 Adobe Community
Adobe Community
- Home
- InDesign
- Discussions
- Anchored images disappear after script replaces te...
- Anchored images disappear after script replaces te...

Copy link to clipboard
Copied
I have a script that changes the encoding of an Indic document to Unicode by iterating over textStyleRanges. The encoding change is based on existing well-tested JS code and works great except that the anchors text-colors all move or disappear on conversion.
function ascii2unicode(text){ var words = text.split(' '); // To stote converted words var op_words = []; // Process and append to main array words.forEach(function(word, k, arr){ op_words.push('mwe-text'); }); // Return converted line return op_words.join(' '); } var doc = app.activeDocument; var stories = doc.stories; var textStyleRanges = stories.everyItem().textStyleRanges.everyItem().getElements(); for (var i = textStyleRanges.length-1; i >= 0; i--) { var myText = textStyleRanges[i]; if (myText.appliedFont.fontFamily.toLowerCase().indexOf('nudi') == 0) { var converted = ascii2unicode(myText.contents); if (myText.contents != converted) { myText.contents = ""; myText.appliedFont = app.fonts.item("Tunga"); myText.contents = converted; myText.composer="Adobe World-Ready Paragraph Composer"; } } }


 2 Correct answers
2 Correct answers

If you use .contents to replace you're going to wipe out the insertion points containing anchors. You can try using findText() instead.

Hi all,
@brianp311's approach seems to me the way to go—as long as GREP slow perfs are not an issue.
Anyway, the original problem is interesting: how to skip over problematic characters (anchored objects U+FFFC, but also tables U+0016, note references U+0004, and so on) when processing an array of Text Style Ranges?
That's tricky! We probably need to sub-split each individual text range with respect to special characters that must be preserved. But then we have to resolve the sub-ranges and take
... 17
Replies
17
17
Replies
17
Copy link to clipboard
Copied
Plesae refer to this code, i mistakenly pasted it into the body part
function ascii2unicode(text){
var words = text.split(' ');
// To stote converted words
var op_words = [];
// Process and append to main array
words.forEach(function(word, k, arr){
op_words.push('mwe-text');
});
// Return converted line
return op_words.join(' ');
}
var doc = app.activeDocument;
var stories = doc.stories;
var textStyleRanges = stories.everyItem().textStyleRanges.everyItem().getElements();
for (var i = textStyleRanges.length-1; i >= 0; i--) {
var myText = textStyleRanges[i];
if (myText.appliedFont.fontFamily.toLowerCase().indexOf('nudi') == 0) {
var converted = ascii2unicode(myText.contents);
if (myText.contents != converted) {
myText.contents = "";
myText.appliedFont = app.fonts.item("Tunga");
myText.contents = converted;
myText.composer="Adobe World-Ready Paragraph Composer";
}
}
}
Copy link to clipboard
Copied
@Marc Autretcould you please suggest something

