

Building search index through JavaScript no longer works: "Failed to open file"

Copy link to clipboard
Copied
I need to create a search index for some documents.
It seems like the JavaScript API does not support creating new search indices. For this reason, I have created an empty search index manually. I can use that to build the index like this:
// Global declaration
var oldDoc = null;
var buildIndexJob = null;
var buildIndex = app.trustedFunction( function(cDIPath, cExpr, bRebuildAll) {
app.beginPriv();
oldDoc = app.activeDocs[0];
buildIndexJob = catalog.getIndex(cDIPath).build("doc=oldDoc; " + cExpr, bRebuildAll);
app.endPriv();
});
// This is how I use the function
buildIndex('/C/Some/Path/My Index.pdx', 'app.alert("Done");', true);
For years, this has worked just fine. However, recently the code stopped working.
The log file reads like this:
Indexing 261 files
Extracting : C:\Users\....\SomeDocument.pdf
Fatal Search Engine Error : (-11) Failed to open file
Deleting files from current index
Error: Index build failedWhat is strange is that I can create the search index just fine through the Acrobat GUI.
Using Process Monitor, I don't see any problems like the PDF document not being accessible - so it's not clear to me which file Acrobat failed to open.
We use this code to generate search indices for different files. It could be related to the specific files, but it could also be due to an Acrobat update.
Any idea how I could debug this?


 8
Replies
8
8
Replies
8
Copy link to clipboard
Copied
I see you have recently fixed bugs related to the search index. Could that have broken my code? I'm running Acrobat Pro DC 2021.001.20145.

Copy link to clipboard
Copied
If protected mode is on, try switching it off.
Copy link to clipboard
Copied
Thanks for the suggestion. Protected mode was not on, only enhanced security was on.
I have switched off enhanced security, but that didn't make any difference, unfortunately.
Copy link to clipboard
Copied
Also the index rebuild does run for a couple seconds... So to me it doesn't seem like an issue with permissions.
In case it matters, I see an error message like this in the log:
Could not open document : C:\Users\...\docs\SomeDocument.pdf-Print.joboptionsCould that be the issue?
Copy link to clipboard
Copied
Ok, it doesn't seem like that's the issue. When I remove SomeDocument.pdf from the directory, the error message about the -Print.joboptions file disappears, but the build still fails.
I have even tried rebuilding the exact same index, for the exact same files now, once through the GUI and once using my script.
Using the GUI, I get the same error messages at the beginning, but then there are many lines that start with "Extracting: <filename>" and the index is rebuilt.
When I do the exact same thing using my script, I get only one line of "Extracting: <filename>" and then the aforementioned error message: "(-11) Failed to open file"
It seems likely that it's about permissions, but the code is already running with elevated permissions...?
Copy link to clipboard
Copied
We are using .NET to invoke the JavaScript. I believe the .NET code is accessing some COM/ActiveX library.
But I don't think that's relevant as I get the same error when I run the JavaScript from the JavaScript console inside Acrobat.
We are using Acrobad DC Pro (32-bit), version 2021.001.20145.
In case that helps...

Copy link to clipboard
Copied
Hi,
Thanks for your bug report. Could you please try the registry under Solution#2 mentioned in the https://helpx.adobe.com/acrobat/kb/unable-to-search-text-in-pdf.html and let us know if the workaround is working for you?
Thanks & Regards,
Adobe Acrobat DC Desktop Team.
Copy link to clipboard
Copied
Hi @adeep93
Thank you very much for getting back to me.
I first had to create the "FeatureState" key under "HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Adobe\Adobe Acrobat\DC\" as it didn't exist.
I then added the "bFallbackOnix32" DWORD value as described.
Then I ran the script again. Now the index rebuilding process window shows:
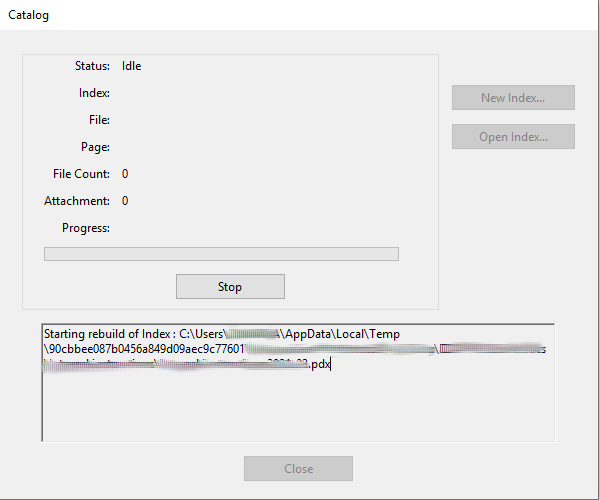
"Starting rebuild of Index : C:\Users\...\My index file.pdx"
But the process never even seems to start. It is stuck on "Status: Idle", as you can see in the screenshot.
Before, the process was successfully counting all files, and then it would fail upon trying to index the first file (while it was working fine when doing the same operation through the GUI).
With the registry fix in place, it does not even count the files.
 AdChoices
AdChoices
{kind=link}