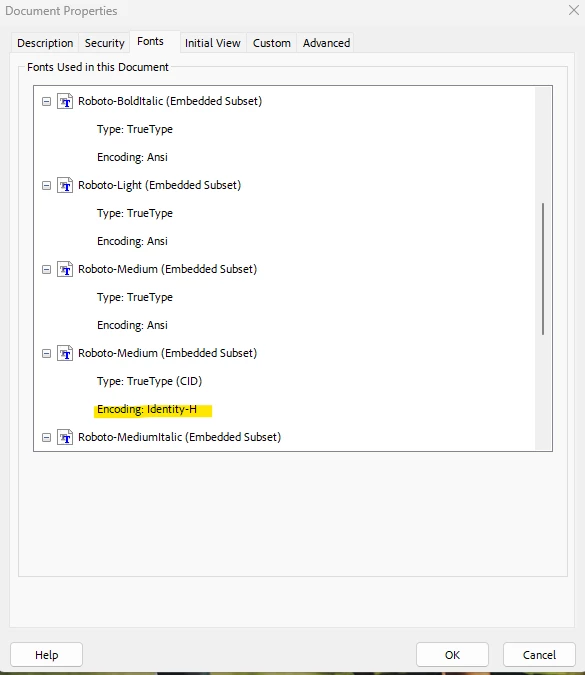
Locate instance of text using a specific font encoding within acrobat (h-encoding)
I'm looking to locate the one, or multiple, instance(s) of this h-encoded font (below image is highlighted, in PDF document properties > fonts). It is a multipage document.
We are sending PDFs to a new contractor. That contractor is using their own in-house PDF parser that I believe has an issue reading this encoding. As Dov Isaacs said in his comments regarding Bing mailroom, a similar situation, it shouldn't be an issue reading this but I've seen a few people on github and other places having trouble parsing text that is h-encoded.
Solution: Remove all h-encoded text
How: Locate the text that is h-encoded
Is there an easy way to locate text in a pdf document based on encoding? I'm not that familiar with acrobat, I mainly program for photoshop/illustrator. I tried google dorking / searching chatgpt with no luck.
Thank you