
Is it possible to Extract Text from the specific area exactly?
I been trying use Adobe Acrobat SDK to extract text for many days ...
it is OK for me to get the whole text of the page , But those text basically is not ordered.
Normally content comes like top content , footer content , Main content
We don't get those text like we see those words orderly.
Another reason why I am asking is , we have used another 3rd party tools like PDFbox
With their tools , giving the specific area , it return text successfully . And unfortunately , this tools doesn't read pdf successfully.
And , adobe acrobat SDK read all pdf files well .
Now this is what I plainly to do

Giving a specific area , and return the text . Just Like we read pdf files , we select it and copy it.
Firtst . Is it possible to do that ?
Second . I used pdfDoc.CreateTextSelect(pageNumber, pdfRect);
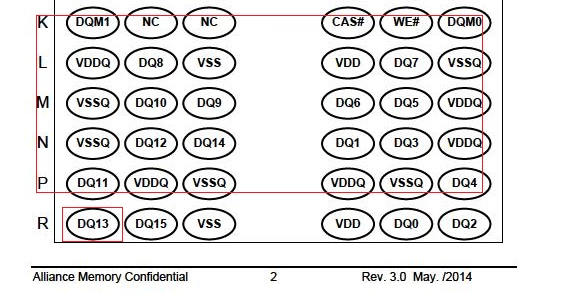
This function return text which is not I want when those texts are in form or image .
I was giving the smaller pdfRect to CreateTextSelect function , but it finally return its own BoundingRect like the bigger one.
And Also , function return texts like : DQM0 L VDDQDQ8VSSVDDDQ7VSSQ M VSSQDQ10DQ9DQ6DQ5VDDQ N VSSQDQ12DQ14DQ1DQ3VDDQ P ...
Correct me if I am wrong , Is it possible to do that ? or Am I using the wrong method?