Copy link to clipboard
Copied
I'm not a script wizard, but I think you are overlooking that anchors are, in effect, just another character in the text string. Your replacement of the text is deleting the anchors, which could be for any of several specific technical reasons.
It seems to me that the script should check for all hidden and formatting characters and specifically 'do nothing' with them.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢
Copy link to clipboard
Copied
Thannks James, i will check and share if it works
Copy link to clipboard
Copied
I think this identifies the problem; I am not enough of a script expert to help modify the code. There are some very good scripters here, though.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢
Copy link to clipboard
Copied
If you use .contents to replace you're going to wipe out the insertion points containing anchors. You can try using findText() instead.
Copy link to clipboard
Copied
Could please help me make the necessary changes in the script, I am farely novice when it comes to scripting
Copy link to clipboard
Copied
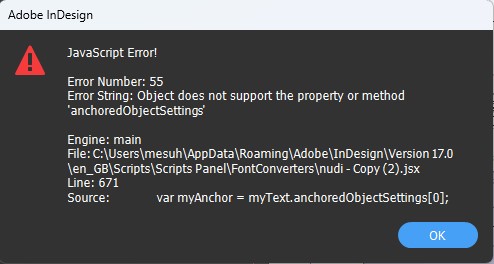
I even tried using this code but somehow it is throwing error
var doc = app.activeDocument;
var stories = doc.stories;
var textStyleRanges = stories.everyItem().textStyleRanges.everyItem().getElements();
for (var i = textStyleRanges.length-1; i >= 0; i--) {
var myText = textStyleRanges[i];
if (myText.appliedFont.fontFamily.toLowerCase().indexOf('nudi') == 0) {
var converted = ascii2unicode(myText.contents);
if (myText.contents != converted) {
var myAnchor = myText.anchoredObjectSettings[0];
var myColor = myText.fillColor;
myText.contents = "";
myText.appliedFont = app.fonts.item("Tunga");
myText.contents = converted;
myText.composer="Adobe World-Ready Paragraph Composer";
myText.anchoredObjectSettings[0] = myAnchor;
myText.fillColor = myColor;
}
}
}Copy link to clipboard
Copied
This is not a trivial solution. You'd need to identify whether the found text, store the anchor objects, reinsert them at the correct location. Does the text length change?
Copy link to clipboard
Copied
Modifying the search to end and then begin on hidden characters, or just the anchor glyph, should not be impossibly difficult... or so it seems.
I am unclear on why text would need to be re-encoded letter by letter, but I will assume the OP understands the need and purpose. This should just be a find-and-change with a special cutout to avoid the anchored elements.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢
Copy link to clipboard
Copied
No it is not, but my original script behaving in a weired manner, It is preserving only released anchors while converting in unicode, In many places the formatting is lost completely, As a workaround i released all the anchored images and removed
myText.contents = "";
After that some of the formatting is preserved but still not able to figureout a perfect solution for file with anchored images. You can check the attached file for reference.
Copy link to clipboard
Copied
OK, not outside the realm of triviality. Something like this might work. Still don't know what's going on with your asciiToUnicode function, and if the length of the text you're replacing changes, then the anchor is going to move with it.
var doc = app.activeDocument;
app.findGrepPreferences = app.changeGrepPreferences = null;
app.findGrepPreferences.appliedFont = "Tunga";
app.findGrepPreferences.findWhat = "[^~a]+";
var fs = doc.findGrep();
var i = fs.length;
while(i--) {
fs[i].contents = ascii2unicode(fs[i].contents);
}
Copy link to clipboard
Copied
Hi all,
@brianp311's approach seems to me the way to go—as long as GREP slow perfs are not an issue.
Anyway, the original problem is interesting: how to skip over problematic characters (anchored objects U+FFFC, but also tables U+0016, note references U+0004, and so on) when processing an array of Text Style Ranges?
That's tricky! We probably need to sub-split each individual text range with respect to special characters that must be preserved. But then we have to resolve the sub-ranges and take care of text indices while replacing the contents.
Here is a quick proof of concept:
Should solve the particular issue that @Suhaib Husain posed. But above all, this might serve as a skeleton for more general converters intended to run fast on long documents. Of course, special text containers like notes or tables are not adressed here—since the target is myDoc.stories.everyItem().textStyleRanges.everyItem().
Hope that helps.
Best,
Marc
Copy link to clipboard
Copied
Thank You So much @Marc Autret @brianp311 let me check, will get back with more details on how it went.
Copy link to clipboard
Copied
Hi @Marc Autret Your script is just Brilliant, It is working perfectly for
myDoc.stories.everyItem().textStyleRanges.everyItem()I made some changes to make it work for notes and tables etc, but somehow its not working, I tried and not able identify what mistake i am committing, Could please help once more and check my version and suggest what i am doing wrong. Thank you so much for all your help.
// InDesign script (DRAFT.)
//----------------------------------
// Apply some text conversion routine on consistent
// style ranges *while preserving special characters*
// (anchored objects, tables, footnotes...)
function myConverter(/*str*/text)
//----------------------------------
// Change a string into something else...
// Put your ascii-to-unicode routine here
{
return 'x' + text.split('').reverse().join('');
}
(function( doc,pp,ptn,src,rng,a,i,tx,t,x,b,j,z)
//----------------------------------
{
function marc() {
// [REM] Forcing resolve is important!
// ---
// Filter based on font family.
// ---
t = (tx.properties.appliedFont||0).fontFamily||'';
if( -1 == t.toLowerCase().indexOf(TARGET_FAMILY_LOWER) ) return;
// Get the last character index (x) and create a specifier
// pattern for accessing character ranges from %1 to %2.
// ---
ptn = tx.toSpecifier().split('%').join('%%'); // Safer (in case the spec contains `%`, change into `%%` for the pattern.)
ptn = ptn.split('/character['); // E.g `(/document[@id=4]//story[@id=222]`, `12] to /document[@id=4]//story[@id=222]`, `34])`
if( 3 != ptn.length || isNaN(x=parseInt(ptn[2],10)) ) return; // Shouldn't happen.
ptn = ptn[0]+'/character[%1] to '+ptn[0].slice(1)+'/character[%2])'; // Pattern for characterRange(%1,%2)
// Split text contents w.r.t SPLIT_CHARS (U+0016, U+FFFC, etc)
// in order to preserve anchored objects and so.
// ---
t = tx.texts[0].contents + '\x01'; // [HACK] Help prevent the split(RegExp) bug (last char issue.)
b = t.split(RE_SKIP);
( t=b.length-1, b[t]=b[t].slice(0,-1) ); // [HACK] Remove \x01 suffix.
for( j=b.length ; j-- ; x-=(1+z) ) // b :: [src1, src2, src3...] ; tx.contents == `src1•src2•src3•...` where • is any INDD mark.
{
z = (src=b[j]).length; // src :: original substring ; z :: length
if( !z ) return; // Empty -> simply jump over the mark.
rng = resolve( __(ptn, ''+(x-z+1), ''+x) ); // rng :: character range of the source (Text object.)
pp.contents = myConverter(src)||''; // Converted substring.
rng.properties = pp; // Replace.
}
}
if( !(doc=app.properties.activeDocument) ) { alert("No document."); return; }
// Special characters that MUST be skipped.
// Footnote refs, tables, anchored objects...
// ---
const RE_SKIP = /[\u0004\u0016\uFFFC]/;
// YOUR SETTINGS
// ---
const TARGET_FAMILY_LOWER = ("Minion Pro").toLowerCase(); // E.g "nudi";
const DEST_FONT_NAME = "Myriad Pro\tItalic" // E.g "Tunga";
// Check dest font and set properties.
// ---
if( !(t=app.fonts.item(DEST_FONT_NAME)).isValid )
{ alert("The font " + DEST_FONT_NAME + " is missing."); return; }
pp =
{
contents: '',
appliedFont: t.getElements()[0],
composer: "$ID/HL Composer Optyca", // Adobe World-Ready Composer
// etc
};
// Pattern formatter.
// ---
const __ = $.global.localize;
// Array of consistently styled Text items.
// ---
a = doc.stories.everyItem().textStyleRanges.everyItem().getElements().slice();
for( i=a.length ; i-- ; )
{
tx = a[i].getElements()[0]; // tx :: Text ; consistent text range
marc();
}
var tables = doc.stories.everyItem().tables.everyItem().getElements();
for (i = 0; i < tables.length; i++){
var cells = tables[i].cells;
for (var cell = 0; cell < cells.length; cell++) {
a = cells[cell].textStyleRanges.everyItem().getElements().slice();
for( var j=a.length ; j-- ; )
{
tx = a[j].getElements()[0]; // tx :: Text ; consistent text range
marc();
}
}
}
})();Copy link to clipboard
Copied
Hi @Marc Autret can you help please?, I am still unable to figure out how to include tables and notes

Copy link to clipboard
Copied
Ford employees frequently access the website MyFordBenefits, one of the most popular Ford websites. As a Ford employee who recently discovered the MyFordBenefits website, we have put together a detailed article on the website, which includes a guide to how to log into MyFordBenefits. https://my-ford-benefits.live/

 AdChoices
AdChoices
{kind=link}
{kind=link}
{kind=link}