

- Home
- Acrobat
- Discussions
- Re: Adobe Acrobat DC is distorting pages
- Re: Adobe Acrobat DC is distorting pages
Adobe Acrobat DC is distorting pages

Copy link to clipboard
Copied
Hello,
I need help; the company I work for uses this program mainly to edit pdfs, but it's been distorting many pages, normally, I'd just redo the work and keep moving, this time the lost was big, this is it did:

I REALLY need a solution for this and I honestly don't know where to look for, I'm already looking into the possibility of using another program because it's been happening way too often.
Grateful,
As of now,
For your attention,
Lucas Jardim Pinheiro


 9
Replies
9
9
Replies
9

Copy link to clipboard
Copied
Hi Lucas,
Wow, I'm not at all certain what's taking place but to help you the following things would be helpful:
What is your operating system (and what build)?
You stated you are using Acrobat DC, I'm assuming that that's the Pro version, what build are you using?
As I look at your sample, I cannot really determine what changed because I do not have a "before" view. Can you please supply that?
And lastly, EXACTLY what are the steps you are taking to get this result.
Thanks,
Copy link to clipboard
Copied
Hi, Gary,
Wow indeed  , here's a screenshot of what the file looked like
, here's a screenshot of what the file looked like
I've been having a lot of small problems with Acrobat not correctly detecting which fonts are been used and/or detecting the images as fonts (and vice-versa), this time it actually disappeared with every character except "o".
I open Adobe Acrobat Pro DC, click on Edit PDF, and start manually translating the file (whilst having some weird Fonts with asterisks next to it whose name have some letters switched), then I move on to the next page (I noticed the program scans per page, so it takes a few seconds) and I proceed to do the same thing while saving in between pages and breaks.
About the OS and Acrobat Version, I'm using Windows 10 Enterprise 2016 LTSB and Adobe Acrobat Pro DC (18.9.20044.251705).
And these are the System Parameters from Adobe Acrobat (which include informations about the computer), unfortunately the Adobe is installed in portuguese, so if there's any relevant information you cannot properly translate, please do question me:
"
Acrobat instalado: C:\Program Files (x86)\Adobe\Acrobat DC\Acrobat\Acrobat.exe
Versão: 18.9.20044.251705
Data da criação:2017/11/04
Hora de criação:17:57:50
Acrobat instalado: C:\Program Files (x86)\Adobe\Acrobat Reader DC\Reader\AcroRd32.exe
Versão: 19.12.20035.332343
Data da criação:2019/06/10
Hora de criação:16:57:56
Aplicativos instalados:
Versão do Office: Office 2016 64-bit
Área de arquivos de página: 4194303 KB
Correio padrão:
Detalhe da conta:
Direitos do usuário: Regular
Controle de conta do usuário: Padrão
Integridade do processo: Média
Tipo de perfil: Nenhum
Detalhe da sessão:
Tipo de inicialização: Normal
está desligando: Não
Rede: Disponível
Dentro do Citrix: Não
Dentro do VMWare: Não
Sessão remota: Não
Controle remoto: Não
Com JAWS: Não
Uso do ZoomText: Não
Com Windows-Eyes: Não
Com NVDA: Não
Detalhe do Acrobat:
Área restrita: Desativar
Leitor cativo: Não
Suporte a vários leitores no desktop: Desativar
Detalhe do Windows:
Tablet: Não
Starter Edition: Não
Media Center Edition: Não
Máquina lenta: Não
Detalhes de vídeo:
Largura da tela: 1920
Altura da tela: 1080
Número de monitores: 2
Número de botões do mouse: 5
Tem roda do mouse: Sim
Tem Pen Windows: Não
Conjunto de caracteres de byte duplo: Não
Tem editor de método de entrada: Sim
Dentro do leitor de tela: Não
Diretório do Windows: C:\Windows
Diretório temporário: C:\Users\0055616\AppData\Local\Temp\
Fabricante do SO: Microsoft Corporation
Fuso horário: Hora oficial do Brasil
Locale: Português (Brasil)
Memória física disponível: 4194303 KB
Memória física total: 4194303 KB
Memória virtual disponível: 3607508 KB
Memória virtual total: 4194176 KB
Monitor:
Nome: Intel(R) UHD Graphics 630
Resolução: 1920 x 1080 x 60
Bits por pixel: 32
Monitor:
Nome: NVIDIA GeForce GTX 1050 Ti
Resolução: 1920 x 1080 x 60
Bits por pixel: 32
