Answered
Power Automate Split and Merge the split output array
Hi Community members,
Adobe Team, Thank you so much for this wonderful service made available for Power Automate.
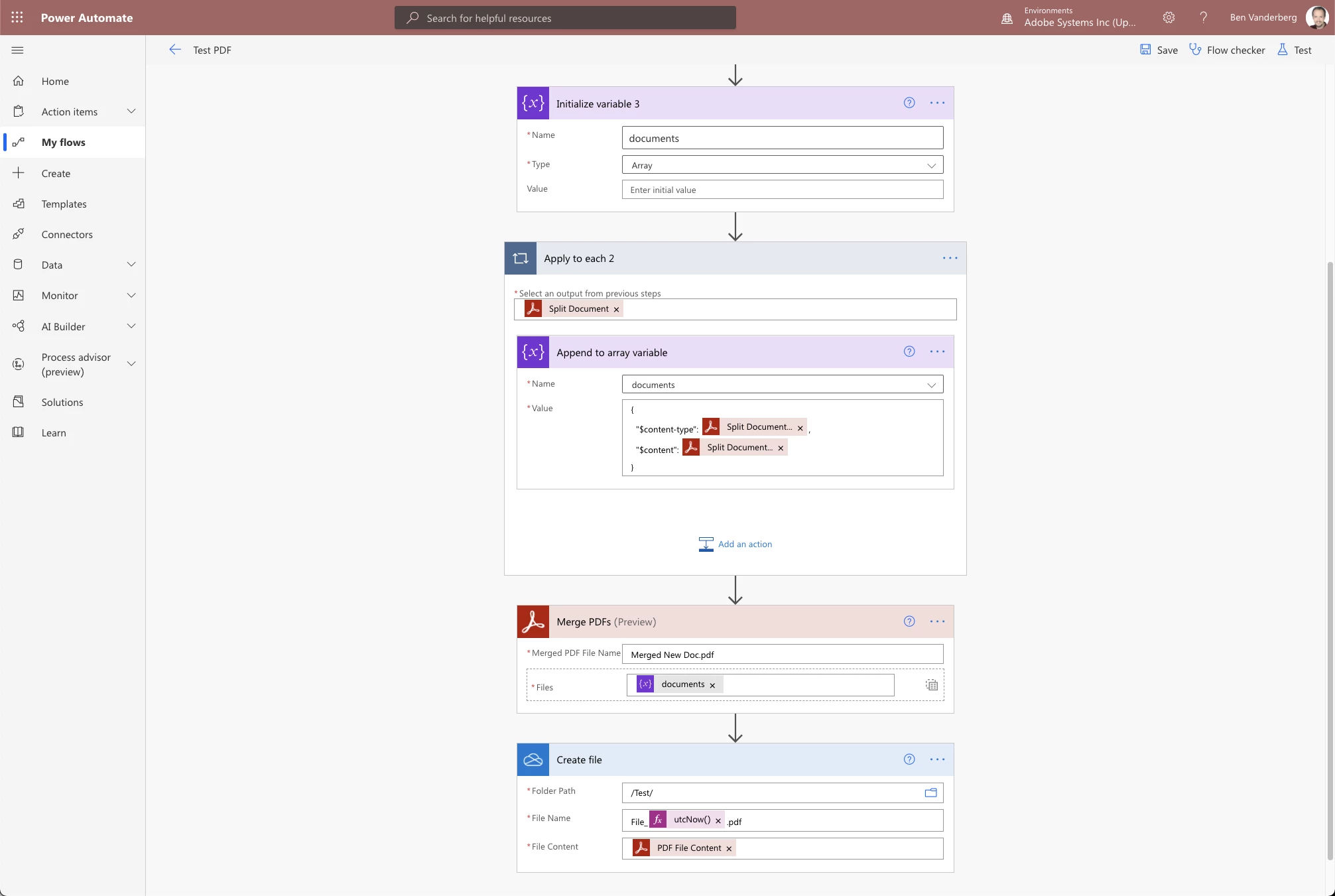
I have a specific requirement to merge number of outputs(dynamic page count) from Split module. Tried all the possible ways by providing the possible configurations on Merge module, but failed to generate output.
Please help!