Hi,
I gave you a quick answer, but spending a bit more time it is possible to improve the script.
Here is what I did:
d0=new Date();
debut=util.printd("date(en){MMMM DD, YYYY}",d0,true)+util.printd(" – hh:MM:ss tt",d0);;
function tableOfContents(bkm, nLevel) {
var s="";
for (var i=0; i<nLevel; i++) s+=" ";
bkm.execute();
var p=this.pageNum;
console.clear();
console.println("Process starting: "+debut);
console.println("Processing the page #"+(p+1)+"/"+this.numPages);
var pageName="";
var numWords=this.getPageNumWords(p);
for (var i=0; i<numWords; i++) {
var ckWord=this.getPageNthWord(p, i, false);
var q=this.getPageNthWordQuads(p, i);
m=(new Matrix2D).fromRotated(this,p);
mInv=m.invert();
r=mInv.transform(q);
r=r.toString();
r=r.split(",");
if (Number(r[0])>300 && Number(r[1])<35) pageName+=ckWord;
}
if (bkm.name!="Root") {
var designation=bkm.name.replace(/\t/g," ").replace(/\s*$/,"");
var pageName=pageName.replace(/\s*$/,"");
toc+=s+designation+dots.substr(0,dots.length-(s.length+designation.length+pageName.length))+pageName+"\r";
}
if (bkm.children != null) for (var i=0; i<bkm.children.length; i++) tableOfContents(bkm.children[i], nLevel+1);
}
var aRect=this.getPageBox("Crop");
var h=aRect[1];
aRect[1]=50;
this.setPageBoxes({cBox: "Crop", rBox: aRect});
var toc="";
var dots="............................................................";
tableOfContents(this.bookmarkRoot, 0);
aRect[1]=h;
this.setPageBoxes({cBox: "Crop", rBox: aRect});
this.createDataObject("toc.txt", "","text/html");
var oFile=util.streamFromString(toc);
this.setDataObjectContents("toc.txt", oFile);
event.target.viewState={overViewMode:7};
df=new Date();
fin=util.printd("date(en){MMMM DD, YYYY}",df,true)+util.printd(" – hh:MM:ss tt",df);;
console.println("\rProcess ending: "+fin);
temps=(df.valueOf()-d0.valueOf())/1000/60;
var lesMinutes=parseInt(temps);
var lesSecondes=(temps-lesMinutes)*60;
var lesSecondes=parseInt(lesSecondes*10)/10;
var leTemps="";
if (lesMinutes>0) {
if (lesMinutes==1) var leTemps="1 minute";
else var leTemps=lesMinutes+" minutes";
}
if (lesSecondes>0) {
if (lesSecondes<2) var leTemps=leTemps+" "+lesSecondes+" second";
else var leTemps=leTemps+" "+lesSecondes+" seconds";
}
var leTemps=leTemps.replace(/^\s+|\s+$/gm,"");
console.clear(); console.show();
console.println("Process starting: "+debut);
console.println("Process ending: "+fin);
console.println("Process duration: "+leTemps+" for "+numPages+" pages");
console.println("\rTable of Contents \""+this.documentFileName.replace(/.pdf$/i,"")+"\":\r\r");
console.println(toc);
With this script you generate a txt file containing the table of contents.
I don't know the duration of your script for your 2000-page document!
I did a test with my api reference file (805 pages) and that took a bit more than 3 minutes.
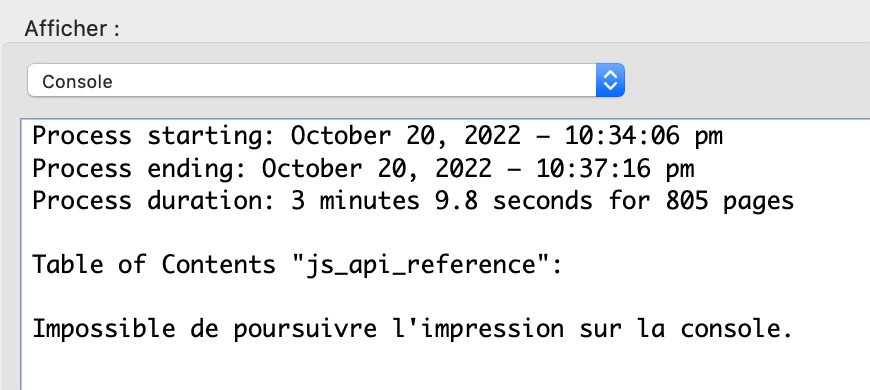
With a quite long toc the result can't be displayed in the console but you will have the entire toc in the attached toc.txt file.
Attached is a pdf file including an action wizard with the script... Let me know!
@+