Navegador padrão: C:\Program Files\Internet Explorer\iexplore.exe
Versão: 11.00.14393.0 (rs1_release.160715-1616)
Data da criação:2016/07/16
Hora de criação:08:43:06
Nome do sistema: CRLABCONT-301
Nome do SO: Microsoft Windows 10
Nome do usuário: 0055616
Placa gráfica: NVIDIA GeForce GTX 1050 Ti
Versão: 23.21.13.9125
Verificar: Sem suporte
Processador: Intel64 Family 6 Model 158 Stepping 10 GenuineIntel ~3192 Mhz
Versão do BIOS: DELL - 1072009
Versão do SO:10.0.14393
"
Grateful,
As of now,
For your attention,
Lucas Jardim Pinheiro
Copy link to clipboard
Copied
Hi Lucas,
OK, the first thing I did when I saw your new notice was to verify that Acrobat Pro DC does work with Protuguês. Good news (at least for me, you probably already knew that), it does.
OK, the next question(s) I have as to where the original scanned documents come from: Who's doing the scanning and how was it done. What is the resolution the scanning is done at? Are you receiving these as images (e.g., JPG, TIF, etc.) or as PDFs?
Have you received other PDFs from this source (even you) that have worked in the past? What changes might have occurred since there were successful OCR operation (e.g., updates to OS, updates to Acrobat Pro DC, updates to your scanning software, change in scanner?
I have to leave in a few minutes and will not return until some 4 hours or so. So if you do not get an immediate response, sorry.
Good luck,
Copy link to clipboard
Copied
Hi Gary,
So, first, I'd like to say that I'm already impressed with the speed you've been replying, so no worries about that, I'll actually have some other appointments now and won't be able to respond for a while aswell, so take your time.
I receive the files as PDFs through the company's branch in Brazil and as far as I know the company receives the PDFs (not sure if scanned or not) throught the branch in the United States; I can check with them about the origin of the PDF, if you claim to be important.
If you don't mind me asking, is this uncommon? Because I've been having this and similar problems with nearly every PDF they've sent. And I must admit this is the first time I work with translation through Adobe Acrobat Pro DC; I've used PDF Expert, Adobe Photoshop and Adobe Premiere (to embed some subtitles), in other translation tasks.
Lastly, could this be caused by low-quality PDFs? Could there be a recurring distorting of the words due to the program having constant difficulties in reading the text? Because I've noticed that the more I use the OCR the worst the quality of these words become like it's applying some Bold Print-Like texture on top of the words over and over;
Grateful,
As of now,
For your attention,
Lucas Jardim Pinheiro
Copy link to clipboard
Copied
I Lucas,
Wait, are you doing OCR AND trying to translate at the same time? Acrobat cannot translate so if you were trying to do that, how??
Meanwhile, yes, the quality of the scan can make a tremendous difference in the quality of the result. f
A lot of the problems/issues typically revolve around both the size of the text and the resolution of the text. So, a size 18 font will have more success than a size 9 font. In addition, if the document was scanned at 300 ppi, it will have less issues than if it was scanned at 150 ppi. Ideally 600 ppi is best.
The why of this is how clearly Acrobat (or any OCR software) can distinguish edges. One common example of error is when you have a letter combination such as "ri." If the font is too small and/or if the resolution is too low, the OCR software might see that as "n."
However, I gather that the documents are coming into you only as a PDF that has not been OCRed, correct? I would be curious as to what kind of scanner was used and what kind of software converted the scan into a PDF. I'm not all that certain that that will have much of an issue here but I am curious.
Now one other area of potential issue is what setting are you using to do the OCR.
If you go into "Enhance Scans" there is the option to Recognize Text. When you select that, you will see a gear to set your settings.
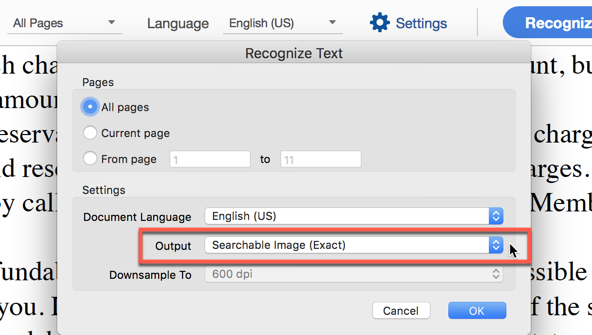
Note the 2nd dropdown menu, there are three options:

