
Question
Issue in PDF search
Hi,
We have an issue with a pdf document published using one of our tools. In this particular document, search is not working properly. Below are the screenshots of the issue. To reproduce the problem, you can simply search for the string "AUX_CLK_IN" and see that the search results show only 1 output whereas the string is present twice in the page.
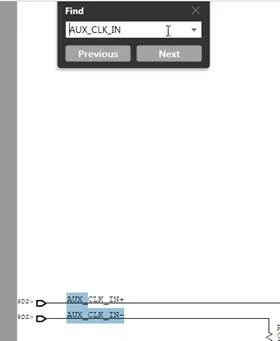
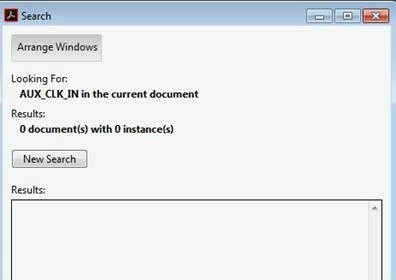
Could you please let us know why this is happening and what tools one can possibly use to find out details in the document to debug the issue.
P.S. I could not find a way to attach the sample pdf file, need help regarding the same.
Regards
Monidipa Sarkar