

Text Extraction from PDF

Copy link to clipboard
Copied
I am a Windows application developer using Visual Studio.
And trying to extract texts from a pdf file.
I get complete text extraction in ENGLISH language
But, not able to extract clean text in "SANSKRIT" and "GUJARATI" Languages.
I tried with different DLL libraries and functions.
Finally I got the problem and no Solution.
Problem : While extracting text from pdf, it does not give proper UNICODE of the character sometimes. SEE THE BELOW IMAGE.
THE PDF FILE HAS : 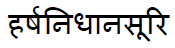
BUT THE TEXT FILE SHOWS : 
Kindly suggest the solution.


 24
Replies
24
24
Replies
24

Copy link to clipboard
Copied
1. Have you tried using Microsoft Word to view this text? What was your result?
2. You say the Unicode is incorrect. What is the Unicode exactly? Have you examined all of the code values produced?
Copy link to clipboard
Copied
Unicode contains a repertoire of over 136,000 characters covering 139 modern and historic scripts, as well as multiple symbol sets.
EACH CHARACTER IN EACH LANGUAGE HAS A UNIQUE CODE, THAT IS UNICODE/
YES, I TRIED TO CONVERT IN WORD AS WELL.
IT SHOWS THE SAME RESULT.
IN DETAIL - THE CHARACTERS IN THE PDF LET US SAY :
ENGLISH CONSONANT "X" HAS A PARTICULAR UNICODE VALUE 0058. IT SHOWS CORRECT VALUE WHEN EXTRACT ENGLISH TEXT. NO ISSUES AT ALL.
BUT IN "SANSKRIT" OR "GUJARATI" LANGUAGE , IT EXTRACTS WRONG UNICODE. (INCORRECT READING)
Copy link to clipboard
Copied
You don't need to tell us what Unicode is, sorry if that was not clear. And you are wrong: characters do not always have a unique representation. I was asking you what specific codes were extracted for this sequence. Please also tell us which exact codes you expected, so we can see how they are different.
For example if you saw XY but expected XZ I would want you to reply that you saw 0058 0059 but expected 0058 0060. I am not able to guess what Devanagari diacritics are in your pictures.

Copy link to clipboard
Copied
How did you extract the text with Acrobat Reader?
Copy link to clipboard
Copied
Sorry, simple error. I should have typed: "For example if you saw XY but expected XZ I would want you to reply that you saw 0058 0059 but expected 0058 005A".
Copy link to clipboard
Copied
Yes Exactly.
When the text is "XZ" in PDF; It must extract "XZ".
I have built a .NET application in C# .
Till now I have tried using iTextSharp, PdfBox and PDFlib. But no clear extraction.
Copy link to clipboard
Copied
Yes, so please share the specific numbers for the two strings in your images. In full please.
Copy link to clipboard
Copied
For the word in pdf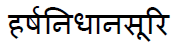
the unicode should be: \u0939\u0930\u094D\u0937\u0928\u093F\u0927\u093E\u0928\u0938\u0942\u0930\u093F
Text SHOWS : 
It shows unicode as : \u0939\u0930\u094D\u0937\u0928\u093F\u0927\u093E\u093F\u0938\u0942\u0930\u093F
Copy link to clipboard
Copied
Can you confirm how you obtained this list of Unicode points? Was it by adding code to the character extractor? Please do not read this value from the app opening the extracted data as this introduces the possibility of new errors.
It it would be best if you could share the PDF. You must ise your own file sharing for this.
Copy link to clipboard
Copied
/// PROGRAM IN C# USING "PDFBOX" LIBRARY
PDDocument doc = null;
string input = textBox1.Text; // INPUT FILE PATH IS IN textBox1.Text
doc = PDDocument.load(input);
PDFTextStripper stripper = new PDFTextStripper();
foreach (char c in stripper.getText(doc)) // EXTRACT EACH CHARACTER FROM TEXT
{
string text1 = String.Format("Character '{0}' has Decimal code: {1} and Unicode value: U+{2}",
c, ((int)c), ((int)c).ToString("X4"));
string unicode = "\\" + "u" + ((int)c).ToString("X4"); // TO STORE UNICODE AS "\u<unicode>", EACH CHARACTER
File.AppendAllText(output, unicode); // STORE UNICODE IN TEXT FILE (output)
}
// OPTIONAL
// File.WriteAllText(output, stripper.getText(doc), Encoding.UTF8); // TO STORE TEXT in TEXT FILE (output).
Copy link to clipboard
Copied
THE PDF FILE LINK :
Copy link to clipboard
Copied
This is the Acrobat Reader forum. Please share the result you get when extracting text or copy/paste using Acrobat Reader.
Copy link to clipboard
Copied
We had copied Contents(TEXTS) from PDF file and Pasted in .txt as well as .docx file.
THE RESULTS REMAINS SAME.
Additionally, THE PDF SEARCH OPTION SHOWS THE SAME INCORRECTED TEXT.
THE TEXT FILE LINK:
THE DOC FILE LINK :
THE IMAGE SHOWING SEARCHED TEXT IN ADOBE ACROBAT DC

Copy link to clipboard
Copied
It does not sound like you are actually using Adobe technology. You've mentioned that you've used "iTextSharp, PdfBox and PDFlib", these are all 3rd party products, and you will need to use their support systems to find out what's wrong with either your code or the PDF file you are using.
Copy link to clipboard
Copied
I HAVE NOT USED THE APPLICATION. JUST COPIED FROM ADOBE ACROBAT DC......AND PASTED IN NOTEPAD AND MICROSOFT WORD.
LET US SAY IF I AM NOT USING 3rd PARTY PRODUCTS.. BUT....
WHAT ABOUT THE SEARCH OPTION IN ADOBE ACROBAT...!!!
THE IMAGE SHOWING SEARCHED TEXT IN ADOBE ACROBAT DC
Copy link to clipboard
Copied
NOW I AM IN ADOBE TECHNOLOGY...
IS THERE ANY SOLUTION ???
Copy link to clipboard
Copied
ANY SOLUTION...!!!!
Copy link to clipboard
Copied
I analysed your original file. Simply: if lots of different software extracts text wrong from the PDF, blame the PDF.
Technical analysis.
1. Extracting text from a PDF is a complex task, but the PDF standard gives some recommendations.
2. One recommendation is that a PDF may contain a "ToUnicode" map, and that if it is present it should take precedence.
3. Your sample file contains a ToUnicode map.
4. In the ToUnicode map, the character which is visually DEVANAGARI NA has the Unicode value for DEVANAGARI VOWEL SIGN I.
5. It seems to me that this ToUnicode map is incorrect, though Devanagari is a particularly complex part of Unicode, and I do not pretend to properly understand the rules for shaping and composing accents.
6. Adobe and all other technologies are extracting text using correct methods
7.Your use of multiple technologies is an empirical conformation of the points from my analysis. If the PDF is incorrect, you need to focus your attention on the technology that creates it this way. It was not created with Adobe technology: did you try that?

Copy link to clipboard
Copied
I have the same issue but went I try to convert from PDF to exel File some of numbers change in exel to letters or symbol . How I can fixed this issue. I try to convert PDF from adobe -pro to exel 2010
Copy link to clipboard
Copied
I have the same issue but went I try to convert from PDF to exel File some of numbers change in exel to letters or symbol . How I can fixed this issue. I try to convert PDF from adobe -pro to exel 2010
Copy link to clipboard
Copied
Thank you for the analysis.
The point 4 suggests by you is : "DEVANAGARI NA has the Unicode value for DEVANAGARI VOWEL SIGN I"
Then Why does it show correct character for the first time and incorrect for the second time. And again correct for the further characters.
Mapping is to be researched...!!!
AND ALSO NOT ONLY FOR "DEVANAGARI NA" WHICH SHOWS INCORRECT, THERE ARE MANY CHARACTERS WHICH EXTRACT WRONG TEXT IN DEVANAGARI AND OTHER LANGUAGES AS WELL.
SEE THE BELOW IMAGE
https://drive.google.com/file/d/0BzT4y2YlCY9Xclo5WENLc3JNd2M/view?usp=sharing
IN INDESIGN....TYPED TEXTS...
https://drive.google.com/file/d/0BzT4y2YlCY9XTlNKNkY1eHNMejA/view?usp=sharing
Copy link to clipboard
Copied
I have a lot of PDF files created using INDESIGN and having no INDESIGN files (.indd).
Kindly suggest a method to extract text from PDF except copy-pasting in NOTEPAD.
Thank you.
Copy link to clipboard
Copied
I am not going to repeat or justify my analysis, or explain in any more detail how text extraction works. You may pay someone else to repeat it if you wish, I have already spent lot of time on this.
My considered opinion is that this PDF contains bad information for text extraction and that nothing can fix it. You do not have to accept my opinion. You can study the PDF reference yourself. This is very interesting and has occupied me for many years.
It it is a basic fact of PDF files: some do not have correctly extractable text. Have you considered reporting this as a bug in the PDF creator? You may link to my analysis.
Copy link to clipboard
Copied
This is the .indd file created with INDESIGN : TEST.indd - Google Drive
This is the .pdf file created from INDESIGN (Exported as .pdf) : TEST.pdf - Google Drive
By copying the content of pdf and pasting it into the same file (USING ADOBE ACROBAT DC PRO) as TEXT BOX gives garbage values SHOWN IN THE SAME PDF FILE.
Font Used : ADOBE DEVANAGARI BOLD
Kindly provide the solution...!!!

Get ready! An upgraded Adobe Community experience is coming in January.
Learn more
 AdChoices
AdChoices