
Extract single page pdfs with specific names
I want to create a acrobat action to extract single page pdfs to specific names. first I'am using the "Search and Remove Text" under Protection to find the text to be used for the individual file naming. This creates Comments for each page with the unique text for the names. Then I want to use javascript to to do the extracting.
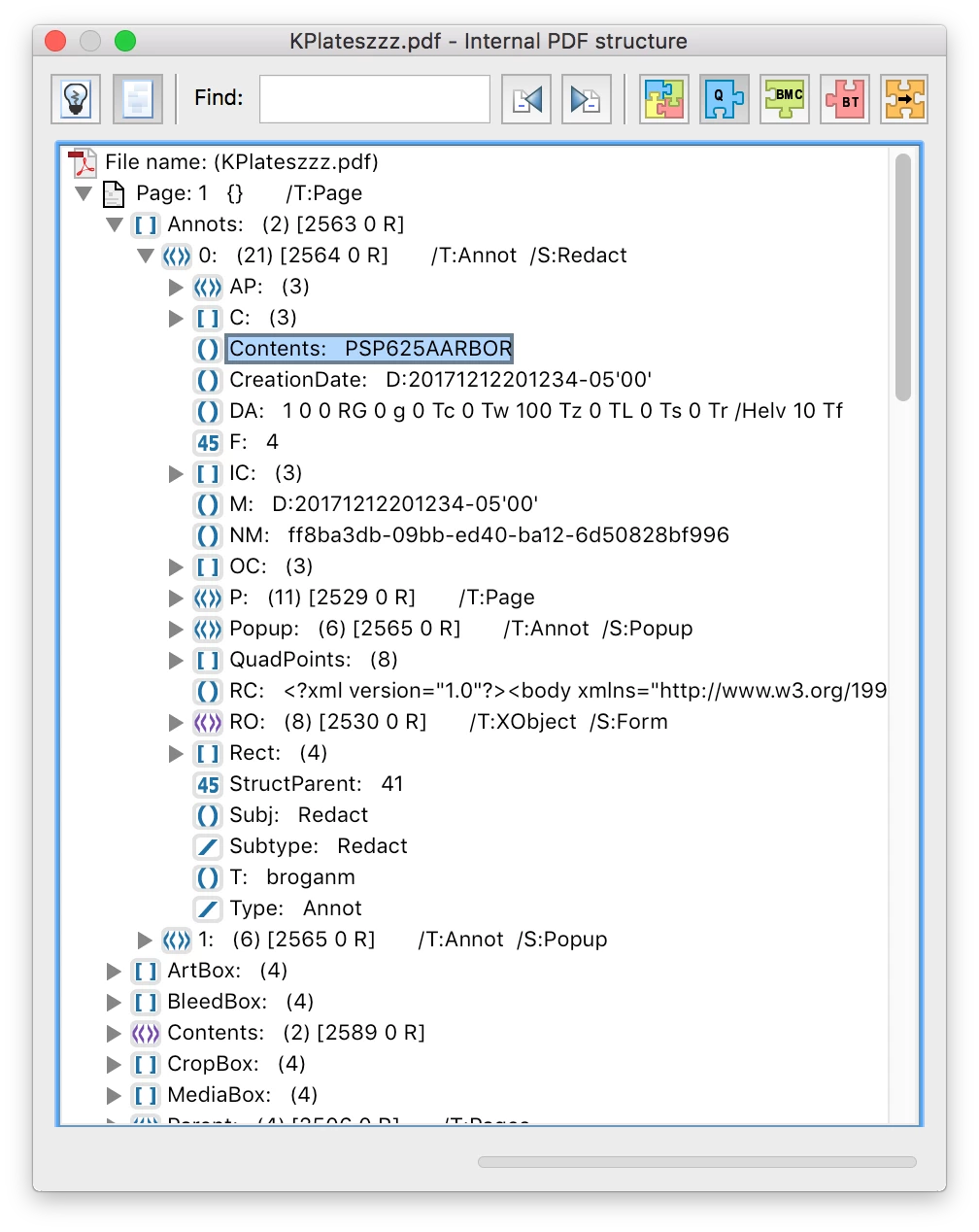
I found this code on the forum that extracts single page pdfs. I need the extracted pdfs named by the Contents............ Annots:/ Redacts:/ Contents: with the Annots removed.
I've tried to modify the code with no luck. I am new to scripting, I understand the concept I just don't know the method/properties to perform the function to apply the Annots Contents from each page to the naming of each extracted pdf.
code that extracts single page pdfs.
var re = /.*\/|\.pdf$/ig;
var filename = this.path.replace(re,"");
{
for ( var i = 0; i < this.numPages; i++ )
this.extractPages ({ nStart: i, nEnd: i, cPath : filename + "_page_" + (i+1) + ".pdf"});
};
Thanks in advance for any help!!