 Adobe Community
Adobe Community
- Home
- Acrobat
- Discussions
- Re: # ist replaced by %23 in URLs ==> Error 404
- Re: # ist replaced by %23 in URLs ==> Error 404

Copy link to clipboard
Copied
URLs (Links) do not work in my PDFs (from Word Documents), because # ist replaced by %23, which results to an Error 404 in Browsers. Is there a workaround for this bug in Adobe Acrobat XI Standard?


 1 Correct answer
1 Correct answer

Hi, I've come across a simple workaround which is ideal for me — double high five. I Simply bitlyed (https://bitly.com) the link and that ugly error message vanished. Boom.
 61
Replies
61
61
Replies
61

Copy link to clipboard
Copied
I am having exactly the same problem with # being replaced with %23 and links not working (MS Word 2013, Acrobat XI Pro 11.0.11, Win 8.1). Why has this problem not been fixed?
Copy link to clipboard
Copied
Well version 11.0.12 is now out and still no fix. Sigh. 
Copy link to clipboard
Copied
Hi, I've come across a simple workaround which is ideal for me — double high five. I Simply bitlyed (https://bitly.com) the link and that ugly error message vanished. Boom.

Copy link to clipboard
Copied
Yeah, that's a good idea Claire. I used Google's URL shortener since we already use that in a couple of places. Not an optimal solution, but it will work for now. I would still like to hear Adobe's plans to fix this. It doesn't look very professional having the shortened links in there, plus it obscures the location when the user hovers over the link. That's both irritating, and a potential security risk from an end user standpoint, since they don't know where the link will take them.
Copy link to clipboard
Copied
True, it's more a workaround rather than a fix.

Copy link to clipboard
Copied
I had this same issue (except with dashes in the URL) and this post saved me. As clairecessford mentioned, this is a workaround and not a fix. Please fix this Adobe and it's easier to Print as PDF instead of going through the Save As process.Given the date on the original post, this issue has been around for awhile now. And I'm running on the latest CC version so I know it's still a problem.

Copy link to clipboard
Copied
I disagree that this issue has been "answered" by suggesting we create bit.ly links for every instance in a PDF where we're linking to URLs that include anchor tags.
It's clearly an Acrobat/Office bug (we're on Office 2013 and latest Acrobat version). When I create a link in a Word doc like "http://yadda.com/document#anchorname", it should use that exact link when it converts to PDF, not translate the hashtag to %23 which works in some environments and not in others. I see that this thread is over 18 months old, but the problem shouldn't be marked as "Answered" by suggesting a manual work-around with the bit.ly suggestion. (Fine suggestion if there's just one link, not acceptable if there are dozens.)

Copy link to clipboard
Copied
Actually what it is, is you are name the file withal space and and a space encodes %23 which no wen browser accepts. What you have to do is rename the files you want to upload to either not use spaces. Or use underscores like on a PC instead of spaces.
Copy link to clipboard
Copied
Spaces aren't the issue in this case, it's Word/Acrobat converting (web-encoding) the # sign as %23, which in many web server configurations results in a 404 error. We follow the W3C guidelines for naming files/URLs, but it's Acrobat (or Office, hard to tell) that's causing the issue by not just leaving # anchor tags as-is when converting to PDF.
We use IIS7 and I've created a rewrite rule to handle the problem (see my stackoverflow comment) which works fine, but would still be nice if Acrobat would leave URLs exactly as authors create them. My opinion: Acrobat is trying to help the user by encoding links to ensure they're web-safe, but they should pull back a bit and allow W3C-accepted characters in URLs to come through as-is.

