Answered
Acrobat/Reader CosStringValue returns trash when file name consist of russian letters
Hello, I try to retrieve attachment name but in case when attachment name contains russian letters adobe functions returns trash.
Usage:

ACCB1 ASBool ACCB2 AdobePluginHelper::GetEmbeddedFiles(CosObj obj, CosObj value, void *clientData)
{
auto adobe = CAdobePlugin::GetAdobeMethods();
auto attachedFiles = (vector<string>*)clientData;
PDFileAttachment fileAttachment = adobe->PdFileAttachmentFromCosObj(value);
//Grab the file's name using the cos object dictionary and the File Specifcation String key.
ASTCount len = 0;
std::string sFileName(adobe->CosStringValueFromCosObject(adobe->CosDictObjGet(value, adobe->AtomFromString("F")), &len));
if (!sFileName.empty())
{
attachedFiles->push_back(sFileName);
}
return true;
}
void AdobePluginHelper::GetAttachedFiles(PDDoc document, vector<string>& attachedFiles)
{
auto adobe = CAdobePlugin::GetAdobeMethods();
PDNameTree nameTree = adobe->PdDocGetNameTree(document, adobe->AtomFromString("EmbeddedFiles"));
if (adobe->PdNameTreeIsValid(nameTree))
{
//Apply the enum function to the nametree so it can iterate through, extracting the attachments.
adobe->PdNameTreeEnum(nameTree, &GetEmbeddedFiles, &attachedFiles);
}
}char* Implementation::Adobe::CosStringValueFromCosObject(CosObj obj, ASTCount* nBytes)
{
return CosStringValue(obj, nBytes);
}CosObj Implementation::Adobe::CosDictObjGet(CosObj dict, ASAtom key)
{
return CosDictGet(dict, key);
}
Original:
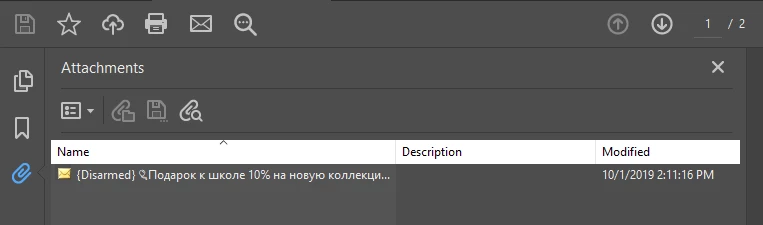
In other cases it works fine.