


Copy link to clipboard
Copied
I have strings like this
PGH2019AprilPA73-01.docx
PGH2019AprilPA73-0.docx
PGH2019AprilREC73-0.docx
I need to extract the number 73 from the string.
The number could be 2 or 3 digits long, like 99 or 101
EG: PGH2019AprilPA99-01.docx or PGH2019AprilPA101-01.docx
The number is always right before the -0
PGH2019AprilPA73-01.docx
PGH2019AprilPA73-0.docx
PGH2019AprilREC73-0.docx
How would I extract this 2 or 3 digit number that precedes the -0?


 1 Correct answer
1 Correct answer

FIXED IT. 
In the first backreference, replace \w+ with [a-z]+ and VOILA!
V/r,
^ _ ^
UPDATE: Here is the code I used for my "homework".
...<cfscript>
fileNames = [];
arrayAppend(fileNames,"PGHA2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES101-0.docx");
 20
Replies
20
20
Replies
20
Copy link to clipboard
Copied
Again, RegEx to the rescue. 
Assuming that the names will always be in the same format:
<cfset filename = "PGH2019AprilPA73-01.docx" />
<cfset thisNumber = REreplaceNoCase("(\w{3}\d{4}\w+)(\d{2,3})(-01?\.docx)",fileName,'\2','all') />
<cfoutput>#thisNumber#</cfoutput>
Not tested.
HTH,
^ _ ^
Copy link to clipboard
Copied
EXPLAINED:
(\w{3}\d{4}\w+)
Parenthesis indicate first backreference. \w{3} is three letters, \d{4} is four numbers, \w+ is one or more letters.
(\d{2,3})
Parenthesis indicate second backreference. \d{2,3} is two or three digits.
(-01?\.docx)
Parenthesis indicate third backreference. -0 is as expected, -0, 1? means zero or one instance of "1", \.docx is an escaped period (period, alone, in RegEx is wildcard for everything) followed by docx.
RegEx replace using this mask to remove first and third backreferences, leaving only the second backreference.
HTH,
^ _ ^
Copy link to clipboard
Copied
UPDATE: I got the order incorrect. It's not (regex mask, string, substring, one/all), it's (string, regex mask, substring, one/all).
Flip the first two arguments around.
HTH,
^ _ ^
Copy link to clipboard
Copied
Wolf
When I do this,
I get
(\w{3}\d{4}\w+)(\d{2,3})(-01?\.docx)
as thisnumber
Actually I get (\w{3}\d{4}\w+)(\d{2,3})(-01?\.docx) no matter what variable I use
Copy link to clipboard
Copied
See my last post. I accidentally reversed the regex mask and string. Switch the two around and try again.
V/r,
^ _ ^
Copy link to clipboard
Copied
Wolf,
OK were very close here.
It looks like the file names can go like this.
More variation than I indicated earlier.
So your Regex works for some and not others
- PGHA2019MarchSDRR99-0.docx
- PGHA2019MarchRES73-0.docx
- PGHAB2019MarchREC73-01.docx
- PGHAB2019MarchREC73-0.docx
- PGHAB2019MarchCA73-02.docx
- PGHAB2019MarchCA73-01.docx
- PGHAB2019MarchCA101-0.docx
Knowing this is regex still the answer?
The number I need is still the 2 or 3 digit number to the left of -0.
Copy link to clipboard
Copied
I formed the RegEx mask the way I did because all of your examples included either -0 or -01. Since it can be 1 or any other number, then the following should work.
<cfset filename = "PGH2019AprilPA73-01.docx" />
<cfset thisNumber = REreplaceNoCase("(\w{3}\d{4}\w+)(\d{2,3})(-0\d{1}?\.docx)",fileName,'\2','all') />
<cfoutput>#thisNumber#</cfoutput>
This is assuming that the number immediately following the - will always be 0. If it is not, then that should be changed to reflect such.
V/r,
^ _ ^
Copy link to clipboard
Copied
This works great except for these vars (2 digits after the dash -)
PGHA2019MarchSDRR73-01.docx
PGHA2019MarchSDRR73-02.docx
But does not when the var is this (1 digit after the dash -)
PGHA2019MarchSDRR73-0.docx
Here is the code I have
<cfset thisNumber = REreplaceNoCase(fileName,"(\w{4}\d{4}\w+)(\d{2,3})(-0\d{1}?\.docx)",'\2','all') />
Copy link to clipboard
Copied
Okay, now you're changing the format to have four letters at the beginning. Your original example was three. So, which is it?
<cfset filename = "PGHa2019AprilPA73-01.docx" />
<cfset thisNumber = REreplaceNoCase("(\w{3,4}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)",fileName,'\2','all') />
<cfoutput>#thisNumber#</cfoutput>
The above should match:
3 or 4 letters followed by
4 numbers followed by
1 or more letters
2 or 3 numbers
A hyphen followed by
1 or 2 numbers followed by
.docx
V/r,
^ _ ^
UPDATE: I forgot to add indicators for beginning of string and end of string. And trimming the filename to make sure there are no spaces at beginning and end of filename.
REreplaceNoCase("^(\w{3,4}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)$",trim(fileName),'\2','all')
Copy link to clipboard
Copied
