


リンクをクリップボードにコピー
コピー完了
Adobe Acrobat Pro DC 2015.008.20082 を macOS Sierra 10.12.5 にて英語環境で使っています。
このバージョンの Acrobat Pro では、OCR に 3 つのオプションがあります。
1. Searchable Image (日本語: 検索可能な画像)
2. Searchable Image (Exact) (日本語: 検索可能な画像 (非圧縮))
3. Editable Text and Images (日本語: ClearScan) (ちなみに英語では ClearScan という言葉は消滅した模様)
3 の Editable Text and Images では OCR 機能が働いて、処理後に日本語検索が可能なことは確かめました。
しかしながら、1, 2 に関しては処理後、日本語検索ができません。このとき、画像テキストは選択し、コピー&ペーストできるのですが、ペースト時に文字化けしています。
Acrobat そのものでの検索も不可能ですし、Mac の Preview.app でも不可能です。
・対策 (試すこと)
・レポートする場所の指摘
等ありましたら、お願いします。


 1 件の正解
1 件の正解

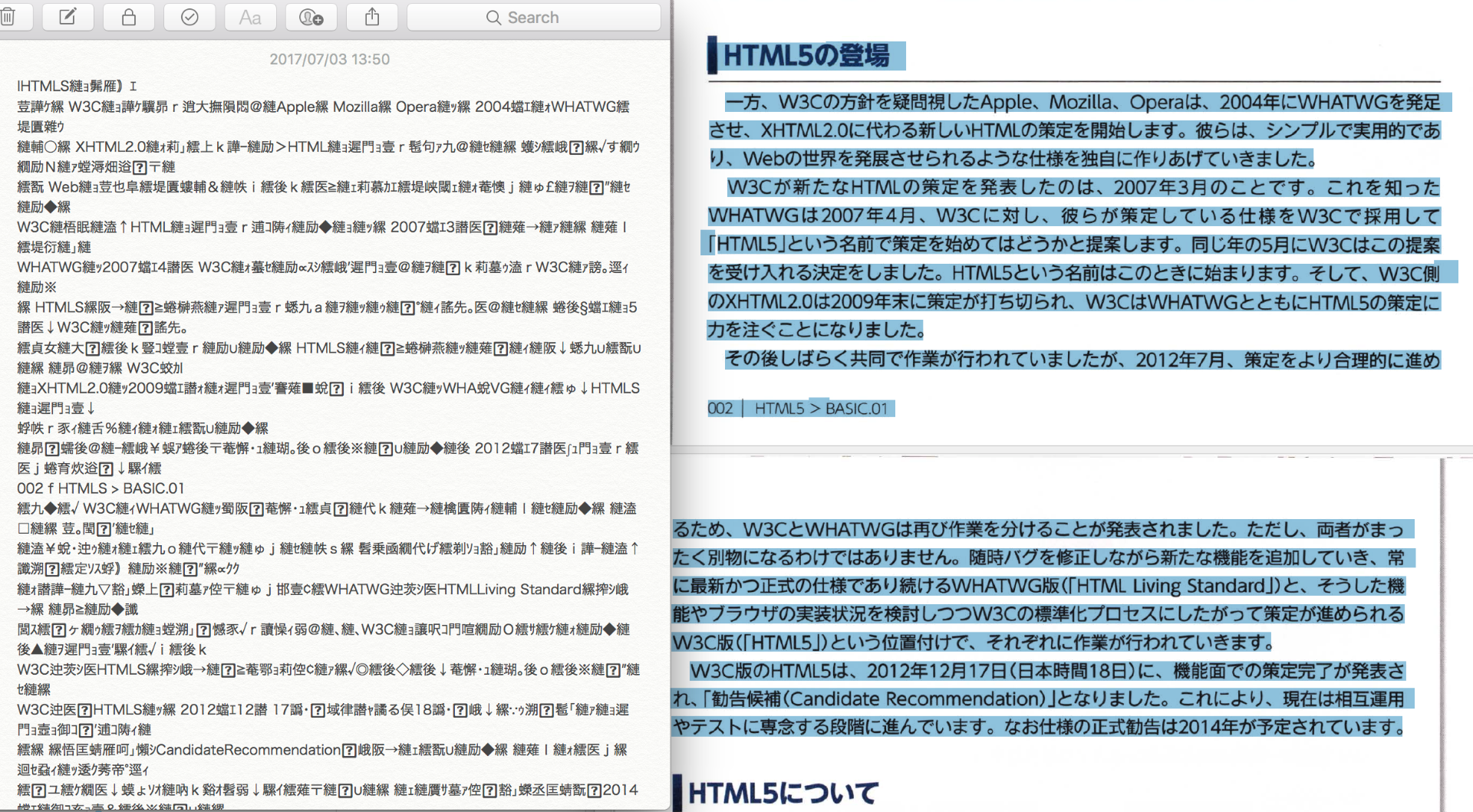
スキャン補正の設定でしたか。気づきませんでした。
確かにこちらでは、いずれの場合でも「PDFを編集」でOCR処理をかけていました。
そしてWindows/Macとも、あらためてスキャン補正からテキスト認識を行ってみました。
