 Adobe Community
Adobe Community
- Home
- ColdFusion
- Discussions
- Query of query does not handle UTF8 characters
- Query of query does not handle UTF8 characters

Copy link to clipboard
Copied
Hi,
I query data from an Oracle database, loop the result and add some data using querySetCell. Finally using cfquery dbtype="query" I select everything using an ORDER BY clause. Sadly my data is not sorted the way I expect. Special characters like German umlauts are sorted at the end of the result and not according to their position in the alphabet. When I dump the result of the query I see characters are "broken". Instead of Ö at the beginning of a word I see some placeholders. Looks like the data was encoded twice or misinterpreted according to the character set.
Does ColdFusion have issues working with data from an Oracle query? Is there a way I can tell CF the data in the query is UTF8 encoded?
Best,
Bernhard


 1 Correct answer
1 Correct answer

I did some looking around, and I don't think this is a CF issue, it's an Oracle issue.
Multilingual Linguistic Sorts
Oracle provides multilingual linguistic sorts so that you can sort data in more than one language in one sort. This is useful for regions or languages that have complex sorting rules and for multilingual databases. Oracle Database 10g supports all of the sort orders defined by previous releases.
For Asian language data or multilingual data, Oracle provides a sorting mechanism based o
... 12
Replies
12
12
Replies
12
Copy link to clipboard
Copied
Forgot the most important thing: I query the Oracle DB using the thin driver.
Copy link to clipboard
Copied
Just curious. If you sort in the original query, does it sort correctly?
AFAIK, there are no CFQUERY attributes to indicate UTF8, nor are there any settings in CFAdmin Data Sources.
V/r,
^ _ ^