Because I do not know the history of your documents, take one page and try each of these options and see what you get. (total of three results).
Let me know what you end up with.
Copy link to clipboard
Copied
Hi Gary,
I've been using the Edit PDF (As illustrated by Image 1) Function to detect the text; as for the translation, I've been doing it manually, re-typing the documents.
I've asked the client about the possibility of better quality scanning and he say he'd see into that and the error ocurred now with another file (as illustrated by Image 2) , it detected most of the letters as being individual images which is taking me a longer time to translate and adjust.
I also did not have a lot of time to look into it but I (quickly looked into it and) did not find the Recongnize Text window that you showed, I'll look more into it tomorrow but if you have any more instructions on how to get to this window in the first place (and beat me to it), please do enlighten me.
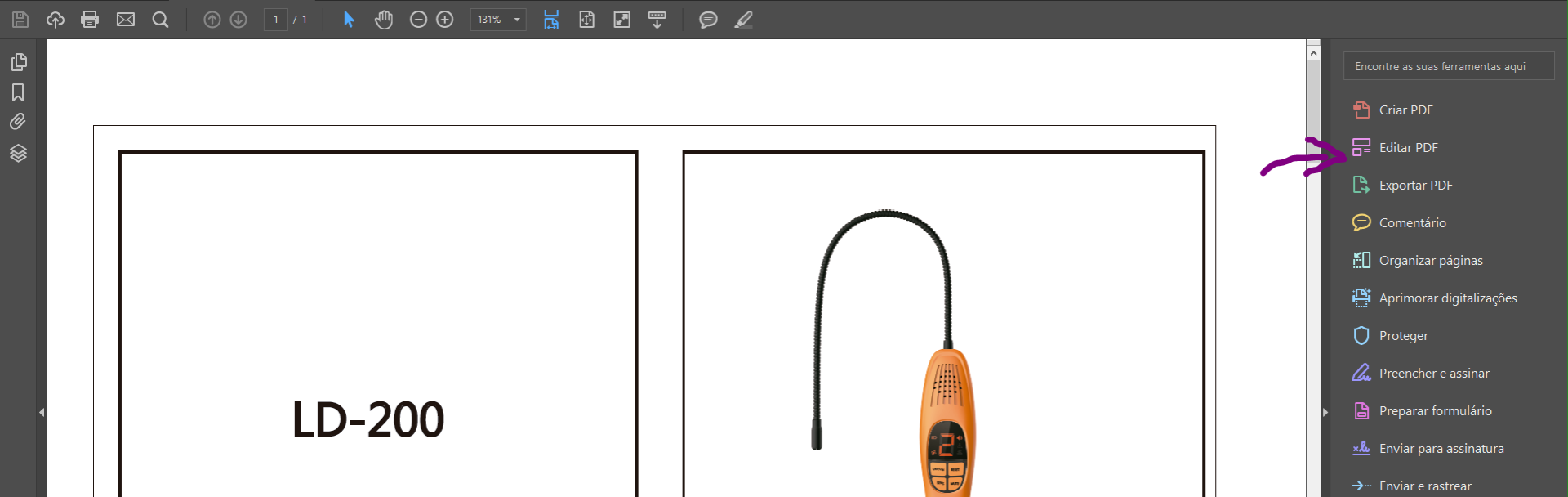
Image 1

Image 2
Grateful,
As of now,
For your attention,
Lucas Jardim Pinheiro
Copy link to clipboard
Copied
Hi Lucas,
OK, a number of issues here.
One of the Tools is Enhance Scans. If it's already on the right hand side it'l look like this:

