
Possible Memory Leak - ColdFusion 2023 + Java 17.0.12
Ever since we upgraded from ColdFusion 2021 to ColdFusion 2023 we have been dealing with out of memory issues. ColdFusion will run fine for roughly 24-30 hours, then we will start seeing CPU spikes to 100% every 30 seconds. Garbage collection can't free up enough memory so ColdFusion eventually crashes and we have to restart the server.
Things we have tried that don't seem to help:
- Downgrading to 17.0.11
- Tweaking the min and max heap sizes
- Tweaking the caching settings
- Changing the garbage collector algorithm to G1GC
- Tweaking our websites to cache queries for a shorter period of time (1 hour down to 15 minutes down to 5 minutes)
Here are our current settings:
Min Heap: 8192
Max Heap: 8192
Garbage Collector: UseParallelGC
Cached Templates: 1000
Cached Queries: 5000
We do have Fusion Reactor installed on all of our servers but this is like trying to find a needle in a haystack. I really don't know what I should be looking at.
Here is a most recent screenshot from 2 days ago that shows the ventual demise on one of our servers.
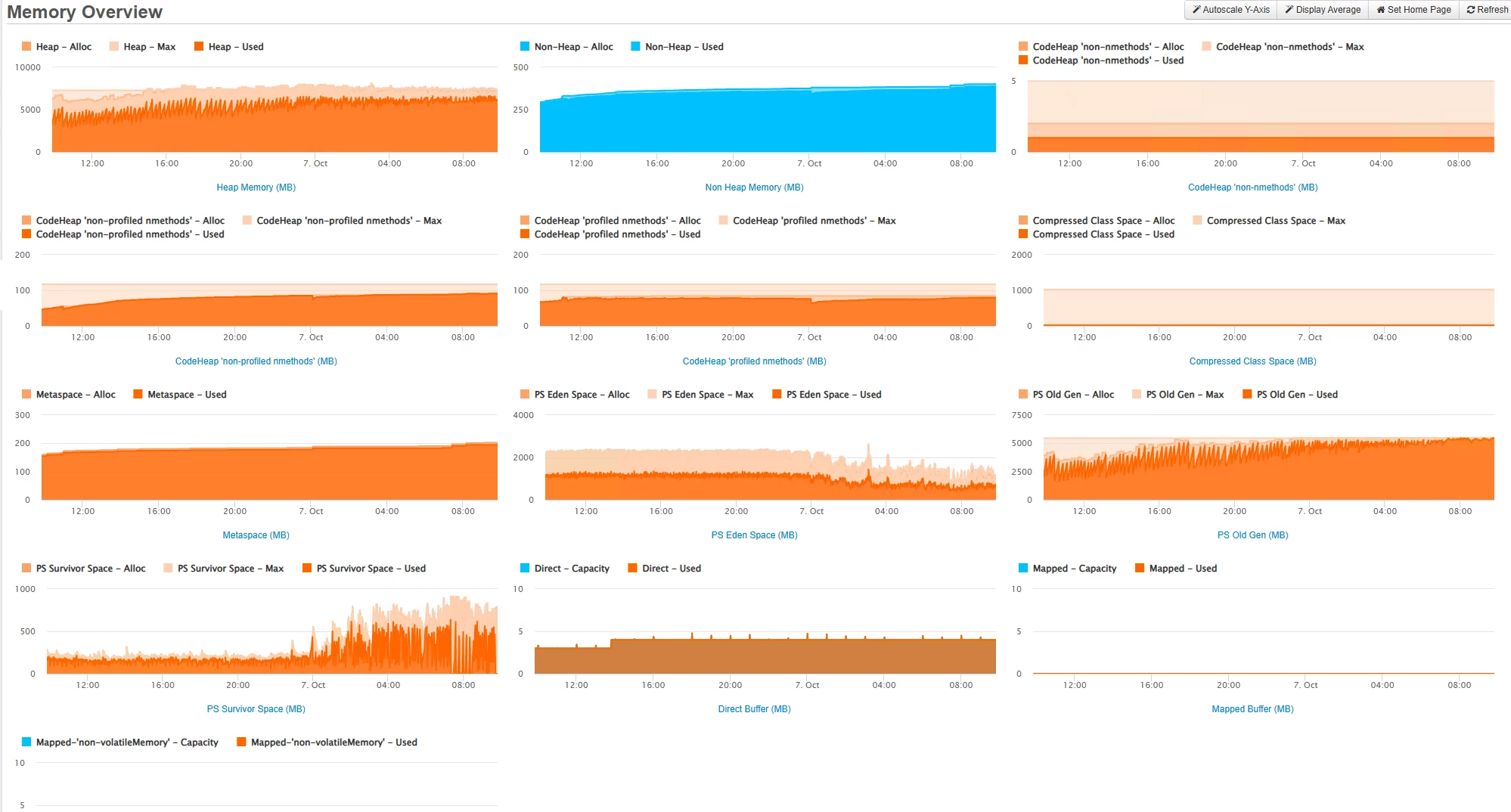
I am really at my wit's end here. If this isn't a memory leak I don't know what the heck it is. If anyone has any recommendations on what to try next I would appreciate it.
