SDK reference for the functions:
Use the Acrobat JavaScript Reference early and often
 AdChoices
AdChoices