Copy link to clipboard
Copied
My memory is a little hazy, but I think the issue was related to auto-recognized urls. If you create a specific url link, the problem goes away. You can determine if this is an auto recognized url issue by turnning of the auto-recogonize urls in the preferences.
Copy link to clipboard
Copied
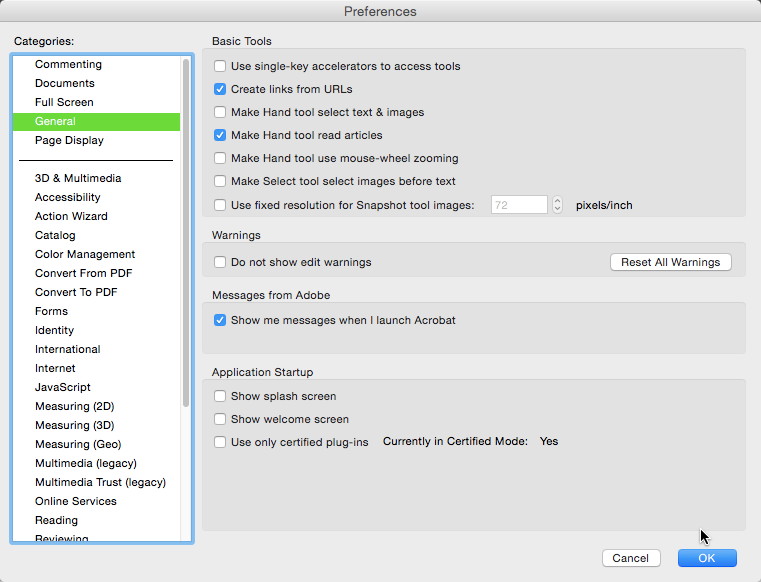
Uncheck the 2nd checkbox.

Copy link to clipboard
Copied
This is a bug that needs to be fixed. The bitly workaround is not acceptable for the reasons detailed by ArmandFrvr.

Copy link to clipboard
Copied
Hi
Please check with latest Acrobat version if you are using Acrobat 11 or Acrobat DC - Continuous and then let us know if the issue persists.
Thanks
Tanvi
Copy link to clipboard
Copied
Problem seems to be fixed (finally) with the latest update to Acrobat 11 (11.0.13).
Note: I only had time for a quick check.

Copy link to clipboard
Copied
This is NOT FIXED in Adobe Acrobat Pro DC with this version info:
Architecture: x86_64
Build: 19.21.20061.361316
AGM: 4.30.98
CoolType: 5.14.5
JP2K: 1.2.2.44947
Very easy to reproduce - create a PDF and select the text you want to hyperlink to and then right click that text and chose Create Link (then choose Open a web page radio button in the pop-up then click Next) and enter a URL that has a # in it (i.e. https://www.w3.org/WAI/tutorials/page-structure/headings/#main-heading-before-navigation).
Save the PDF and click that link and see that your browser is trying to go to this:
https://www.w3.org/WAI/tutorials/page-structure/headings/%23main-heading-before-navigation
see the # has become a %23 and this results in a 404 not found error page.
This is a bug that Adobe should fix as was stated by user 'Michael_E_Murphy' several years ago.

Copy link to clipboard
Copied
Since this bug still hasn't been fixed 5 years later, I found a solution to fix the incoming links on Apache web servers using mod_rewrite. Unfortunately this won't help if the PDF links to a website you don't own.
If you have access to an .htaccess file on your website you can try to detect the %23 and rewrite it to # automatically, rather than creating a manual redirect for every link. It's tricky because the %23 in the incoming REQUEST_URI is automatically decoded to # (so you have to actually look for # instead of %23), and then doubly tricky because the # in the destination url you redirect to is automatically re-encoded back to %23. You must use a noescape [NE] flag on your redirect to prevent the re-encoding and avoid an infinite loop. The good news is that Apache will only ever match %23, and never a literal # because the client-side anchor is stripped off before creating the server variables. So even though this pattern looks for #, you'll only find it for urls that contain %23 (such as the Adobe bug).
This worked for me but may be a little different for your needs (such as if done via VHOST instead of .htaccess):
RewriteEngine on
RewriteBase /
RewriteRule ^(.*)\#([^/]*)$ $1\#$2 [R=301,NE,L]
This pattern matches a link that ends with an anchor that has been converted into %23 (even though it matches a literal #) and redirects it to itself, while adding the noescape [NE] flag. This will not lead to an infinite loop of redirects, because once the # is written without %-encoding the anchor will no longer be visible to Apache after the first redirect. This should not affect any query strings because they are not matched by the RewriteRule pattern. If you want to automatically fix links containing both a query string and an anchor, you will need a more complicated solution involving a RewriteCond (because the %23 anchor then becomes part of the query string instead of part of the url path).
Disclaimer: If you're not familiar with mod_rewrite, be careful, it can easily break your website.

Copy link to clipboard
Copied
Hey guys, i believe, that can be frustrating.
But, i found ellegant workaround for this.
All what You need to do, is changing type of link.
Do not going for web url link, but for "run javascript"
After that, you can place there
app.launchURL("https://www.yourdomainWith#.com", true);
It work correctly.
Copy link to clipboard
Copied
This worked for me! Unbelievable this is still a bug in 2020.
Here's a step-by-step of MSzotkovski's directions in case anyone needs it:
- Open the problem Acrobat file
- Click on "Edit PDF" in the toolbar at right
- Click on "Link" at the top toolbar and select "Add/edit web or document link"
- Double-click on the existing problem link
- In the "Link Properties" dialog box, switch to the "Actions" pane
- Click on the "Open a web link" action in the "Actions" section and delete it so the Actions box is blank
- Under "Add an action," select "Run a JavaScript" from the dropdown box. This will launch a new dialog box.
- In the new box, type:
app.launchURL("https://www.yourdomainWith#.com", true);
- with the sample URL replaced with your URL with special characters
- Click "OK"
- In the Link Properties dialog box, you should now have a JavaScript action
- Click "OK" again
The URL should now launch correctly.
It's not really solving the root problem (improper decoding of special characters on Acrobat's end), but it's a reasonable workaround for small quantities of URLs.

Copy link to clipboard
Copied
Hey vresri, I apologize with my post. I just realized you guys posted the solution after I clicked on my reply button.
At least this shows that more people are noticing the same problem and we're getting somewhere.
Copy link to clipboard
Copied
Hi everybody!
I'm sorry to break the cheerful mood and be the actual party-pooper that is about to ruin the partially fructiferous pseudo-victory here.
I don't know how you're able to get over 18K views by suggesting a third-party solution in the Adobe community support forums.
I am 100% positive that if it was me who posted that link here, a lineup of MVP's and ACP's would've jump already to tell me that I can't do that, and 12 months later I would still be wondering why does my answer was never marked as a correct solution.
This problem has nothing to do with a particular operating system platform; I confirmed that it happens using any version of MS Windows 7 through MS Windows 10.
So it is most likely that a bug was introduced via recent updates of Acrobat Pro DC or no-one has ever cared to look into this since 2012...
Anyway, according to another user that I was helping out yesterday, the problem doesn't manifest with Acrobat DC 2017.
The person had uninstalled Acrobat Pro DC as a "band-aid" remedy (I quote). Moreover, in an environment where a user has to process thousands of documents with URL web links, bytly.com imposes a cap to a maximum limit of URLs that a user is able to fix using their service.
Here is my post to that person 3 hours ago before I posted in this thread:
When you reach that limit you have to subscribe and pay; this is not a convenient solution for mass production of PDFs with weblinks. So, I am going to post here the real work around using very basic javascripting ( I am just learning JavaScript by the way).
If this problem is indeed a bug, when you use the Create Web Link wizard from the "Edit Tool" it seems as if something is not converting the hash or pund symbol appropriately to the corresponding Unicode symbol .
If that is the case it is likely that the symbol is not available in the current font or typeface that is currently used by the JavaScript editor or by the PDF document in general.
- NOTE: you also get this symbol by pressing the ALT key in your keyboard and typing the digits 3 and 5 on the numeric keypad, for example ( ALT+35).
So lets us take a look at the slides below:
- If you use the regular Create Web Link wizard from the "Edit Tool"


- After you enter the URL with an page opening parameter this is what you get:

If you refer to a Unicode table, look for the ASCII punctuation and symbol symbol section for " # " (without the quotes" ) you will notice U+0023 <<<---------- SEE THE RELATIONSHIP WITH THE %23 NOW???
See a lot more here:
- Unless I missed a Preference setting in Acrobat and until someone in Adobe can confirm if this is indeed a Unicode-related bug, I will safely assume that this is related to the typeface used in the JavaScript editor (shown below in the next slide))
- However, When you try to change %23 back to a pund (#) sign and you highlight it and right-click on it, notice all of the interesting Unicode options that are available through this context menu.... See slide below and ask yourselves Why is this here if this is NOT related to Unicode?
- You can try yourself and see if messing with any of those resolve the issue. But I've spent about 6 hour or more researching and playing around with this.