設定としては「検索可能な画像」(600dpi)と「検索可能な画像(非圧縮)」の両方をそれぞれなので、
環境差も含めて都合4回の変換をかけてみました。
ただ結果としては、やはり正常に処理されたことが確認できいました。
いずれも日本語UI+認識設定は日本語言語設定にて行っています。
 21
返信
21
21
返信
21
リンクをクリップボードにコピー
コピー完了
Acrobat DCのOCR処理は、基本的には設定言語に依存していたのではないかと思います。
他にある設定としては「PDFを編集」の中にある、「スキャンした文書」-「設定」を開き、
「次の言語でテキストを認識」で設定しなければならないはずです。
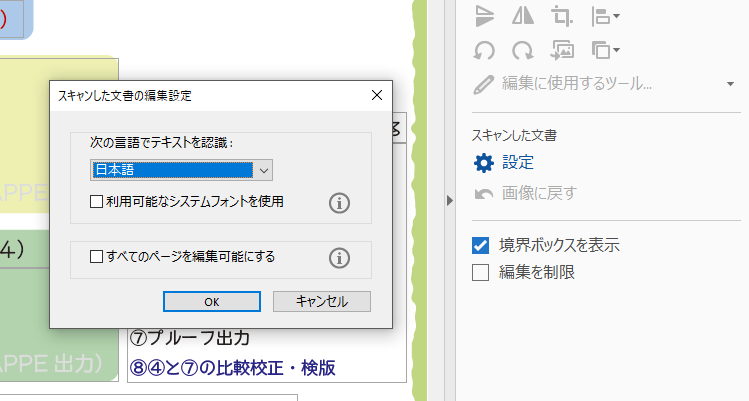
英語環境で使っている理由がわかりかねますが、
まずは該当設定やOSを含む言語設定を変更してみるところからではないでしょうか。
リンクをクリップボードにコピー
コピー完了
提案をありがとうございます。
英語環境で使っているのは、mac 自体を英語環境で使っているためです。
Acrobat DC の OCR 処理では、英語環境でも、日本語にて OCR 処理を選択することが可能です (Japanese が選択できます)。
設定から確認したところ、Japanese が選択されていました。
OS の言語設定の変更で再現するかどうかはまだ試していませんが、やってみようと思います。。。
Japanese が選択されていることを示すスクリーンショット、および
検索しても全く引っかからないことを示すスクリーンショットを添付しています。
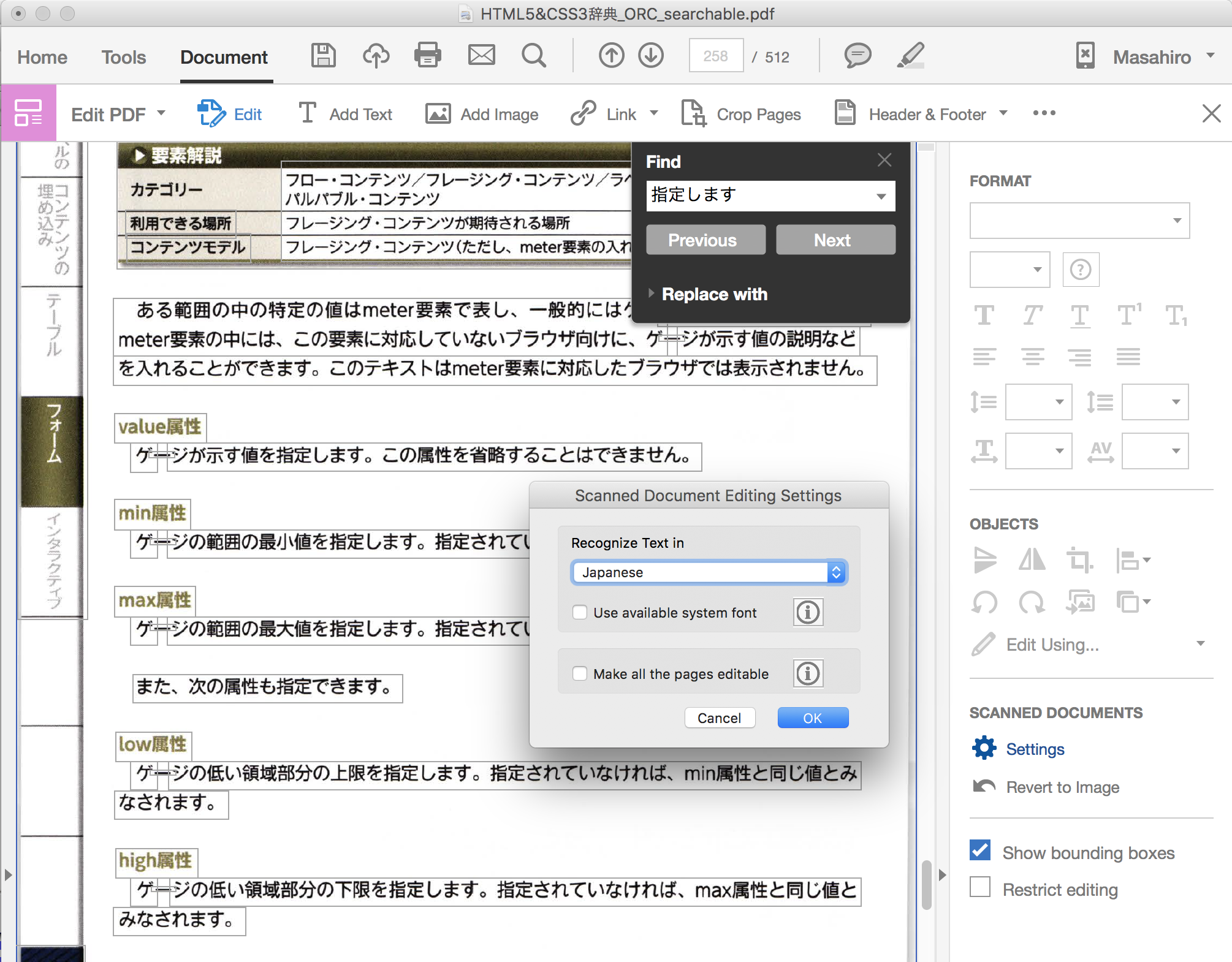
