

- Home
- Acrobat
- Discussions
- Re: Extract PDF Pages Based on Content
- Re: Extract PDF Pages Based on Content

Copy link to clipboard
Copied
Every fall and winter I have to work with PDF files that are hundreds of pages. Last fall I came across a java script that I was able to run and it worked beautifully. In the last year, I have either lost more brain cells or acrobat dc doesn't work the same way as acrobat X. I need to find a way to extract the pages based off of a word search and save those pages to another file. I would appreciate any suggestions. Also, I have added the java script that was used last year. Thanks in advance for your help.
// Iterates over all pages and find a given string and extracts all
// pages on which that string is found to a new file.
var pageArray = [];
var stringToSearchFor = "Total";
for (var p = 0; p < this.numPages; p++) {
// iterate over all words
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
pageArray.push(p);
break;
}
}
}
if (pageArray.length > 0) {
// extract all pages that contain the string into a new document
var d = app.newDoc(); // this will add a blank page - we need to remove that once we are done
for (var n = 0; n < pageArray.length; n++) {
d.insertPages( {
nPage: d.numPages-1,
cPath: this.path,
nStart: pageArray
nEnd: pageArray
} );
}
// remove the first page
d.deletePages(0);
}



Copy link to clipboard
Copied
I assume you were running the script as an Action in Acrobat XI (as described in my blog post). You can do the same thing in Acrobat DC. Just download the SEQU file again (from here: Extract PDF Pages Based on Content - KHKonsulting LLC) - then make sure that the filename is ExtractPagesWithString.sequ (when I download the file using Safari on a Mac, it appends .xml at the end - in that case, just rename the file so that it has the .sequ extension again). Now you should be able to drag&drop the file on the new Acrobat DC icon or into the application window. You should get get a confirmation dialog (or two). Once the Action is imported, you should be able to run it. To find the Actions interface, type "Action" into Acrobat's tool search bar. You will find that at the top of the right hand pane, and at the top of the Tools collection when you click on Tools on the left side of the Acrobat window, or you can try to find the "Action Wizard" on the Tools page and click on it. You can now run the Action on one or more files, but it will always just search for the string that I've put into the code. To change that. select to edit the Action. Let's assume that you click on the Action Wizard on the Tools page. You should now see the following:

Click on the "Manage Actions" button and then select the "Extract Pages With String" Action and click on the "Edit" button:
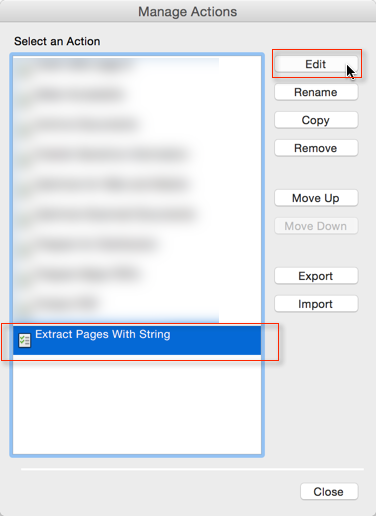
The next thing you will see is this:
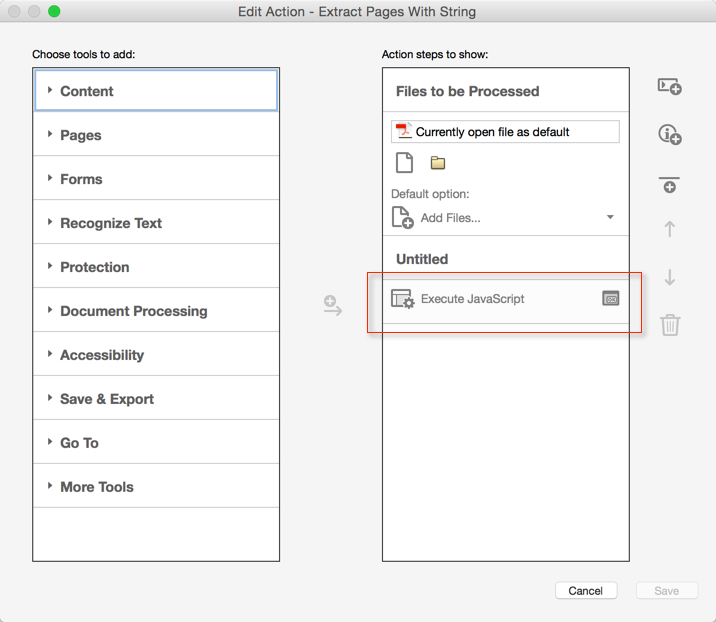
When you now click on "Execute JavaScript", this Action item will expand and will look like this:
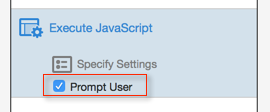
Make sure that "Prompt User" is checked.
Now you can save your modified Action. When you run the Action, you will see the JavaScript editor pop up:
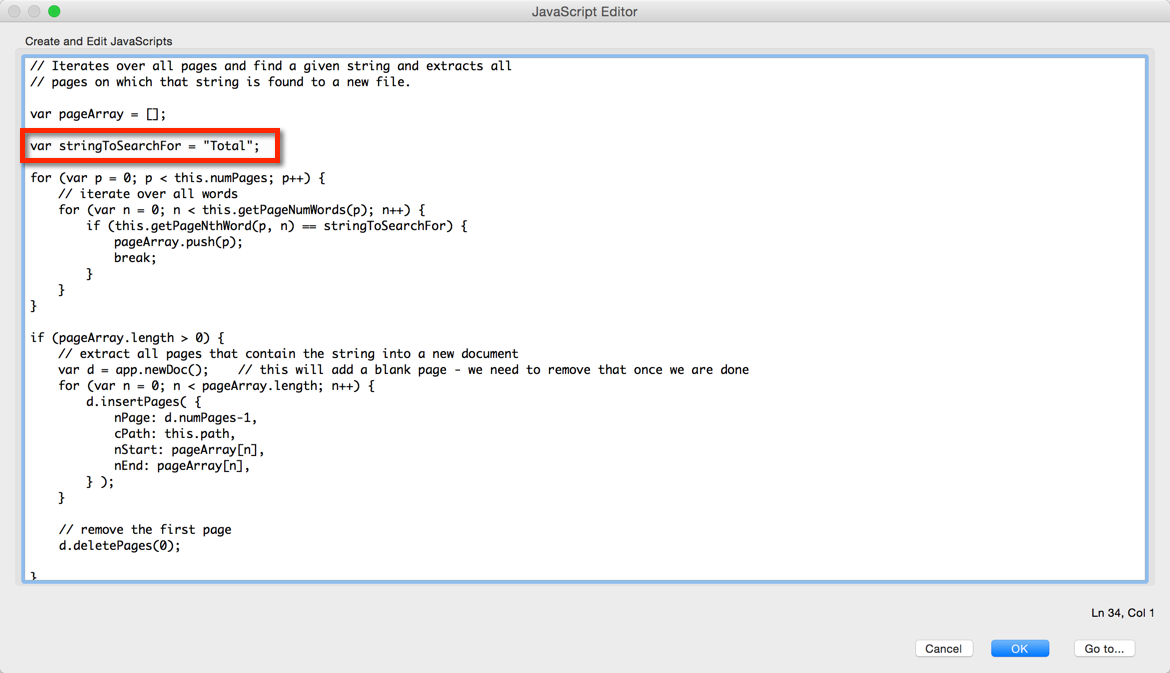
You can now change the "stringToSearchFor" variable and set it to whatever text string you want to search for and split the document at.
 37
Replies
37
37
Replies
37

Copy link to clipboard
Copied
Do you want to extract each page as a separate file, or to put them all into a single file?