Sorry about the vars changing
So everything works except when the var is like this ( 3 digits before the dash-)
PGHA2019MarchSDRR101-01.docx
This is my code
<cfset thisNumber = REreplaceNoCase(fileName,"(\w{3,4}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)",'\2','all') />
Copy link to clipboard
Copied
Is there a chance that the filename has whitespace either before or after? Place trim() around fileName to eliminate any whitespace.
That's the only thing I can think of, because \d{2,3} will match either a two- or three-digit number.
Just curious. How are you acquiring the filenames?
V/r,
^ _ ^
Copy link to clipboard
Copied
Here is the file list
All works well except when the number preceding the dash is 3 digits
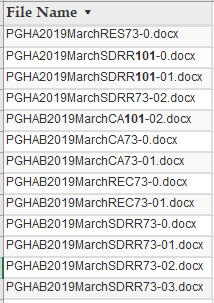
This is the current code I am using.
<cfif LEFT(filename,5) EQ 'PGHAB'>
<cfset thisNumber = REreplaceNoCase(trim(fileName),"(\w{4,5}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)",'\2','all') />
</cfif>
<cfif LEFT(filename,4) EQ 'PGHA'>
<cfset thisNumber = REreplaceNoCase(trim(fileName),"(\w{3,4}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)",'\2','all') />
</cfif>
Copy link to clipboard
Copied
Your code is first checking to see if the filename begins with PGHAB, then it checks to see if it's PGHA in the same iteration. If it begins with PGHA, both will apply.
You shouldn't be using a conditional because the RegEx mask will work for both scenarios (4 or 5 letters as indicated by the italic in the code below). Include ^ to indicate start of string, and $ to indicate end of string.
<cfset thisNumber = REreplaceNoCase(trim(fileName),"^(\w{4,5}\d{4}\w+)(\d{2,3})(-\d{1,2}?\.docx)$",'\2','all') />
Or, if there are filenames that do NOT begin with PGHA, then you can use a conditional for that. But that's it.
If this still isn't working, then there is something else you haven't mentioned that is being applied.
V/r,
^ _ ^
Copy link to clipboard
Copied
Okay.. I'm playing with this in my DEV environment. I can see that it's only returning two of the digits if there are three. I'll see what is going on and get back to you.
V/r,
^ _ ^
Copy link to clipboard
Copied
Yes sir. exactly what I get
Copy link to clipboard
Copied
FIXED IT.
In the first backreference, replace \w+ with [a-z]+ and VOILA!
V/r,
^ _ ^
UPDATE: Here is the code I used for my "homework".
<cfscript>
fileNames = [];
arrayAppend(fileNames,"PGHA2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES111-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHAB2019MarchRES73-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES101-0.docx");
arrayAppend(fileNames,"PGHA2019MarchRES73-0.docx");
</cfscript>
<cfoutput>
<cfloop index="idx" from="1" to="#arrayLen(fileNames)#">
<cfset thisNumber = REreplaceNoCase(trim(fileNames[idx]),"^(\w{4,5}\d{4}[a-z]+)(\d{2,3})(-\d{1,2}\.docx)$","\2","all") />
#idx# - #thisNumber#<br /><br />
</cfloop>
</cfoutput>
Copy link to clipboard
Copied
Excellent. You deserve 2 stars for this one. I appreciate your diligence!
Copy link to clipboard
Copied
Thank you for marking my answer as correct. I appreciate it, and I'm sure some other user with the same request will, too.
V/r,
^ _ ^
Copy link to clipboard
Copied
OOOOOH! Check this out. (I'm such a geek, sometimes.) ArrayMap()!!!! W00t, w00t!!
<cfoutput>
<cfscript>
ArrayMap(fileNames, function(idx,index){
thisNumber = REreplaceNoCase(trim(idx),"^(\w{4,5}\d{4}[a-z]+)(\d{2,3})(-\d{1,2}\.docx)$","\2","all");
writeOutput(index & " - " & thisNumber & "<br />");
}
</cfscript>
</cfoutput>
OR (this is more like JavaScript)
<cfoutput>
<cfscript>
fileNames.map(function(idx,index){
thisNumber = REreplaceNoCase(trim(idx),"^(\w{4,5}\d{4}[a-z]+)(\d{2,3})(-\d{1,2}\.docx)$","\2","all");
writeOutput(index & " - " & thisNumber & "<br />");
}
</cfscript>
</cfoutput>
TAH-DAH!!! Same thing. (I _LOVE_ ColdFusion!)
V/r,
^ _ ^
UPDATE: Only works in CF11 or later. So, sorry if you're using CF10 or earlier.
Copy link to clipboard
Copied
In case anyone needs clarification on this (as, apparently, I do), according to Mozilla Developer Network (MDN), \w is the equivalent of [A-Za-z0-9_] (all upper-case letters, all lower-case letters, all integers, and underscore).
I made the mistake of thinking \w was strictly letters, not alphanumeric. So my original mask was seeing "March101" as "March1" and "01". When I changed the mask, replacing \w with [a-z] (I didn't need A-Z because of the "NoCase"), the RegEx engine then correctly made the distinction of "March" and "101".
V/r,
^ _ ^

 AdChoices
AdChoices