As you can see, this problem has nothing to do with web servers, plug-ins, MS Office add-ins, browser add-ons, macros, Active X control in Windows, and what not.
This is most likely a bug like I've suggested earlier, and I am mostly inclined to think it is between HTML and the JavaScript UTF types that are involved in this web linking process with Acrobat (but I may be wrong).
However, the best workaround at this time is to use a javascript script instead of using the "Open a web link" method.
See the additional set of slides that I prepared and use this other method instead:

- Insert this line of code with your desired URL and its opening parameters using the exacct syntax in the example below:
// YOU CAN USE THIS EXAMPLE URL TO TEST AND SEE FOR YOURSELF IF IT WORKS
app.launchURL("http://www.adobe.com#page=3");
- Paste in the JavaScript editor as shown in the dialogue box to the right of the image below



IT WORKS!
Copy link to clipboard
Copied
++++++COMPLETELY EDITED REPLY : TOO MANY TYPOS, BAD GRAMMAR, POORLY ORGANIZED CONTENT.
If you've used the Weblink plug-in that is found in the "Edit PDF" tool it won't work.
It seems like (just saying, it seems like ) this is a bug. When you used this weblink tool it generates simple URLs out of the text string that you input but it fails to treat this field as an annotation. That is why you can't work around it.
If it was treated as an annotation you would be able to manually edit its tag propperties and even its container attributes.
To work around this, don't use the weblink plug-in to generate URI actions. Instead, follow the recommendations I posted for another user here:
- Links work perfectly fine if you decide to use a javascript action to createlinks or to open URLS
- Links also work perfectly if you just go to EDIT -->>> PREFERENCES---->>> GENERAL --->>> check the tickbox "Create Links from URLs" and then just right-click on the document and select from the context menu "Edit Text & Images" (OR , opening the "Edit PDF Tool") ---> select "Add Text" and type in the desired URL with its opening parameters in just plain text.
- NOTE 1 : You can also use copy and paste the URL text string from a file text editor such as Notepad and paste it in the text box. (DO NOT copy from MS Word or Wordpad , they both will convert the text string to a hyperlink automatically; this is what we're trying to avoid). This method won't work when you copy a hyperlinks that are already encoded as Text/HTML and paste it in the text box in Acrobat; it will create the same issue because it trigger to use the problematic weblink creation tool in Acrobat.
- NOTE 2: When you're done adding your URLs to your document, SAVE and close it . Reopening your document in Acrobat will apply the conversion to hyperlinks automatically and most importantly, if your URI action includes a speacial character that is used as a PDF opening parameter it will open successfully in your web browser without the incorrect %23 encoding (or similar).
- NOTE 3: Using an mouse up javacsript action in a button or through the Action Wizard also works. Below is the script that will (and I quote) "Scans the specified pages looking for instances of text with an http: scheme and
converts them into links with URL actions." from page 141 of the Acrobat JavaScript Scripting Reference - Doc Methods, addWeblinks
var numWeblinks = this.addWeblinks();
console.println("There were " + numWeblinks +
" instances of text that looked like a web address,"
+" and converted as such.");
Using the methods that I described in the bullets and notes above work, and more importantly, you will be able to see those hyperlinks treated as annotations in Acrobat too.
Last thoughts, Bytly.com is not the appropriate workaround nor the solution to this problem. Hyperlinks that are created in Adobe Acrobat Pro from a text string work perfectly fine and the encoding and decoding from text string to UTF-8 also works perfectly.
Just make sure not to continue to use the Weblink plug-in and let Adobe look into this and fix it.
Copy link to clipboard
Copied
Hi everyone!
Today Adobe pushed out a new optional update that finally addresses this issue.
Apply this last update and see how your Acrobat behaves.
Copy link to clipboard
Copied
THANK YOU ADOBE!!!
this issue has been fixed with the last update to version:
2020.009.20067

Copy link to clipboard
Copied
I have the same issue on my Mac Pro Catalina. It's not a server issue, the "#" is replaced with a %23 and it takes you to a 404 web page on any browser or computer. This is a glitch I hope will be addressed. In the meantime, making a bitly link is a simple, but genius workaround.

Copy link to clipboard
Copied
Did you apply all updates?

 AdChoices
AdChoices