

- Home
- Acrobat SDK
- Discussions
- Re: access acrobat pdf (File Properties data ) pro...
- Re: access acrobat pdf (File Properties data ) pro...
access acrobat pdf (File Properties data ) programatically for every pdf on a drive

Copy link to clipboard
Copied
i know I can open up each PDF file manually and view the File / Properties / Desc info like Title, Author, Keywords, Number of Pages, etc.
I want to do this programmatically and pull this data into a database which can be used as a simple document management system.
Please note I said SIMPLE, I don't know why it is so difficult to explain this concept to support that over complicates the issue. You would think Adobe would provide a simple interface to do this with Reader or the full Acrobat.
Here is the scenario. I have thousands of Acrobat PDF documents on my hard drive. Each PDF file I know in the files Header maintains this metadata information of Document Properties. I want to retrieve this information so as to create a document database catalog or management system. Initially I have some 15,000 pdf documents I need to track.
Here is a picture of the information I want to obtain programmatically via an automatic scripted process. Or if their is a utility that will automatically dump the info into some sort of exported data file that would be fine also.
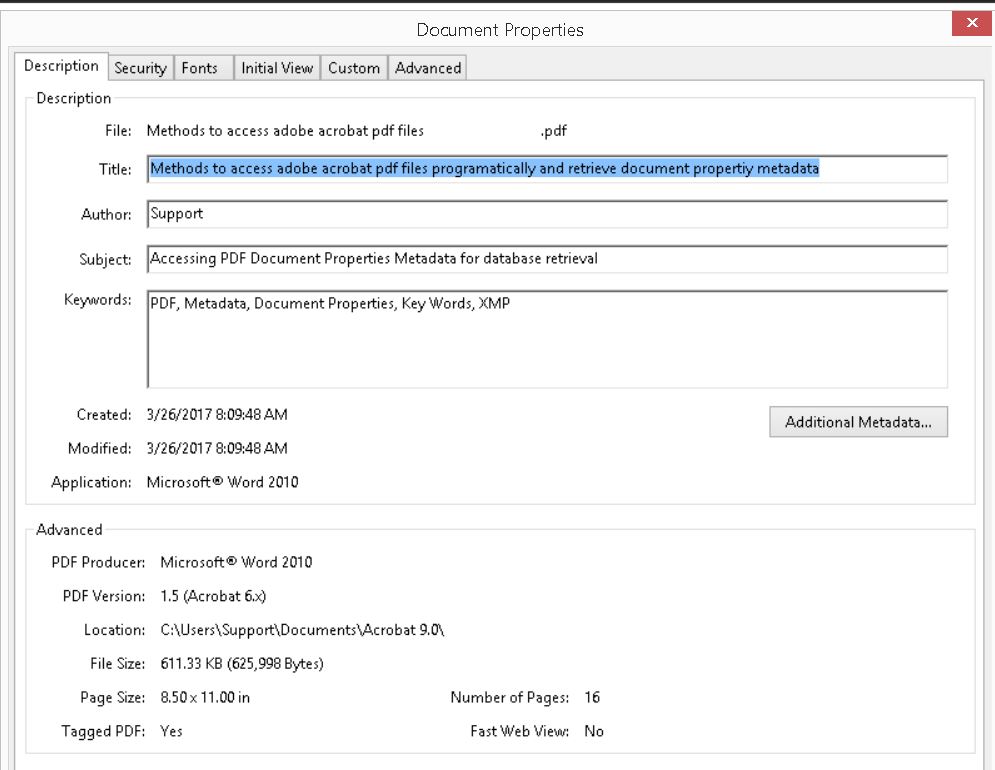
That is my first step in this project.
My second step is if you have documents that contain bates page numbering ID information is this also capturable.
Bates page numbering is not the same as the PDF document page number. It wold be nice if in the database we were able to say that document "sample.pdf " uses Bates Numbers XXX #### through ZZZZ ####
Currently I am trying to do this on a small scale using MS Access as the Database Front End.
I have done some searching on the web for a solution but none specifically show how to do the above request specifically.
I do not currently have a need to edit or add to this data information on the PDF document itself, but that would be a nice feature to have.
Currently were using MS Access as a front end but were open to other suggestions.
Were not storing the actual document in the database, but just a link to retrieve the document.
I also have knowledge of PHP, Java Script, VBA and a few other programming tools.
Thanks for your assistance.
Cole