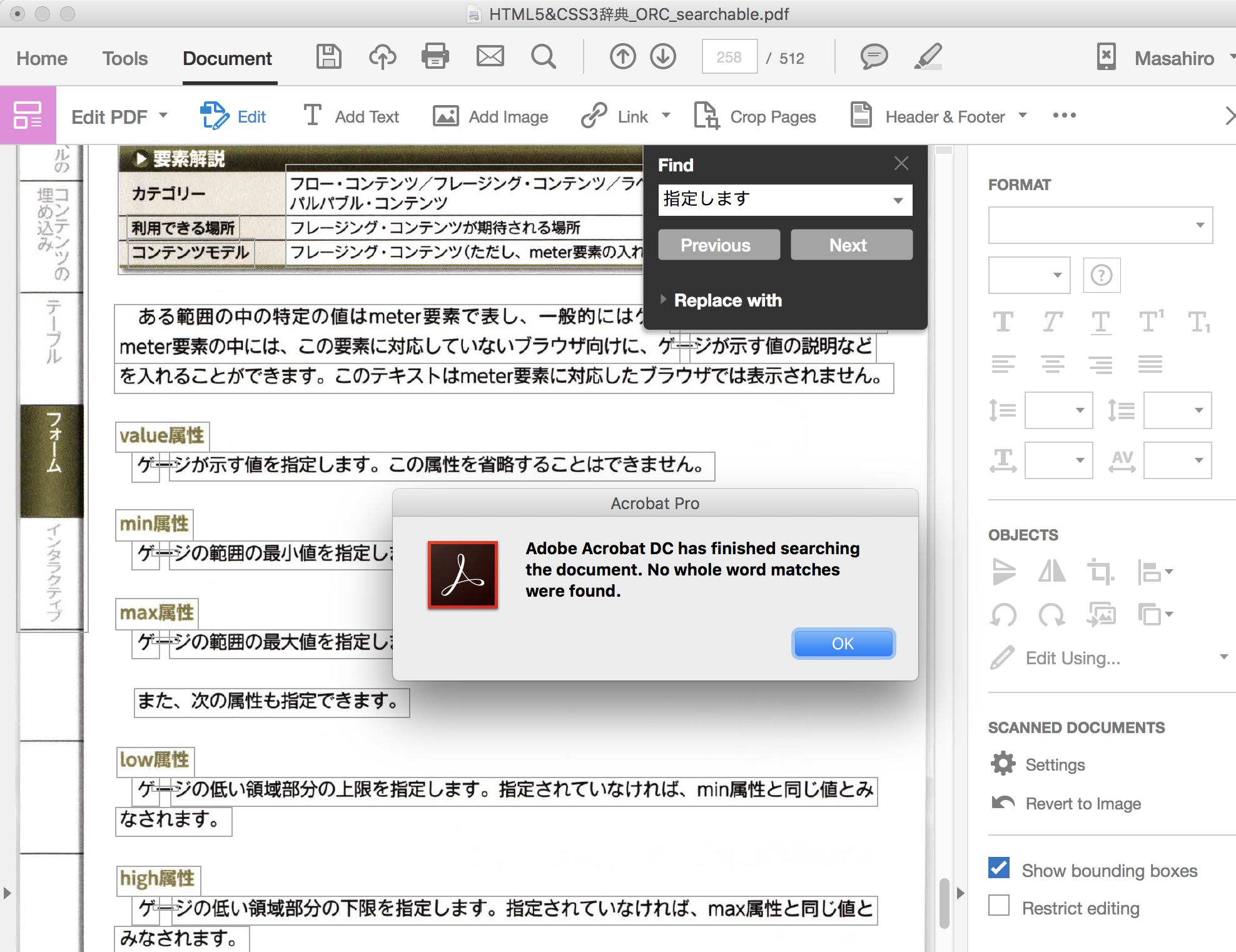
リンクをクリップボードにコピー
コピー完了
OCRの処理自体でその検索キーワード通りの認識が行われているかどうかは確認を取られたでしょうか。
単純なところですが、一度テキスト選択し、コピー&ペーストで外部のテキストエディタに貼りつけた場合の
結果を確認してみるなどです。
OCR自体はベストエフォートなので、言語設定がなされていても、100%変換というわけではないこともありますし、
そもそも現状で適正に日本語として変換されているかの確認も必要になると思います。
リンクをクリップボードにコピー
コピー完了
引き続きありがとうございます。
最初のポストの書き方がわかりにくかったかもしれませんが、
コピー&ペーストを試すと、正しくコピーされていないことが確認できます (ペーストしたものが文字化けしている状態)。
任意の日本語が文字化けします → OCR がうまくいっていないと思います。
また、先のご指摘にあった、日本語環境にて確認してみたところ、英語環境で行った結果を再現しましたので、OS の言語に依存しているのではなく、Adobe Acrobat Pro DC 自体に問題があるように思います。
他の方の環境では本当にうまくいっているのでしょうか。
情報ありましたらお願い致します。

リンクをクリップボードにコピー
コピー完了
OCR処理の失敗はあらゆるデータで起きているのでしょうか。
それとも特定のデータだけでしょうか。
記載した通りベストエフォート型なので、認識の状態によっては正常に読み取れないケースはありえます。