If you have to go into the Tools window, it looks like this:
If you want it on the right hand side, just drag it there. Done!
This is the Tool you want to use to do the OCR-ing. It is from there you'll find the selection of ways to do things that I showed above. I do want you to test each of them to determine which gives you the best results. Since I do not know the origin of the original PDFs, I'd really suggest trying all three and you decide which gives you the best result.
The "fat" "els" (L) is a bug I haven't seen in years (seen in image 2). Let's see if working from the Enhance Tool and selecting a better process solves your other problems and this before we worry about this one for right now.
Let us know,
Copy link to clipboard
Copied
Hi Gary,
I tried to enhance scans with all the options but nothing seemed to change in the second and third option, the message (illustrated by Image 1) happened and a while later the pages turned black and what it was already understanding as text turned white (it still didn't recognize any new text); the first option was really fast and had no change whatsoever.
I've asked the client about the PDFs source and am waiting for his answer.
You mentioned you haven't seen this bug in years, do you recall why it used to happen in the first place? And also, would it be helpful if you could have access to one of the PDFs I'm working on? Maybe analysing it could help us figure this out quicker
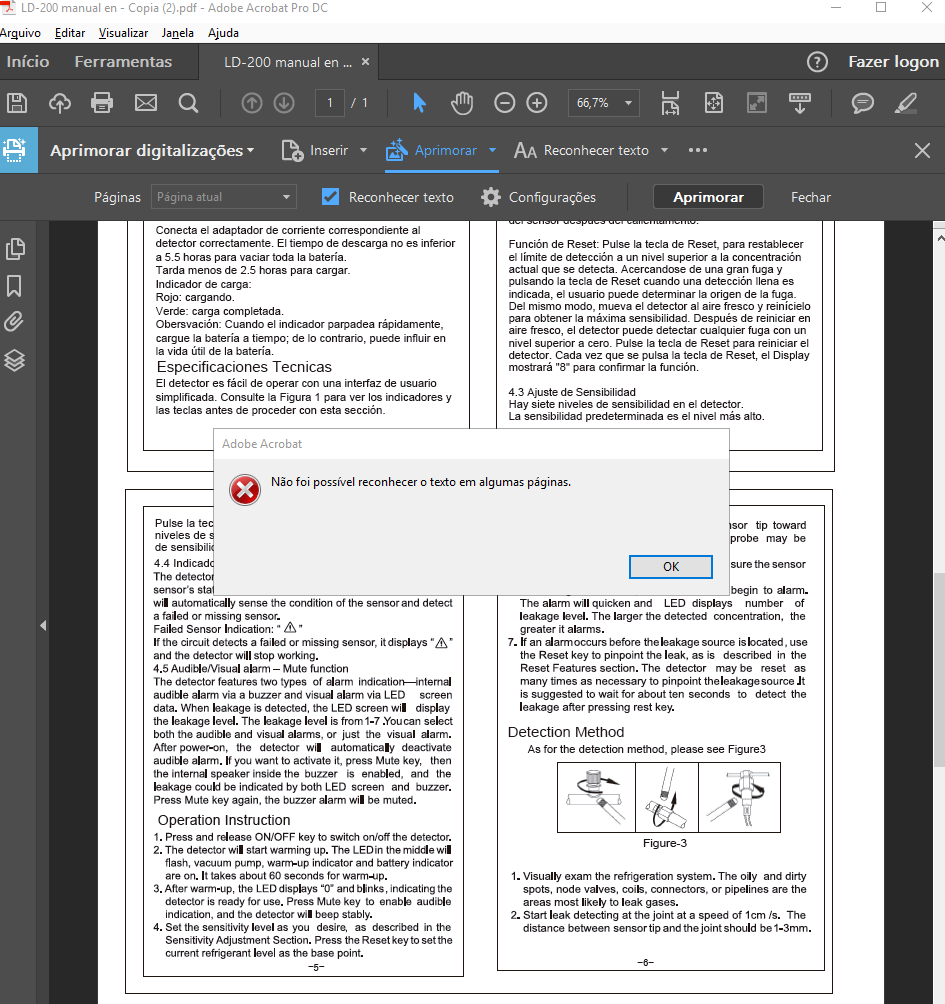
Image 1
Grateful,
As of now,
For your attention
Lucas Jardim Pinheiro
Copy link to clipboard
Copied
Hey Gary,
I just had the same error again (as illustrated by Image 1), I was manually translating these PDFs through the Edit Page feature and as I was editing the text box above (in page 6) and the text box in page 7 just turned white, I tried to change the font, color, size but nothing works, I managed to save the text to a Notepad and it is still there, it just doesn't show, I'll redo it but I would like to know if this could be related to the other bugs I've been experiencing.
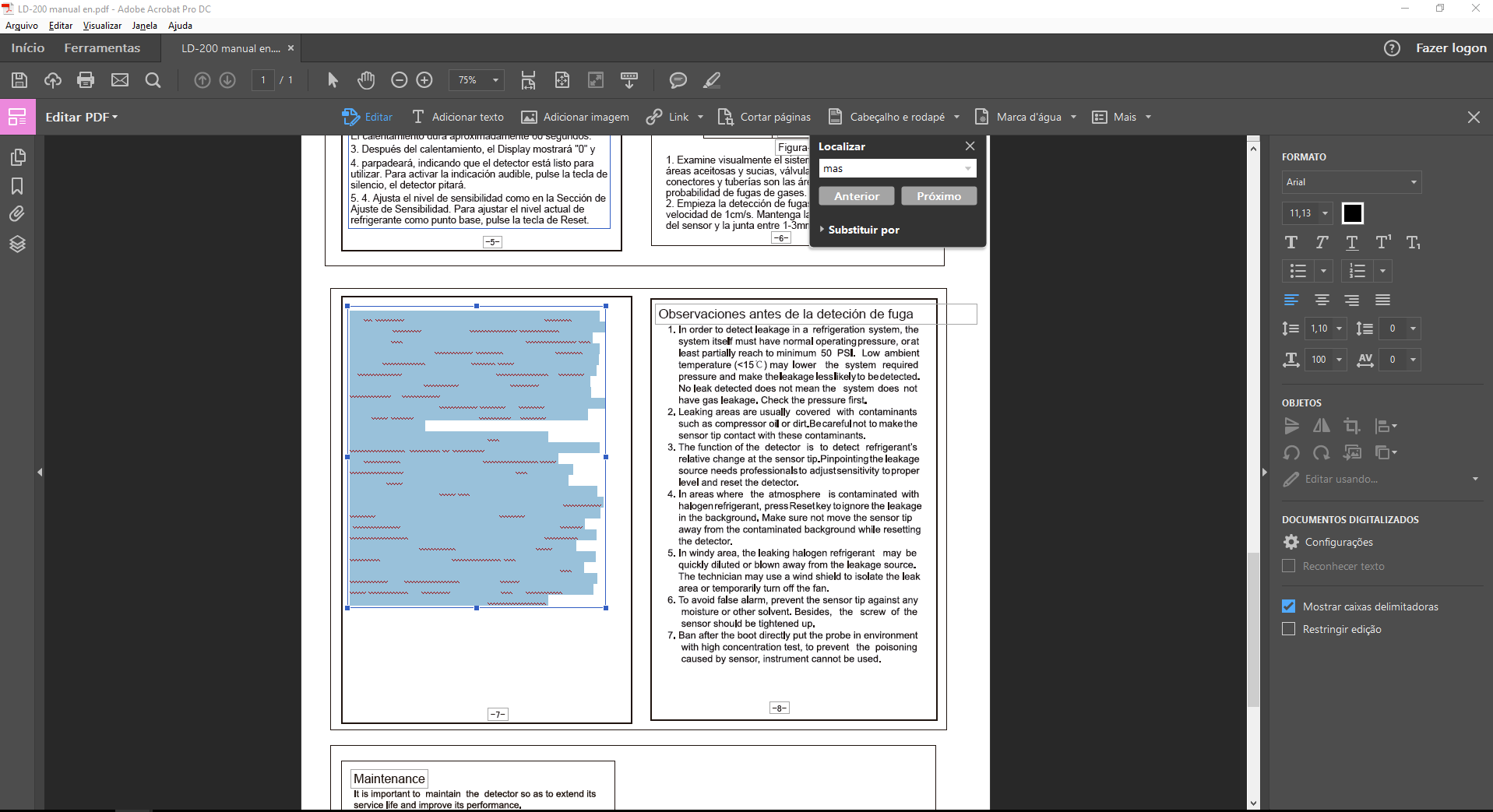
Image 1
Grateful,
As of now,
For your attention
Lucas Jardim Pinheiro

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices