 Adobe Community
Adobe Community
Gray overlay

Copy link to clipboard
Copied
I work for the Wisconsin State Journal. We subscribe to a service that archives past issues. We've found recently that many of these PDFs have a gray overlay, aren't as sharp as they used to be, and are giant files (21 MB versus 3 or 4 typically). I assume it has something to do with how they're scanned in, but is there a way, after the fact, that we can remove what appears to be a screen over the pages? When I rapidly re-size the files (Control+wheel), the gray disappears for half a second and I see clean black-and-white text, so it must be some sort of layer. We've tried working with the folks who scan the documents to see if the problem is being caused on their end, but in the meantime can we do something as the end users?
Here are two snips: The first shows how the pages used to look, and should look; the second shows the gray overlay.




 10
Replies
10
10
Replies
10

Copy link to clipboard
Copied
This looks like the first image was scanned in monochrome mode (black and white pixels only), whereas the second image was scanned in grayscale mode (e.g. 256 different levels of gray from white to black). This requires a lot more data than a black&white scan. You can very likely enhance the scans in Acrobat Pro using the "Enhance Scan" feature, which can create smaller files, and may be able to get rid of the background.

Copy link to clipboard
Copied
I concur with Karl completely.
Enhancing the scans after-the-fact could be very painful. It is better to handle this at scan time.
That having been said, one of the problems with such scanning is that if you want to maintain any imagery, unless your scans can get down to the halftone dot level precisely, you pretty much need grayscale (or for original color documents, full color) scanning. The trick is to calibrate the scanner such that you have appropriate brightness and contrast settings that eliminate the gray (or colored) backgrounds. Eliminating such backgrounds also leads to much better file compression, i.e. small PDF file sizes.
- Dov
Copy link to clipboard
Copied
That's very helpful, Karl. So where do I find the "Enhance Scan" feature? I agree with Dov, that the problem is in the scanning. We're working with the folks who do that to see if we can get it straightened out. But in the meantime, anything I can do to fix the PDFs I have would be better than nothing.
Copy link to clipboard
Copied
In Acrobat DC Pro, you can find it on the "Right Hand Pane", or on the Tools tab. If you don't see it right away, just type in "scan" into the tool search field.
Load the document into Acrobat, then bring up the tool and select Enhance>Scanned Document. You should now see a "Settings" button that allows you to modify the way the document gets processed. Select the "Filters" option to remove the background, and then use the "Adaptive Compression" option to get a smaller file.
Copy link to clipboard
Copied
Sorry: I should have said I'm using Adobe Acrobat X Pro. Am I in the wrong forum? Anyway, I can't find where the "enhance scan" feature is in Acrobat X Pro.
Copy link to clipboard
Copied
No, you are in the right forum. It's just that if no other version number is given, I assume it's the latest. In Acrobat X Pro, you can find this function as Tools>Document Process>Optimize Scanned PDF
Copy link to clipboard
Copied
Okay. Me again. So these PDFs have already been OCR'ed, so when I try Optimize Scanned PDF -- even though what I want to do is drop out the background and not affect the text -- I get an error message that the page contains renderable text. I tried saving it as a JPEG then re-saving it as a PDF. When I optimize that, I can sharpen the text, but the gray background remains.
I am really curious though about this process when I'm zipping down the size of the document through zoom (again, with Control+wheel), the whole thing pops out in beautiful black and white for, like, half a second. I wish I could freeze it in time then, but I can't. But that suggests to me that Adobe thinks this whole grayscale is a layer. Is there another method to permanently peel that layer off? When I zoom in and out on color PDFs, they don't briefly turn black and white like this one does.
Copy link to clipboard
Copied
This is very likely not a "layer" (especially if you saved to an image file and then re-imported into Acrobat in order to run OCR), but a side effect of using adaptive compression. This compression method is trying to analyze your document and then it will take the image apart and compress different pieces differently to get the smallest possible file size. It could be that it is separating the gray background from the rest.
Did you turn "background removal" on? You may have to turn it to "High" to see good results. That should remove the gray background (or at least make it a lot less obvious). Also, you should never save a document that is not a real photographic image as JPEG - you will end up with compression artifacts. Use a high-resolution (e.g. 600dpi) TIFF image instead.
The sample image you posted is not good enough to run OCR, but when I run it through the scan optimization with background removal set to high, I get this:

Keep in mind that this is still a grayscale image, and not a monochrome image, so it will still use up more space than a true monochrome document, but as you can see, the background is gone (and this was done with Acrobat X).
Copy link to clipboard
Copied
Thanks again, Karl; you've been very patient. I did try running "Optimize Scanned PDF" and turning background removal to high, but I get an error message that the "Page contains renderable text" and so it doesn't optimize. I get this message whether the OCR options box is checked or unchecked. It's like it's telling me that it can't optimize the document unless I also want to run OCR (which I don't). Here's what's in my optimize window. Am I doing something wrong?
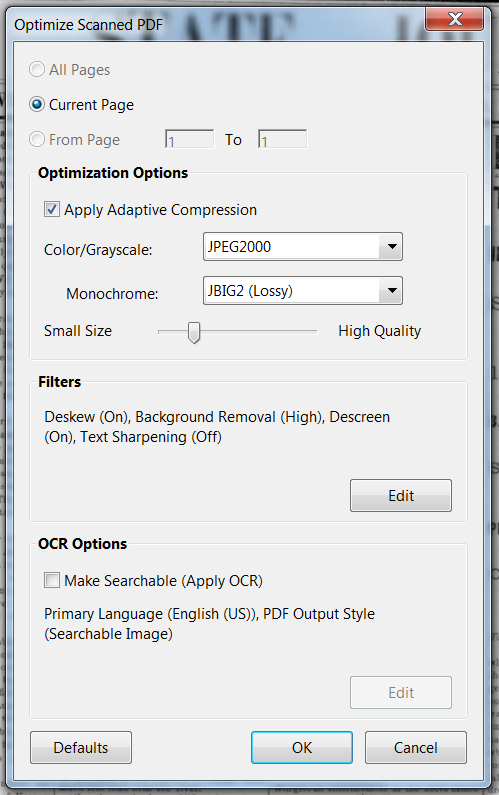
Copy link to clipboard
Copied
Older versions of Acrobat would not allow you to run OCR on a document that already contained "renderable text". You mentioned that you tried the method of going via an image file. You would have to do that in order to run OCR again (but now with the modified options to remove the background). You could also upgrade to Acrobat DC, which no longer prevents you from running OCR if the document was already OCRed.
 AdChoices
AdChoices