

- Home
- Acrobat SDK
- Discussions
- Re: Is it possible to Extract Text from the specif...
- Re: Is it possible to Extract Text from the specif...
Is it possible to Extract Text from the specific area exactly?

Copy link to clipboard
Copied
I been trying use Adobe Acrobat SDK to extract text for many days ...
it is OK for me to get the whole text of the page , But those text basically is not ordered.
Normally content comes like top content , footer content , Main content
We don't get those text like we see those words orderly.
Another reason why I am asking is , we have used another 3rd party tools like PDFbox
With their tools , giving the specific area , it return text successfully . And unfortunately , this tools doesn't read pdf successfully.
And , adobe acrobat SDK read all pdf files well .
Now this is what I plainly to do

Giving a specific area , and return the text . Just Like we read pdf files , we select it and copy it.
Firtst . Is it possible to do that ?
Second . I used pdfDoc.CreateTextSelect(pageNumber, pdfRect);
This function return text which is not I want when those texts are in form or image .
I was giving the smaller pdfRect to CreateTextSelect function , but it finally return its own BoundingRect like the bigger one.
And Also , function return texts like : DQM0 L VDDQDQ8VSSVDDDQ7VSSQ M VSSQDQ10DQ9DQ6DQ5VDDQ N VSSQDQ12DQ14DQ1DQ3VDDQ P ...
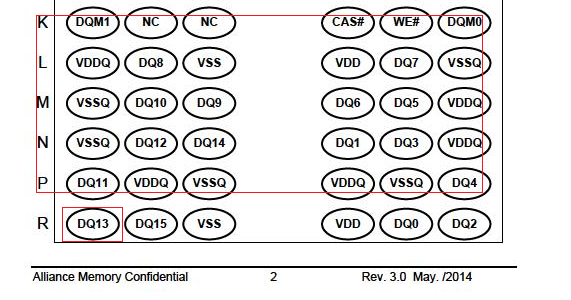
Correct me if I am wrong , Is it possible to do that ? or Am I using the wrong method?


 17
Replies
17
17
Replies
17

Copy link to clipboard
Copied
Try JavaScript GetPageNthWord and GetPageNthWordQuads, though “order” is a slippery and uncertain concept for PDF text.
Copy link to clipboard
Copied
Hi , thank you for replying .

this is what I get contexts by using AcroPDTextSelect
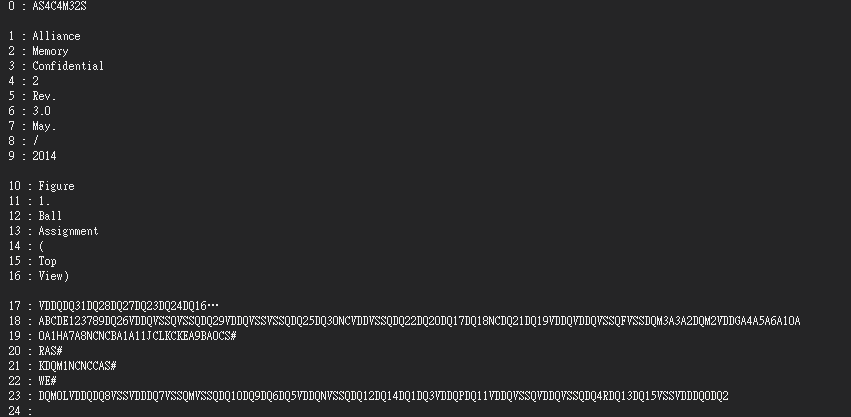
this , is by using GetPageNthWord and GetPageNthWordQuads
I still don't get those content in from split .
and even I get this contents , I can't get where these word were suppose to be.
so this is why I am wondering if there is a function , or a way to get contents in a specific area
Copy link to clipboard
Copied
No but you can check the quads to exclude text outside the area.
Copy link to clipboard
Copied
Thanks for replying .
Yes , now I get the 8 point of the rectangle information.
And I use an Array to store the information and adjust these points. Thank you so much .
How do I use these adjusted points to send back to the function , and get the text that I want?
Copy link to clipboard
Copied
You cannot send the points to the function. Instead you will see all words but you can ignore the words which are outside your target area.
Copy link to clipboard
Copied
now I have already process Image to get the circle sharp , where text is in it.
In the picture up there , like I want to get VDDQ
and I use rectangle to select the range , before the function goes , I set it all up.
But it return string like "VDDQDQ8VSSVDDDQ7VSSQ" , I don't get to know the text in advance
This is why Im asking if there is another way to get context in specific area .
Thank you still !
Copy link to clipboard
Copied
You must do what I said: get each word and check its quad. why Does this not work?
Copy link to clipboard
Copied
ok , maybe it wasn't clear.
https://drive.google.com/open?id=1T9_1hdp1e1DPU4VmLADdW36qGW-8k7qn
this is the pdf file.
And of course I did some implements by GetPageNthWord and GetPageNthWordQuads with it
totally , It return (numWords 😃 24 on that page by GetPageNthWord .


I expected these word return like 1 2 3 ... 7 8 9
A DQ26 DQ24 ....
but the face isn't like that , as the output shows , it return VDDQDQ31DQ28DQ27DQ23DQ24DQ16… which is not proper for me.
I found that those coordinate combine as a rectangle which seems relative to the content.
And TextStripper in apache PDFBox tool is able to extract the contexts in circle shape with proper range.
I wanna know what is wrong with it , why can't I implement 3rd party tools' function with Acrobat SDK?
Copy link to clipboard
Copied
The reason you have limited functionality is you are using the limited functionality APIs…
If you want more power and capabilities, use the Plugin APIs instead of the IAC APIs.

Copy link to clipboard
Copied
On the third page the function getPageNumWords returns the value 129
So there are 129 words on this page.

Copy link to clipboard
Copied
I get the same thing number of words as Bernd and the pin names in the ovals extract individually.
What version of Acrobat are you using?
Use the Acrobat JavaScript Reference early and often
Copy link to clipboard
Copied
Really? After license , I have installed Adobe Acrobat Pro DC.
And I add Adobe + Adobe Acrobat 10.0 Type Library to references in my project
Here is my code and suppose I have input the right pageNumber
It return 24 words only .
Copy link to clipboard
Copied
Execute this.getPageNumWords(2); in the Acrobat console and you will get 129.
Copy link to clipboard
Copied

sorry guys , I really didn't get the same words like you guys did.
I did my project with C#
I'm really new to this area , I know there are many layers in pdf.
Am I really on the wrong direction just like lrosenthsaid?
Copy link to clipboard
Copied
The PDF link is not public. So I have no idea what you expect to see.
Copy link to clipboard
Copied

Copy link to clipboard
Copied
1. We cannot tell from fragments of code, what do you set pageNumber to?
2. Please run the one line in the console suggested above, what do you get?
Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices