Question
Table of Contents header numbers being read as untagged images when converting from Word
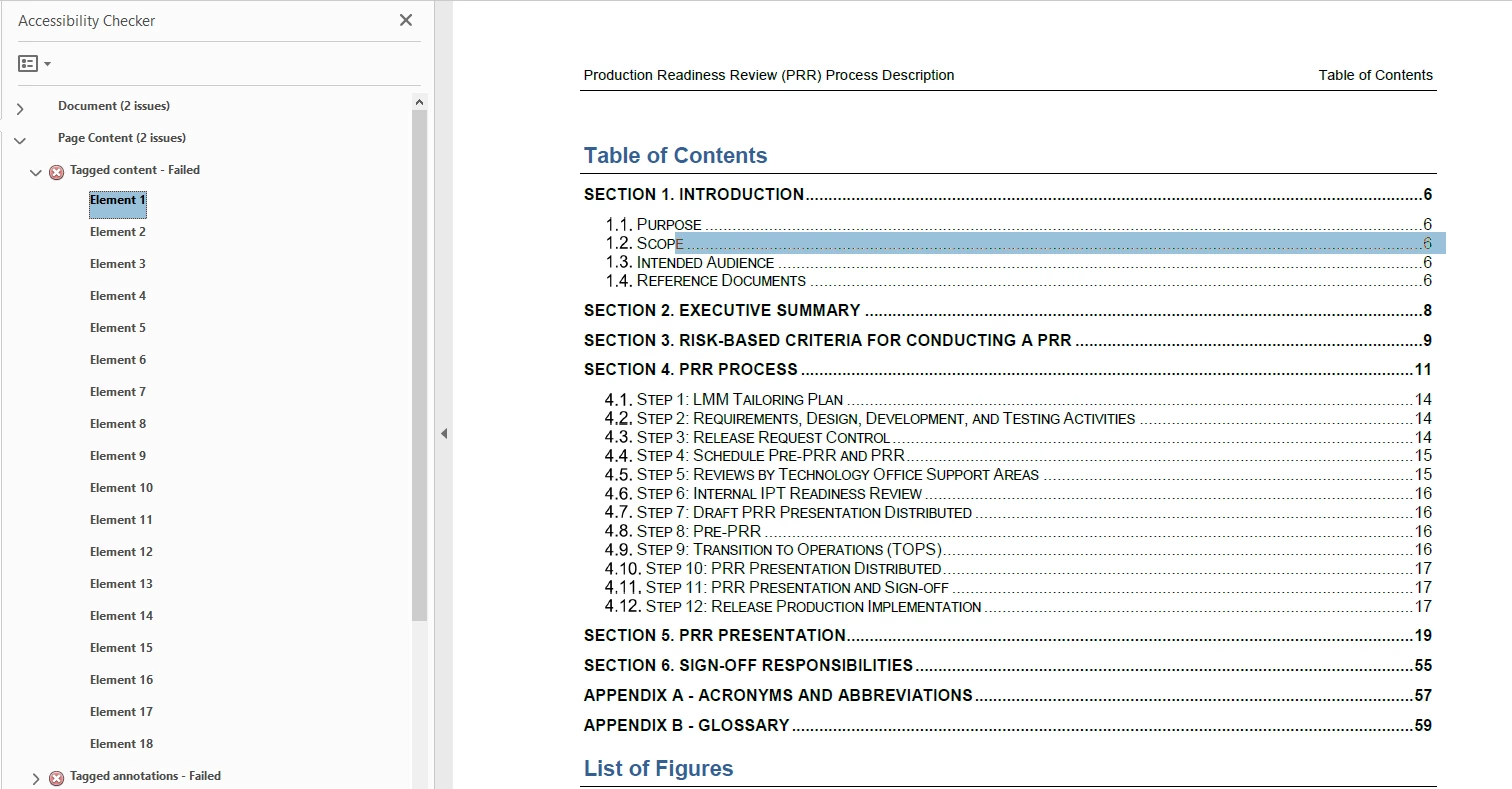
I have an issue where when I convert a docx file to PDF, I get a series of errors when running the accessibility checker that flags the different components of the TOC as untagged images. Does anyone have any ideas on why its doing this? I'm using the Acrobat DC Pro when getting this error but when I log into Citrix and use Acrobat 17 Pro I don't get this issue.