ただ、過去および現在も含めて試す限りはそこまでの状態ではないとは思っています。
こちらで使っているのがWindowsのContinious版なので、現在のバージョンは2017.009.20044ですが、
貼り付けられたスクリーンショットをローカルに保存後、Acrobatで直接開き、
編集機能でOCR認識させたところ、下記の結果が得られました。
(一部おかしいところはありますし、最上部は文字欠けしているので完全に化けていますが)
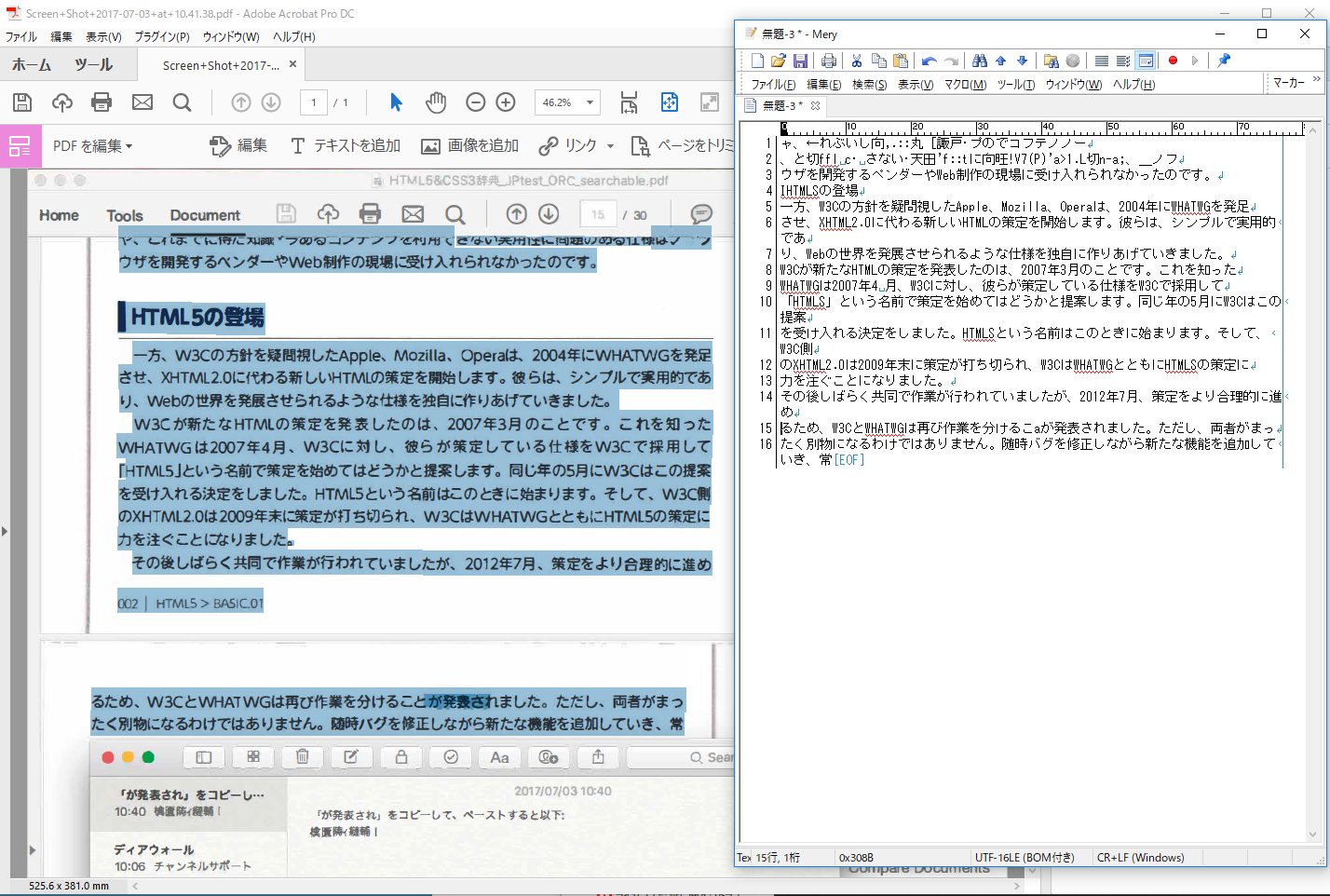
また過去に2015時点でもOCR処理は行ったこともありますが、データにもよりますが日本語としての認識はしていました。
お持ちのものはおそらくClassic版だと思うので認識精度が同一かどうかの断言はできないところですが、
バージョンによってそこまでの差異が出ることは少々思いにくいところです。
一度再インストールしての確認なども行ってみてはどうでしょうか。
リンクをクリップボードにコピー
コピー完了
ご確認までしていただき、ありがとうございます。
こちらの環境では完全に文字化けしてしまうようです。
(エンコードだけ間違っているように見える。)
再インストールを含めて試してみたいと思います。
リンクをクリップボードにコピー
コピー完了
assause さま、
改めてよく、assuase さんの添付画像を見たところ、ClearScan が施されているように思います。
私の環境でも、ClearScan (Editale Text and Images) では OCR がうまくいっています。
ここで問題になっているのは、以下のオプションで OCR がうまくいかない、ということでした。
1. Searchable Image (日本語: 検索可能な画像)
2. Searchable Image (Exact) (日本語: 検索可能な画像 (非圧縮))
こちらに関しては、windows ですとうまくいくのでしょうか。
私の環境ですとうまくいかないのですが。
(同じ png 画像から上記 1, 2 の OCR をやってみましたが、結果は変わらず散々でした。)
リンクをクリップボードにコピー
コピー完了
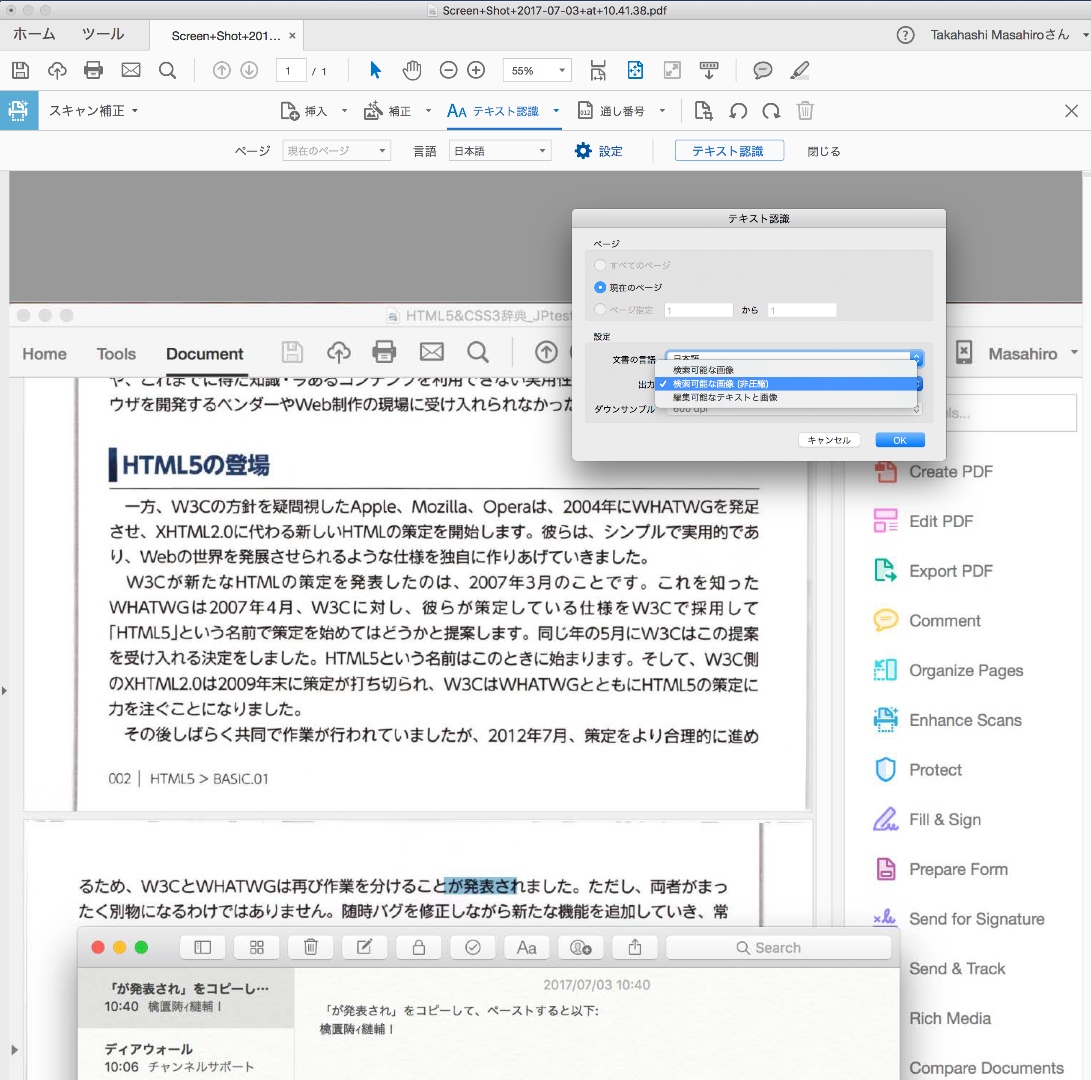
そちらの設定、スキャナーからPDFを作成するときの設定でしょうか。
もしそうだとしたら、昨日上げたスクリーンショットはそもそも掲出いただいたpngファイルを
そのままAcrobatで直接開いてPDF化したものなので(ドラッグ&ドロップで展開)、直接的にその設定は関わらないような気がします。
あわせてMac版Acrobat DC(Continious 2015.023.20056なのでひとつ古いもの)でもほぼ同様にやってみましたが
(開くメニューで強制的にpng展開)、多少OCRの傾向は異なるものの、ほぼ同様の結果でした。
直接開いた場合はおそらくですが、PDFを作成の単一ファイル生成と同等の動きだと思います。
あわせてですが、どちら環境もスキャナー自体を接続していない環境のものを使ったので、そこの設定は一切変更していません。
リンクをクリップボードにコピー
コピー完了
Macで確認までしていただき、感謝いたします。
