Answered
PDFファイルからしおりのタイトルをテキストで抽出
PDFファイルで作成したしおりの一覧をテキストで抽出する方法をご教示いただきたいです。
以前はPDFlibというプラグインを使っていたのですが、現在使用不可のため、代替方法を探しております。

PDFファイルで作成したしおりの一覧をテキストで抽出する方法をご教示いただきたいです。
以前はPDFlibというプラグインを使っていたのですが、現在使用不可のため、代替方法を探しております。
お使いの環境がわからないのでアレですが
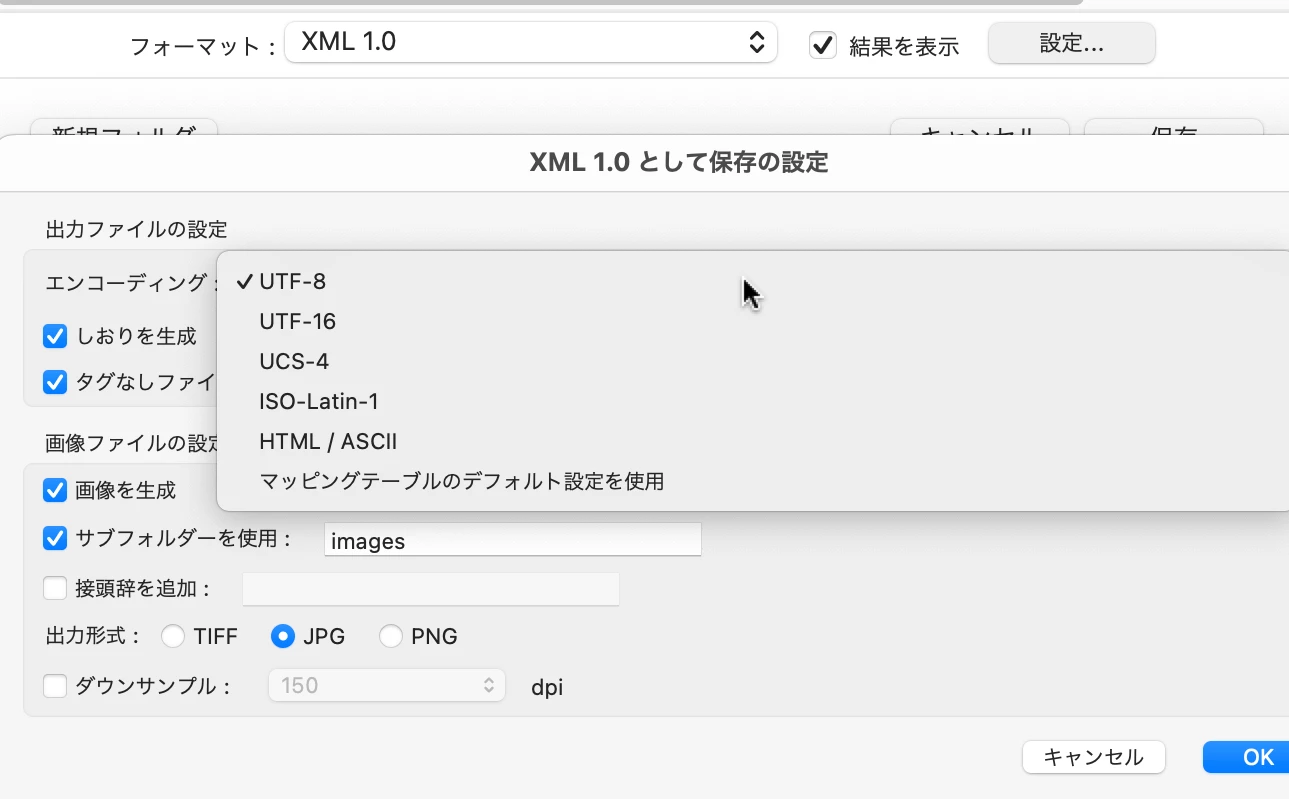
別名保存でXML 1.0で保存すれば、比較的簡単にテキスト情報にアクセスできます
お試しを
ワンポイントとしては
別名保存時の設定から
UTF-8を指定した方が
テキスト取得時の編集が楽かもしれません
業務で利用の場合で職場に情報処理担当の方がいる場合
出力されたXMLから正規表現等で『テキストのみ』に変換するのは比較的簡易ですので
『正規表現ってのでXMLをテキストのみにしたいんですが教えてください』的に相談してみると良いかもしれません
参考まで
Already have an account? Login
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