Copy link to clipboard
Copied
Does it help when you put this line at the beginning of the page:
<cfprocessingdirective pageEncoding="UTF-8" />
If that doesn't help, add the following to the Java (JVM) settings in the ColdFusion Administrator:
-Dfile.encoding=UTF8
Copy link to clipboard
Copied
Thanks for the replies.
My files are UTF8 encoded, therefore my JVM args already contain -Dfile.encoding=UTF8
In Oracle the result is sorted correctly and all the characters are displayed right in a cfdump.
Copy link to clipboard
Copied
What was the result when you used <cfprocessingdirective>?
Copy link to clipboard
Copied
cfprocessingdirective changed nothing.
I made a minimal sample. The special characters were not broken in the dump. Sorted last, still.
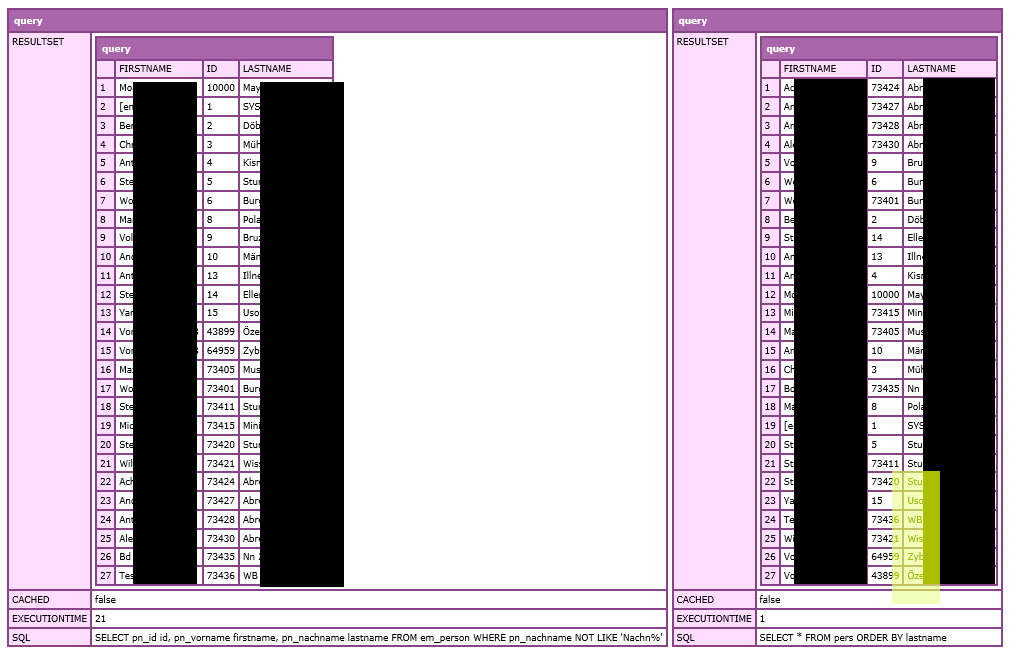
Copy link to clipboard
Copied
I did some looking around, and I don't think this is a CF issue, it's an Oracle issue.
Multilingual Linguistic Sorts
Oracle provides multilingual linguistic sorts so that you can sort data in more than one language in one sort. This is useful for regions or languages that have complex sorting rules and for multilingual databases. Oracle Database 10g supports all of the sort orders defined by previous releases.
For Asian language data or multilingual data, Oracle provides a sorting mechanism based on the ISO 14651 standard and the Unicode 4.0 standard. Chinese characters are ordered by the number of strokes, PinYin, or radicals.
In addition, multilingual sorts can handle canonical equivalence and supplementary characters. Canonical equivalence is a basic equivalence between characters or sequences of characters. For example, ç is equivalent to the combination of c and ,. Supplementary characters are user-defined characters or predefined characters in Unicode 4.0 that require two code points within a specific code range. You can define up to 1.1 million code points in one multilingual sort.
For example, Oracle supports a monolingual French sort (FRENCH), but you can specify a multilingual French sort (FRENCH_M). _M represents the ISO 14651 standard for multilingual sorting. The sorting order is based on the GENERIC_M sorting order and can sort diacritical marks from right to left. Oracle Corporation recommends using a multilingual linguistic sort if the tables contain multilingual data. If the tables contain only French, then a monolingual French sort may have better performance because it uses less memory. It uses less memory because fewer characters are defined in a monolingual French sort than in a multilingual French sort. There is a tradeoff between the scope and the performance of a sort.
HTH,
^ _ ^
UPDATE: I guess it would have been nice if I had included the link to that.. smh..
https://docs.oracle.com/cd/B28359_01/server.111/b28298/ch5lingsort.htm#i1005958
Copy link to clipboard
Copied
Personally, I try to avoid QoQ as much as possible. If I can get along without it, I much prefer to not use it. Primarily because it doesn't have the full functionality that a standard query does. Believe it or not, QoQ does NOT have the ability to use modulus. Annoying.
If the CFDUMP is displaying correctly, then I wonder if using canonicalize(false,false) on the output would work.
(Nevermind.. the issue wasn't the output, it was the sorting. Duh.)
HTH,
^ _ ^

Copy link to clipboard
Copied
This is an issue with unicode characters. Query of Query will not sort them as you want. However, you have some options.
You need to convert your names strings to ASCII strings. To do that you can drop down to Java. There is the 'java.text.Normalizer' in Java 6 and above. Or you could drop in a jar such as https://github.com/gcardone/junidecode
James Moberg recently wrote a blog post about it:
https://gamesover2600.tumblr.com/post/182608667654/coldfusion-unicode-junidecode-demo
You can then store the normalised version in a new column and sort on that in your query or queries, or you could use QuerySort to convert on the fly.
Copy link to clipboard
Copied
Sorry for not returning earlier.
Thanks alot for your suggestions. I take it's not an issue of ColdFusion working with the data retrieved from the Thin JDBC driver.
I will dive deeper into this issue, no idea why I first observed it in an Oracle scenario.
Copy link to clipboard
Copied
Hi Bardnet
I wrote a blog post about this which I hope will be useful to you:
https://coldfusion.adobe.com/2019/02/sorting-text-containing-characters-diacritical-marks/
Copy link to clipboard
Copied
Thanks for the mention. I'll look into this.

 AdChoices
AdChoices