「そちらの設定」といのは、 1. Searchable Image、2. Searchable Image (Exact) を指していらっしゃいますか?
これは、スキャナではなく、Acrobat Pro DC の OCR の設定です。
スキャン時の設定は無関係のように思われます。
私の方でも、先に私自身が先に上げたスクリーンショットにて「2. Searchable Image (Exact)」で OCR をやってみましたが、文字化けしました。OSを日本語環境にして試してスクリーンショットを撮ってみました。
assause さんの方では、正しくできるということでしたら、私の方の固有の問題ということになりますね。
困りました。。。(^^;
リンクをクリップボードにコピー
コピー完了
assause さま
連投ですみません。
最初の assause さんの投稿で、「PDF を編集」メニューから、OCR を設定しているように見受けられます。
しかし、こちらで試したところ、PDF を編集しようとした場合に、ClearScan モードでの OCR が自動的に行われるようです。
一方で、こちらで行なっているのは、(Windows のメニューが分からずすみませんが、Mac では)
「スキャン補正」→「テキスト認識」→「このファイル内」→(メニューバーみたいなのが現れる)「設定」→(テキスト認識というダイアログが出る)「設定」→「文書の言語→日本語」、「出力→検索可能な画像 (非圧縮)」→「テキスト認識」(ボタン)
という流れです (多分 Windows でも同様のメニューがあるはずです)。
設定で、検索可能な画像 (非圧縮) (または圧縮) を選ぶと、日本語がうまく OCR 処理されません。
p.s.
