Question
Getting started with PDF Extract
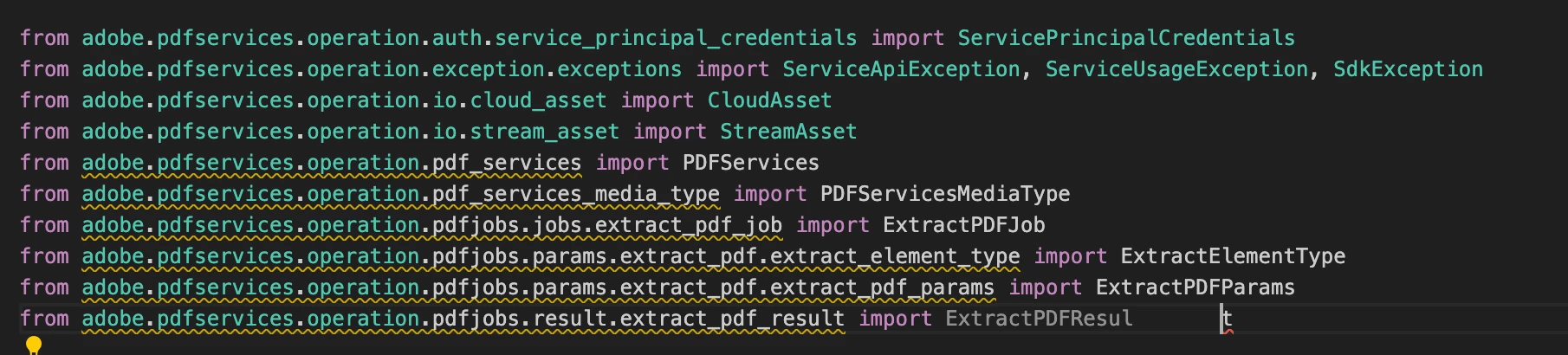
I'm trying to get started with PDF Extract using info on the site here: https://developer.adobe.com/document-services/docs/overview/pdf-extract-api/quickstarts/python/
However many of the dependancies have yellow lines underneath and say they could not be resolved?
I've followed the set up instructions step by step and not really sure what I'm doing wrong. I've downloaded the sdk using "pip install pdfservices-sdk"