Question
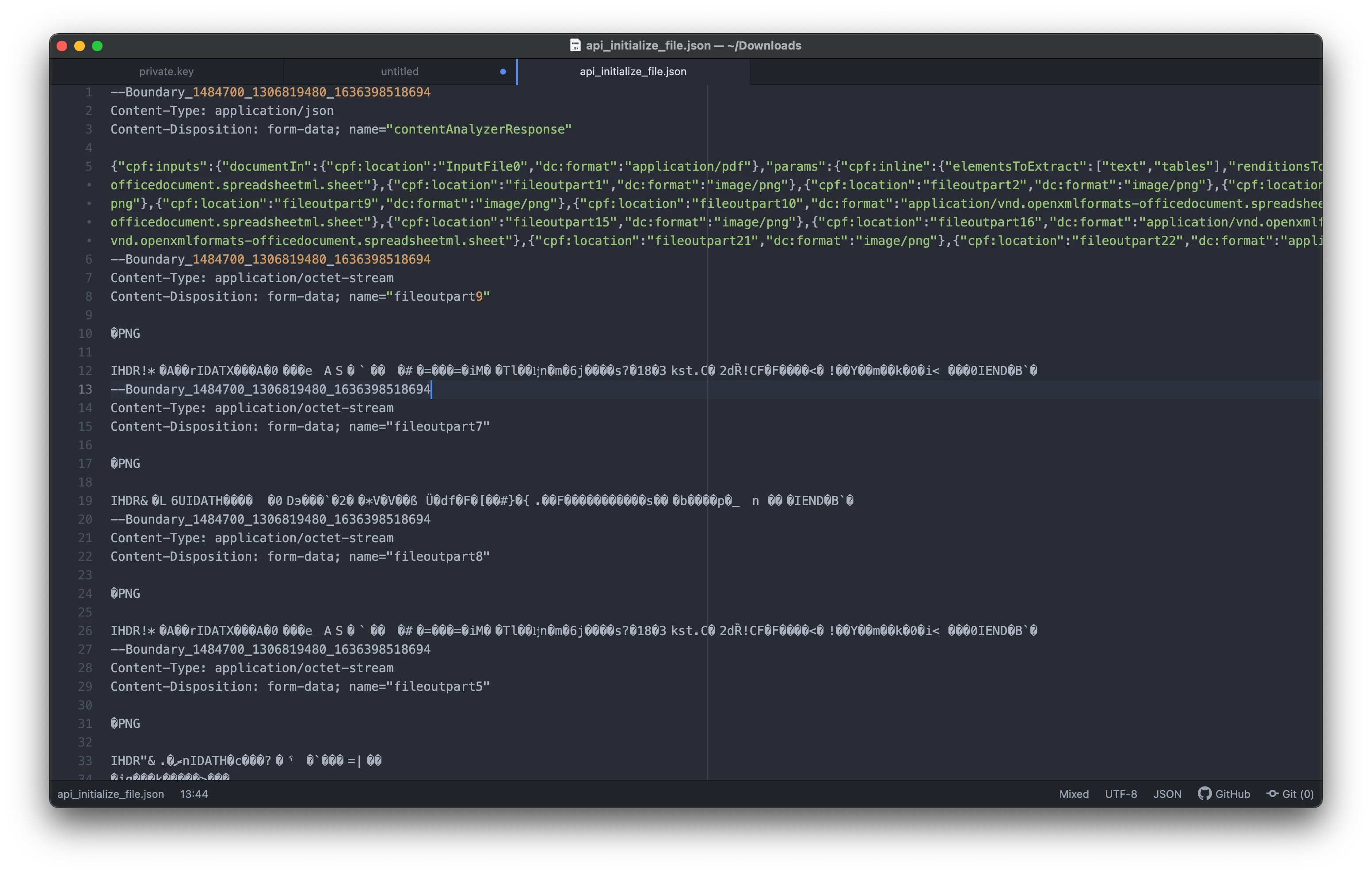
Broken JSON on export
I'm trying to extract data from a PDF using Extract PDF API. I got authorisation, submission and polling working fine. However, polling returns a broken file with a JSON in the midst of it. I'm not sure how to get rid of the broken parts and just return a JSON with the text from the PDF. Has anyone faced an issue like that?
Unfortunately, I can't attach the real file because the forum won't let me.