


Copy link to clipboard
Copied
A couple weeks ago we began noticing weird character suddenly appearing the From field of some emails, this after Update 8 for CF2016 had been applied. I rolled back to Update 7 and was able to see the accented character correctly again. I applied Update 9 this morning, thinking maybe it would address the issue but no luck. Hoping now someone on here may have the answer.
Local CF 2016, Update 9 running on a Windows 10 using CF's built-in server (no IIS or Apache)
Page encoding is set to utf-8 and I've tried it with and without the charset set in the cfmail tag as shown below.
<cfset FromField = """#GetPoster.FirstName# #GetPoster.LastName#"" <support@*****.com>">
<cfmail to="#ToField#"
from="#FromField#"
subject="HelpDesk - Request #SRNr#"
charset="utf-8">
With update 9 installed (as well as 8) the From field appears to mess up the character encoding but not that within the email body text
When rolled back to Update 7 everything displays okay

Thanks in advance


 1 Correct answer
1 Correct answer
It's an official new bug. I've been using ASCII characters since CF 6 and only just now stopped working in CF2016u8 & 9.
Here's the bug I reported. Adobe responded within 24 hours and indicated that the bug will be fixed in an upcoming Hotfix 10 release.
https://tracker.adobe.com/#/view/CF-4204050
Until then, I've overcome this issue by adding a UDF+JAR that converts unicode to ASCII7. I added this workaround that I'm using to the bug report.
To sanitize non-ASCII7 characters from a text string, th
... 11
Replies
11
11
Replies
11

Copy link to clipboard
Copied
I don't use CF2016, however I did discover an odd glitch in CF11 that could be related.
Whenever I would use CFMAIL and either the TO or FROM value included quotation marks (like around a person's actual name, as you are doing), CFMAIL would force everything to lower case.
So "USTC WebMaster" webmaster@myDomain.com would become "ustc webmaster" webmaster@myDomain.com.
Unless there is a reason that your mail server requires names to be contained within quotation marks, try removing the quotation marks to see if that makes any changes. Just as a workaround until Adobe fixes this issue.
HTH,
^ _ ^
Copy link to clipboard
Copied
WolfShade We've never encountered this issue regarding quotation marks. We continue to use them in every outgoing CFMail message and it's never lowercased the text... until the bug in CF2016u8/9 when unicode characters are also present.
Are you sure you are using CHR(34) and not "smart quotes"?
Copy link to clipboard
Copied
I'm using the SHIFT+' direct entry method of putting quotes in.
<cfmail blah blah blah from="""WebAdmin"" <webadmin@mydomain.com>" blah></cfmail>
I don't use (or advise using) any Microsoft Word/Excel/whatever for any kind of inputting or copy/paste, although we do have a CMS (built for another department) that a few of the users LOVE to use Word for creating articles, then copy/paste into our CMS and upload to the server. We are constantly fielding calls from the department wondering why an article isn't appearing or why an article is making the screen 'throw up' all over the place. We constantly remind them that they can't use Word, to no avail.
V/r,
^ _ ^
Copy link to clipboard
Copied
WolfShade We upgraded from CF10 to CF2016... so it's possible we've never encountered this version-specific bug as a result of skipping CF11.
We use CKEditor (not the built-in, outdated version of FCKEditor that Adobe uses) and it can detect when MSHTML is pasted and offers to convert it to regular HTML or plain text. On the back-end, we have a content replacement script that sanitizes a lot of the MSHTML nonsense.
having been frustrated with Microsoft's attempts to "smart-quote" everything, I wrote an AutoHotKey script (Windows+V) that performs some modifications to your current clipboard to remove the smart quotes & non-breaking spaces that Microsoft adds. This has been a huge timesaver as I don't have manually correct anything after pasting.
https://www.sunstarmedia.com/autohotkey-scripts.htm#StripFormatting
Copy link to clipboard
Copied
Yep, I agree that is the most likely scenario for not having experienced the lowercase bug. I've never experienced it in CF10 or earlier.
I work for US DoD, and have to be very paranoid about what input users can provide. We don't use CKEditor or any other RTF editor for anything, not even news articles. I have a script that strips out all HTML from user input. It never occurred to me to include stripping out MSHTML bs. I'll have to remedy that. 
That script looks awesome, but I cannot use it in my work environment. Well, I could, but it would involve sending it to security for screening, then to testing, then it would be STIG'd, then it would sit in queue for approval for at least six months before anyone would even think about signing off on it.
V/r,
^ _ ^
Copy link to clipboard
Copied
It's an official new bug. I've been using ASCII characters since CF 6 and only just now stopped working in CF2016u8 & 9.
Here's the bug I reported. Adobe responded within 24 hours and indicated that the bug will be fixed in an upcoming Hotfix 10 release.
https://tracker.adobe.com/#/view/CF-4204050
Until then, I've overcome this issue by adding a UDF+JAR that converts unicode to ASCII7. I added this workaround that I'm using to the bug report.
To sanitize non-ASCII7 characters from a text string, the workaround I've been using is to convert all unicode to ASCII7 using JUnidecode. (We also use this to sanitize filenames & URL path strings.)
https://gamesover2600.tumblr.com/post/182608667654/coldfusion-unicode-junidecode-demo
Using JUnidecode requires adding a JAR file to your project, but the results are much better than writing your own regex filter or using Normalizer, Transliterate or StripAccent libraries.
Copy link to clipboard
Copied
ColdFusion 2016 update 10 has arrived... and this hasn't been fixed.

Copy link to clipboard
Copied
The news sounded to me like the security issue was so urgent that the updater only brings the fix.
Adobe Patches Critical ColdFusion Vulnerability With Active Exploit | Threatpost
Copy link to clipboard
Copied
Wow... I wasn't even aware that this was an urgent release.
The blog post that I read starts out with "We are pleased to announce" and doesn't bother mentioning the priority 1 rating vulnerability that affects CF2016 update 9:
Copy link to clipboard
Copied
This was the first I read today so I had an idea: Adobe Security Bulletin
Copy link to clipboard
Copied
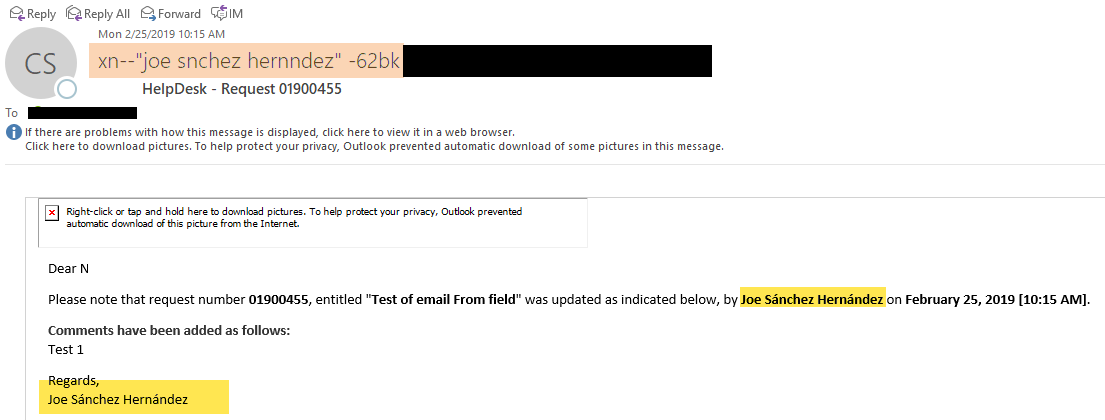
It looks like Punycode encoding (RFC 3492) that's used for domain names that contain special/high characters.
There's a JAVA function that can do this
To get the result ending by "-62bk" the name has to be followed ba a space.
<cfdump var="#CreateObject( "java", "java.net.IDN" ).toAscii('"Joe Sánchez Hernández "')#">
<cfdump var="#CreateObject( "java", "java.net.IDN" ).toUnicode('xn--"joe snchez hernndez" -62bk')#">
Interestingly there's a space in front of the dash/minus 62bk after the quotes. The encoded result does not differ whether there's a space before or after the quote.

 AdChoices
AdChoices