Question
Extract PDF - Extraction consistency
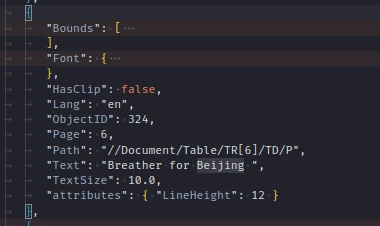
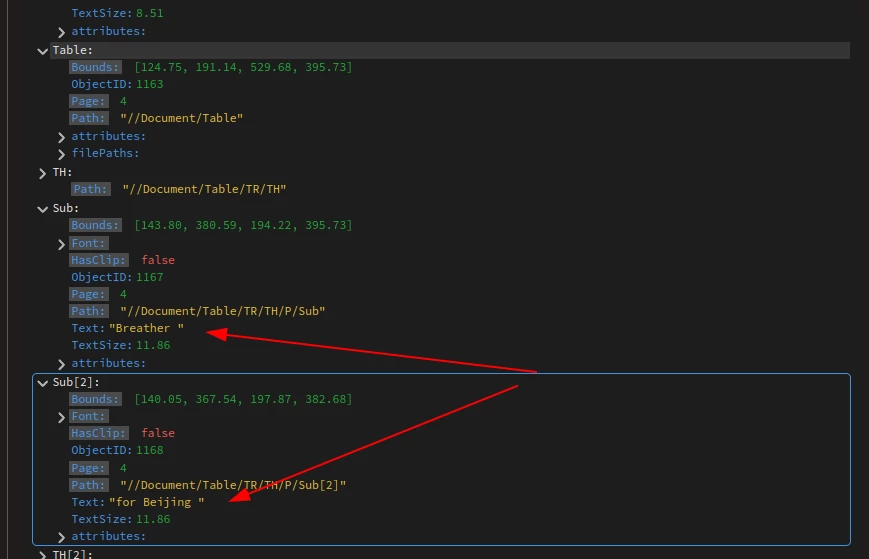
Reviewing the content output, I have found discrepancies between the one in the JSON and the output from https://documentservices.adobe.com/dc-visualizer-app/index.html for the same PDF file. Is the same engine being used in both cases?