How to parse JSON output from Adobe Services Extract in Microsoft Power Automate
We are wanting to parse a PDF email attachment, extracting specific text and putting it into a SQL Server database.
I'm using Adobe Services "Extract PDF Structure in JSON File" in a Microsoft Power Automate Flow. The output is outputs('Extract_PDF_Structure_in_a_JSON_File')?['body/jsonFileContent'], which is unreadable. How do I convert that to something I can work with?
Also, I was able to output that to a JSON file. I don't know much about JSON. When I open the file in Notepad++ I see there are four sections, "pages", "extended_metadata", "elements", and "version". I only need the data in the "elements" section, and that section is a JSON array.
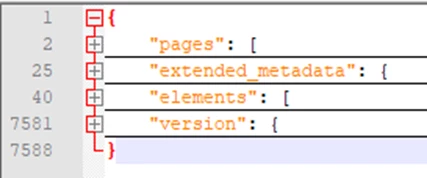
In the "elements" array the fields I need are all called "Text":
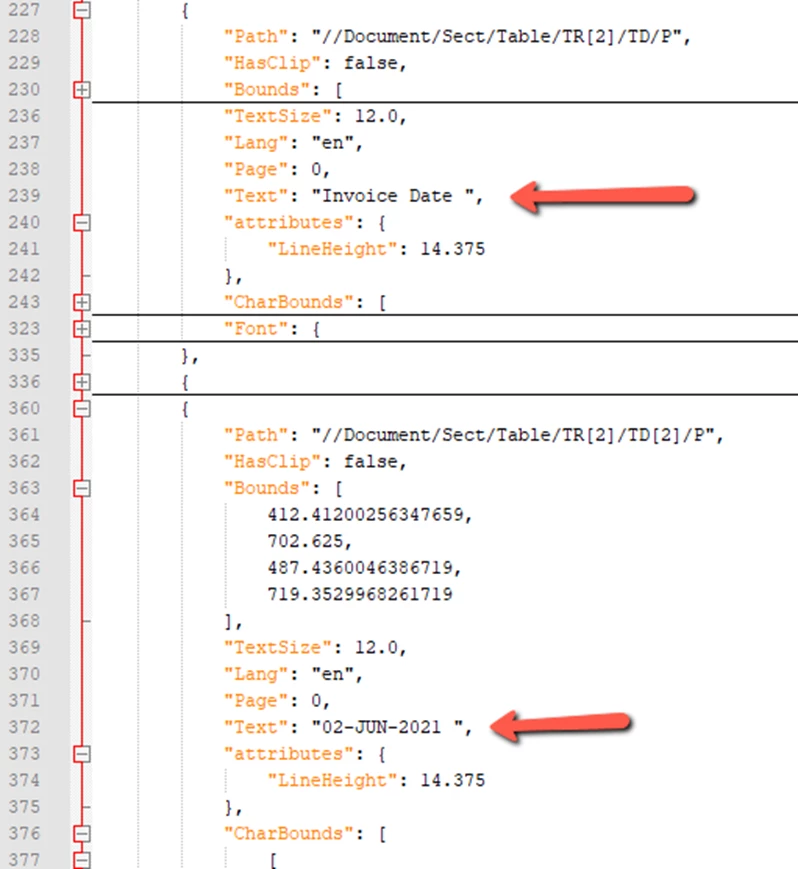
Any suggestions how to get this data so I can put it into a database? Thanks!
Here's my flow:
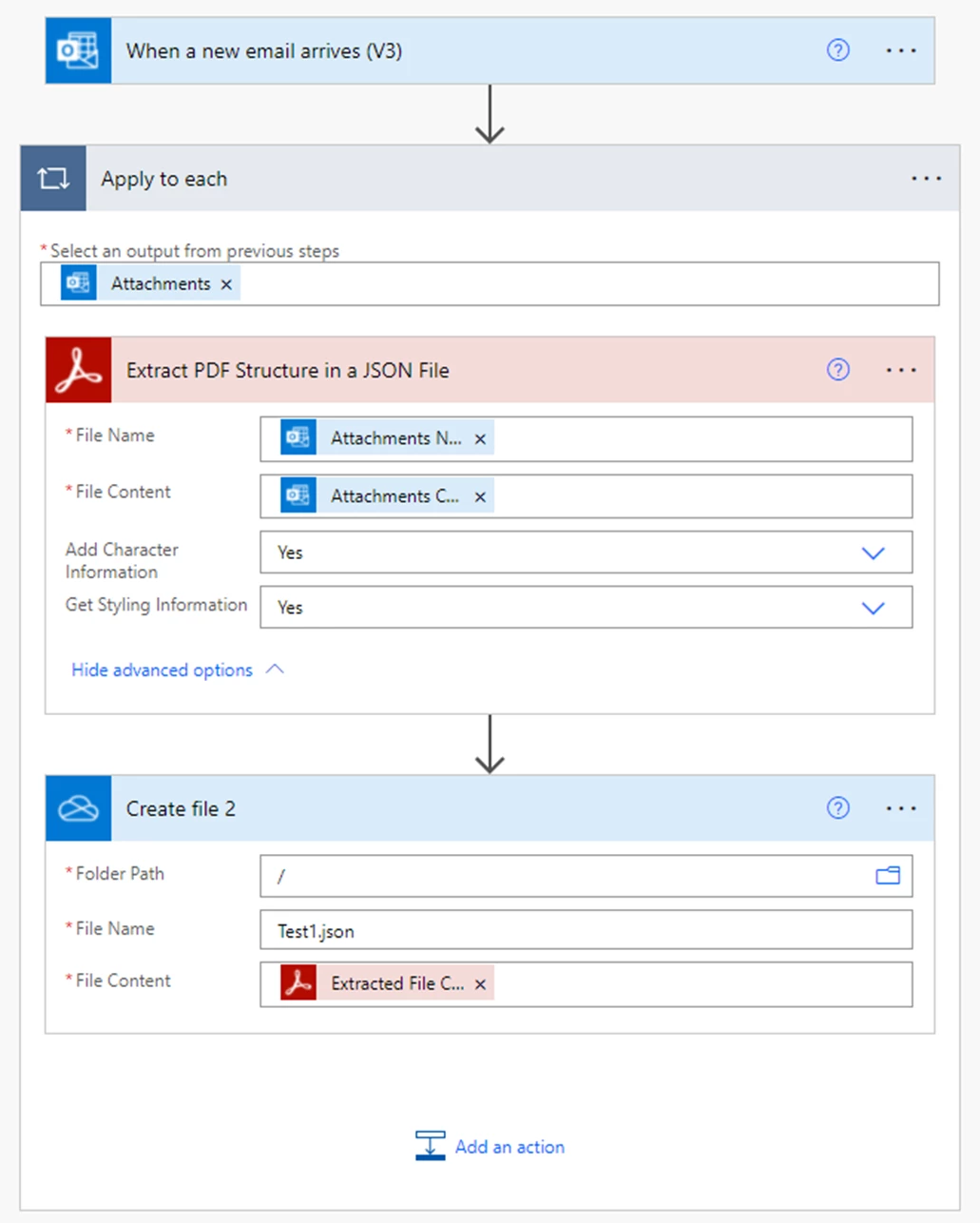
And the run: