
Question
Request for improvement: Cannot extract Japanese text from table, but Acrobat Pro DC can.
Hi, I would like to extract English and Japanese text from tables in PDF, which is made by scanning printed paper.
Original PDF:
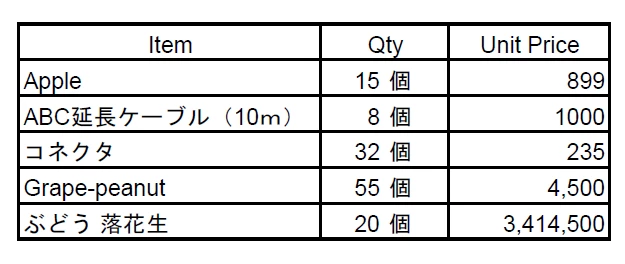
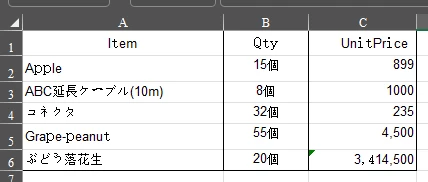
When I use Acrobat Pro DC(Convert to xlsx), the output quality is good.
But when I use Adobe PDF Services API(extract_text_table_info_figures_tables_renditions_from_pdf.py), I get garbled text for the Japanesse text.
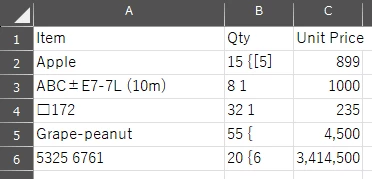
I know the API is currently optimized for English language content.
But is it possible to improve this API to the quality of Acrobat Pro DC?
Beacuse I need to convert many PDFs, so I need CLI solution.
I attach the original Excel and PDF file, so please use these as test data.
Thank you.
