
Question
Cannot extract the embedded font 'GlyohLessfont'. using Acrobat Reader DC Version 2020.009.20074
Dear All
i am facing the issue on the PDF file which is created by scanning and done OCR while opening the file I get 'Cannot extract the embedded font 'GlyohLessfont'' message. I am using Acrobat Reader DC Version 2020.009.20074, I also tried to re-install but the issue is the same. the same PDF file is opening without any issue in Foxit PDF reader. even I tried to do the same with other scan document issue is same. below are the screenshots of the message, properties(fonts tab), and version of Acrobat.
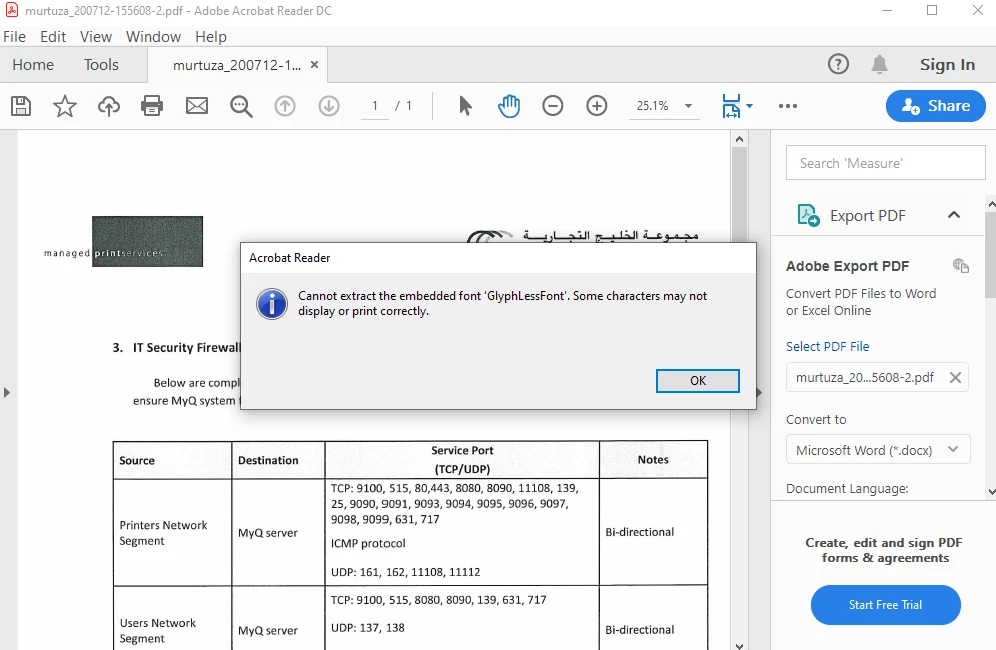
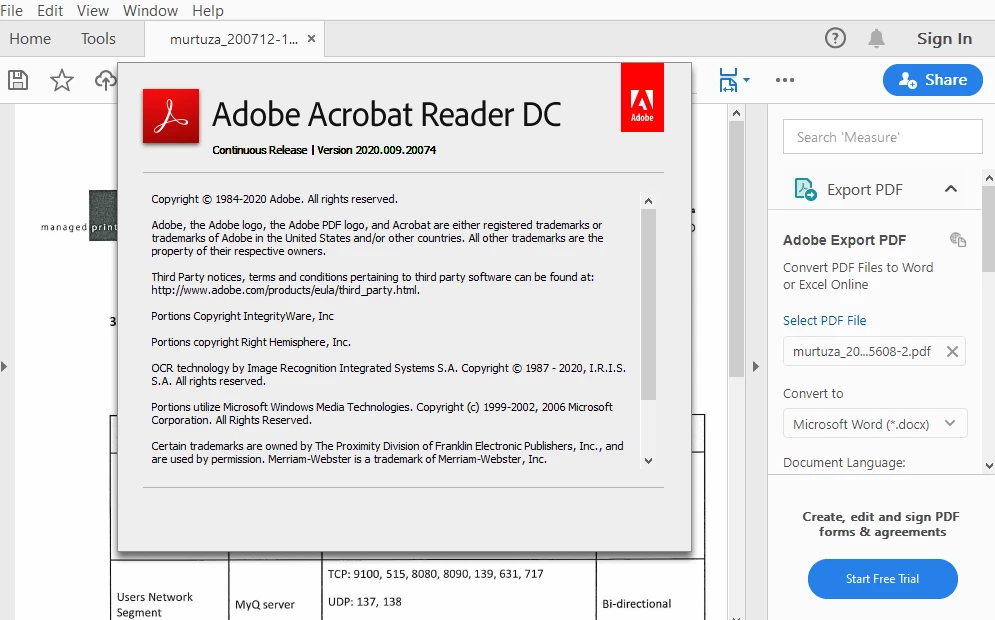
Sample file link
https://www.dropbox.com/s/js59c59exvxxzuu/sample%20file.pdf?dl=0
waiting for reply to resolve this issue.