一度お名前を間違えていました、すみません。
リンクをクリップボードにコピー
コピー完了
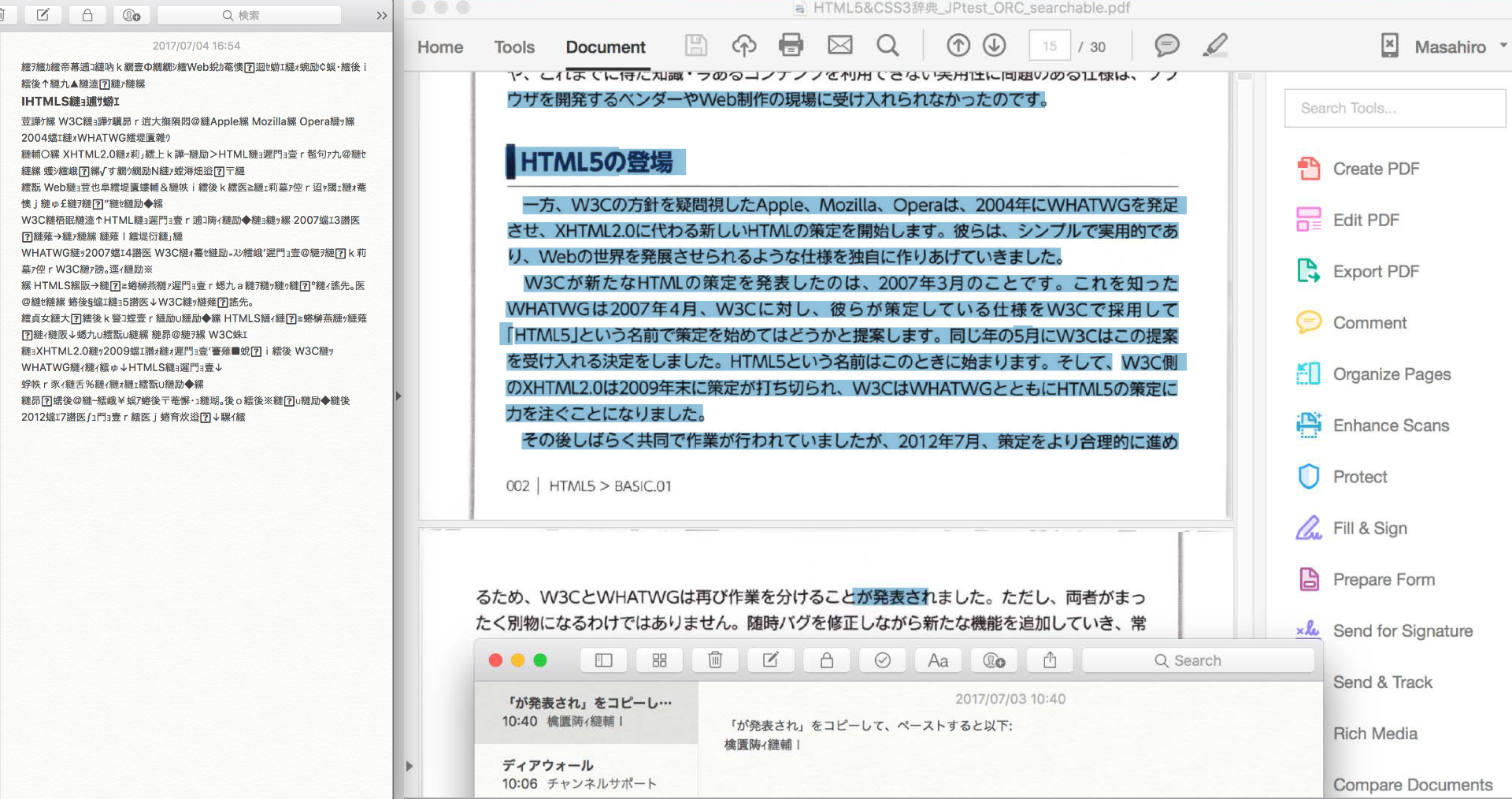
スキャン補正の設定でしたか。気づきませんでした。
確かにこちらでは、いずれの場合でも「PDFを編集」でOCR処理をかけていました。
そしてWindows/Macとも、あらためてスキャン補正からテキスト認識を行ってみました。
設定としては「検索可能な画像」(600dpi)と「検索可能な画像(非圧縮)」の両方をそれぞれなので、
環境差も含めて都合4回の変換をかけてみました。
ただ結果としては、やはり正常に処理されたことが確認できいました。
いずれも日本語UI+認識設定は日本語言語設定にて行っています。
リンクをクリップボードにコピー
コピー完了
assause さま
ご連絡いただきありがとうございました。
ご返信とちょうど入れ違いになり、お手数を余分にかけてしまう形になりましたが、たった今、問題回避に至りました。
やはり、おかしいということで、以下の念入りの再インストールを行いました。
1. 完全に Acrobat Pro DC をアンインストール
1-1. Creative Cloud からアンインストールを選択
1-2. 再起動後、アプリケーションフォルダを見ると (何故か) まだそこに Acrobat Pro DC があったので、フォルダ内の純正アンインストールツールを使ってアンインストール
2. 念のため、再起動
3. 念のため、OS を日本語環境に設定
4. Creative Cloud から Acrobat Pro DC を再度インストール
たまたまインストールに失敗していたのか、英語環境がダメだったのか、原因の特定に至らなかったのですが、上記によって正しい振る舞いをするようになりました。
(前にただ、アンインストール & インストールだけではダメだったので、言語環境は効いている可能性もありますし、Creative Cloud からアンインストールを選択した後にアプリケーションフォルダが残っていた点も不可解で、原因が特定できませんでした。。。)
大変長い間お付き合いいただき、感謝しています。
ありがとうございました。
リンクをクリップボードにコピー
コピー完了
assause さま
あの後、OS の言語を英語に戻したら、再び症状が再発し、色々なパターンで設定内容を試しました。
問題を特定できたので、お礼の気持ちと、このスレッドを今後見る方のためにも記録を残して起きます。
【結論】
Acrobat Pro DC の環境設定の、「言語」を日本語にすることで、全ての問題が解決します。
【補足等】
・アプリケーションの言語と、OCR の言語を一致させないと OCR が機能しない仕様 (バグ) です。
・デフォルトの言語設定は、システムに合わせるものになっています。
・アプリケーションの言語設定が適用されるのは、アプリケーションを再起動した後です。
・Acrobat Cloud (アプリケーション) の環境設定でも、言語設定がありますが、こちらは関係ありません。
OS が多言語の場合に発言する事象ですので、レアイベントだと思いますが、逆に情報が見つかりにくいので、誰かの役に立てばと思います。