Copy link to clipboard
Copied
I would like them in the same file if possible!
Copy link to clipboard
Copied
That's even trickier... You would need to create a dummy file with a blank page and then insert the matching pages into it, and then delete the dummy page at the end of the process.
I've developed very similar tools for some of my clients so if you're interested in hiring someone to do it for you (for a fee), feel free to contact me privately (try6767 at gmail.com) and we could discuss it in more detail.
Copy link to clipboard
Copied
As was explained by try67, this is not a simple task. If it would be acceptable to extract individual pages, and you would then merge them manually, it would reduce the complexity a bit. However, given that my action from above already inserts multiple pages (and takes care of deleting the blank first page), it would are possible to modify that code. Take a look at the screenshot with the code above, you will find these lines it it:
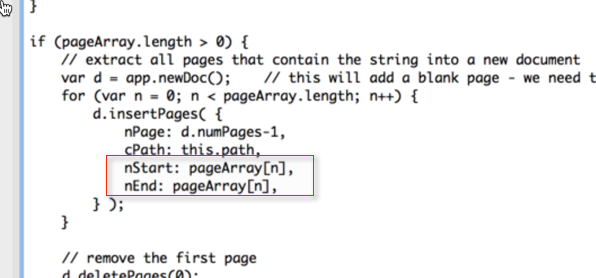
These two lines indicate which page will be inserted into the document. A very simple solution would be to adjust this statement and just add the following page as well. This has however a few potential problems: If the document does not contain a page following the page on which you found the term, the script will fail. If both the current page and the following page contain the term, you will end up with the second page being duplicated in your output file. These problems can be addressed, but it complicates the code a bit.
For now, I'll just show you what you would need to modify in the red box above:
nStart: pageArray
, nEnd: pageArray
+1,
As you can see, the first line did not change, the second one did change, and we are adding "1" to the page number.

Copy link to clipboard
Copied
If you approach the problem differently, you will save yourself a lot of heartache. Instead of extracting pages that you want, delete pages that you don't. You script would start by doing a SaveAs to a new file then you can use some of the code above to detect pages that you want to keep and deleting the pages that you don't. Work from the back to the front and you won't need to keep track of page numbers.
Copy link to clipboard
Copied
Joel,
I am not sure if you are referring to my problem, but this is not a solution. I need to run this script daily and the pages that are extracted are in a different location of a 500-page file every day. So deleting would be more work than a find and extract.
Copy link to clipboard
Copied
"So deleting would be more work than a find and extract."
I assure you, that's not true. The portion of the script used to locate the pages to extract would be used instead to identify the pages to not delete. Using that method, you don't have the additional problem of assembling the extracted pages into a new file. It's a much simpler script than extracting and combining.
Copy link to clipboard
Copied
Joel,
This is why I am not the expert - lol. Is it a simple change in the script provided above?

Copy link to clipboard
Copied
Anyone know how I can make this process run over and over with different variables without having to sit in front of the computer and waiting?
Copy link to clipboard
Copied
Acrobat is not built for this kind of automation (on purpose). You would need to use a stand-alone tool to be able to do it like that. If you're interested I could develop for you such a tool (for a fee). You can contact me privately via [try6767 at gmail.com] to discuss it further.

Copy link to clipboard
Copied
Is it possible to get this action to work with 2 words separated by a space? For example: "AB 123"
Were looking to extract a form with the form number printed on the page. So far, we have been able to get this action to work but only for the "AB", and we get 8 different forms.
When we try "AB 123" nothing happens.
Copy link to clipboard
Copied
Also we need to get the extract to save automatically to folder.

Copy link to clipboard
Copied
Is there a Javascript that deletes pages if they do not contain one of the multiple supplied keywords? I have a functioning version that allows page deletion for one keyword but not multiple.
-
- 1
- 2

 AdChoices
AdChoices