 5
Replies
5
5
Replies
5

Copy link to clipboard
Copied
Here are some things. No idea if this is simple enough.
1. Acrobat programmers need Acrobat. Pro or Standard. Acrobat Reader, the free product, is not Acrobat.
2. Support don't help developers. That's not their job and they won't have understood the question.
3. Acrobat developers all need the Acrobat SDK, a free download with thousands of pages of documentation.
4. The Acrobat SDK is long on information, but very short on samples. You will need to do detailed reading, you will not find code to copy/paste.
5. There is an Acrobat SDK forum.
6. Acrobat gives you no tools to work on all PDF files in a directory or disk. You'd use your own scripting or programming language to scan for files. Then you could use Acrobat to process each one.
7. Acrobat is an interactive tool with simple automation. It really doesn't handle large collections well. I'd recommend quitting Acrobat every 50-100 files.
8. The most commmon scripting model mixes an external app/scripting host, OLE/COM, and JavaScript. JavaScript is where most of the methods are, but it needs the OLE (IAC) interface as glue.
9. Fetching document metadata for an open document is pretty straightforward.
10. With automation you can get each word on a page. For each word on the page you can get its location as a quadrilateral. If you can use this info (and no other from the PDF) to decide what is a Bates Stamp, you might be able to handle them.
11. Acrobat is ABSOLUTELY NOT for use in a background process or on a server. It needs a user in front of it.
Copy link to clipboard
Copied
Thank you for the information:
In your response you mentioned:
"3. Acrobat developers all need the Acrobat SDK, a free download with thousands of pages of documentation"
Are you speaking specifically that the Acrobat SDK documentation is free or that the actual SDK interface is free? Because up to now I have been under the impression that you have to actually pay for the SDK interface. If I am wrong about this then please point me to the correct place where I can actually download the SDK interface which I think may be known as the SDK kit?
I tried calling Acrobat support and just got nowhere with them. They don't even seem to care about supporting the customer even if your paying for it. At least that has been my experience these past few weeks.
I am not trying to write an entire new interface for Acrobat or even write or create individual PDF files. I am simply trying to create an in-house database which lists all the 15000 pdf documents that exist on this project and allow easy search and retrieval of any specific or group of PDF documents, basically letting them weed out the documents they don't need by flagging or unflagging individual search entries. Essentially reducing a search that might originally return 100 likely candidates of which only maybe 15 might specifically apply for what they are looking. They can then check or flag those 15 entries, which also creates a named search request data file which they can save and retrieve allowing them to proceed in an organized manner at retrieving and reviewing those specific PDF documents that specifically apply for their needs.
Think of it this way. You build Widget Cars. You have been building them for 10 years. You have been creating and saving in PDF documents Engineering Details regarding all the past builds. Some part turns out to be defective. You search the 15,000 document database for all documents that mention this part. It returns 100 possible candidates. Now you can save this first search and then do successive narrower searches on just these 100 candidates. This narrows your search down to 15 documents that specifically apply to your search request. You can then save that search and browse and retrieve just those 15 documents. All your doing is searching a database that was created by programmatically reading the document properties fields while scanning each PDF files document header metadata properties.
Thanks again for your help.

Copy link to clipboard
Copied
datafused wrote
...
Are you speaking specifically that the Acrobat SDK documentation is free or that the actual SDK interface is free? Because up to now I have been under the impression that you have to actually pay for the SDK interface. If I am wrong about this then please point me to the correct place where I can actually download the SDK interface which I think may be known as the SDK kit?
...
The SDK doesn't have an interface. The Acrobat SDK documentation describes the interfaces of Adobe Acrobat.
Copy link to clipboard
Copied
The SDK is a download which contains mainly documentation. It is free, and easy to find with Google. Start here http://www.adobe.com/devnet/acrobat.html
The SDK interface is not a separate item. It is a part of Acrobat, in exactly the same way that, for example, Excel VBA is a part of Excel. You need to license Acrobat, and understand the difference between Acrobat and Reader.
It is no use calling the regular support. See my answer 2. There is a separate developer support, which has trained programmers. Never used them, but I understand it is $200 per question.
The Acrobat SDK, if studied long and carefully, should help you use Acrobat (but NOT ON A SERVER, reply 11) to retrieve the metadata of any single PDF file, reply 9. The code will be short but the study will be long, reply 4. It is no use just repeating that your usage case is simple.

Copy link to clipboard
Copied
I would suggest going a different route. There are PDF libraries out there that can be used in a stand-alone application (written in Java, for example), which is much better suited for this kind of task (ie, scanning an entire drive for PDF files and extracting data from all of them). It could even be used to extract the Bates numbers, if those appear somewhere in the file's metadata, or even in a known location on the pages. I've developed similar tools in the past.
 AdChoices
AdChoices