リンクをクリップボードにコピー
コピー完了
解決されたとのこと、あわせて原因まで探られたとのことで、こちらも勉強になりました。
ただ仰るように通常は発見が困難な内容なのも事実だと思います。
バグ、というか、想定されていないというところのような気がします。
またおそらくそこまでの動作チェックができていないこともありそうです。
差し支えなければ不具合報告フォームに投稿されるのがいいかもしれません。
(このスレッドをそのまま転用するだけで対応できます)
リンクをクリップボードにコピー
コピー完了
ありがとうございます。
不具合報告フォームに投稿しておきました。
(OS が英語だから (?) 英語フォームになり、英語で報告しました。)
リンクをクリップボードにコピー
コピー完了
こちらこそお手数をおかけしました。
不具合報告については原則としては英語表示で、開発側に直接飛ぶようです。
ただ報告自体は日本語でも構わないことになっています。
リンクをクリップボードにコピー
コピー完了
ご連絡ありがとうございます。
日本語でも良かったのですね。
英語で書きましたが、多分読んでもらえるでしょうし、ここのリンクを貼っておきましたので、オッケーだと思います。
次期バージョンかその次くらいで対応してもらえると助かりますね。

リンクをクリップボードにコピー
コピー完了
とても参考になりました。私も日本語のPDFの読み取りで文字化けが起きてしまって困っていました。アプリケーションの環境設定の中の言語設定が、「システムの言語と同じ」になっていたのですが、それを「日本語」に変えたところ、解消されたようです。
リンクをクリップボードにコピー
コピー完了
追加情報。
ソフトウェアを一旦アンインストールして、次のバージョンを再インストールしました。
version 2017.09.20044
英語環境・日本語環境共に確認しましたが、上記の現象は改善されず、依然
1. Searchable Image (日本語: 検索可能な画像)
2. Searchable Image (Exact) (日本語: 検索可能な画像 (非圧縮))
での OCR はうまくいきません。ちなみに半角英数字はうまく判別できているようです。

リンクをクリップボードにコピー
コピー完了
今更なんですが、同じような問題が生じましたので投稿してみます。私はAcrobat Pro XI使っていますが、やはり「Searchable Image」か「Searchable Image (Exact)」によってOCRすると、出来上がったPDFはPreviewからのコピー・アンド・ペーストができないのです。Acrobatの言語を日本語にしても、なにも変わらないです。
おそらく、私とmasayan24さん以外誰も気づかないだろうと思いますが、なにか改善する方法あれば非常に嬉しいです。
リンクをクリップボードにコピー
コピー完了
Acrobat XI自体はすでにセキュリティサポートすら終了していますから、それがもし不具合としても更新されることはありません。
またPreviewがmacOSのそれだとした場合、Adobe自体が他の互換ビューワーの考慮をする必要がないわけですから、改善点にもならない可能性が高いところです。

 AdChoices
AdChoices