We had a similar example about a year ago.
Found that the text (or portions of the text) had kerning/tracking applied, and it probably was introduced by Acrobat's OCR utility, attempting to mimic/represent the visual appearance of the original scanned text.
Adobe, please check your utility: it should not be adding tracking/kerning/letterspacing to any text during the OCR process.
We corrected the resulting Word file by removing all manual overrides at the character level. Two ways to do that in Word/Windows (Mac-ers, only the second method is available in Word/Mac):
- Open Word's Navigator panel.
- Select the text (we recommend selecting ALL the text with Control + A).
- Click the bottom-most pink eraser to erase manual overrides (formatting).
- The text should snap and appear normal.
OR ...
- Select the text.
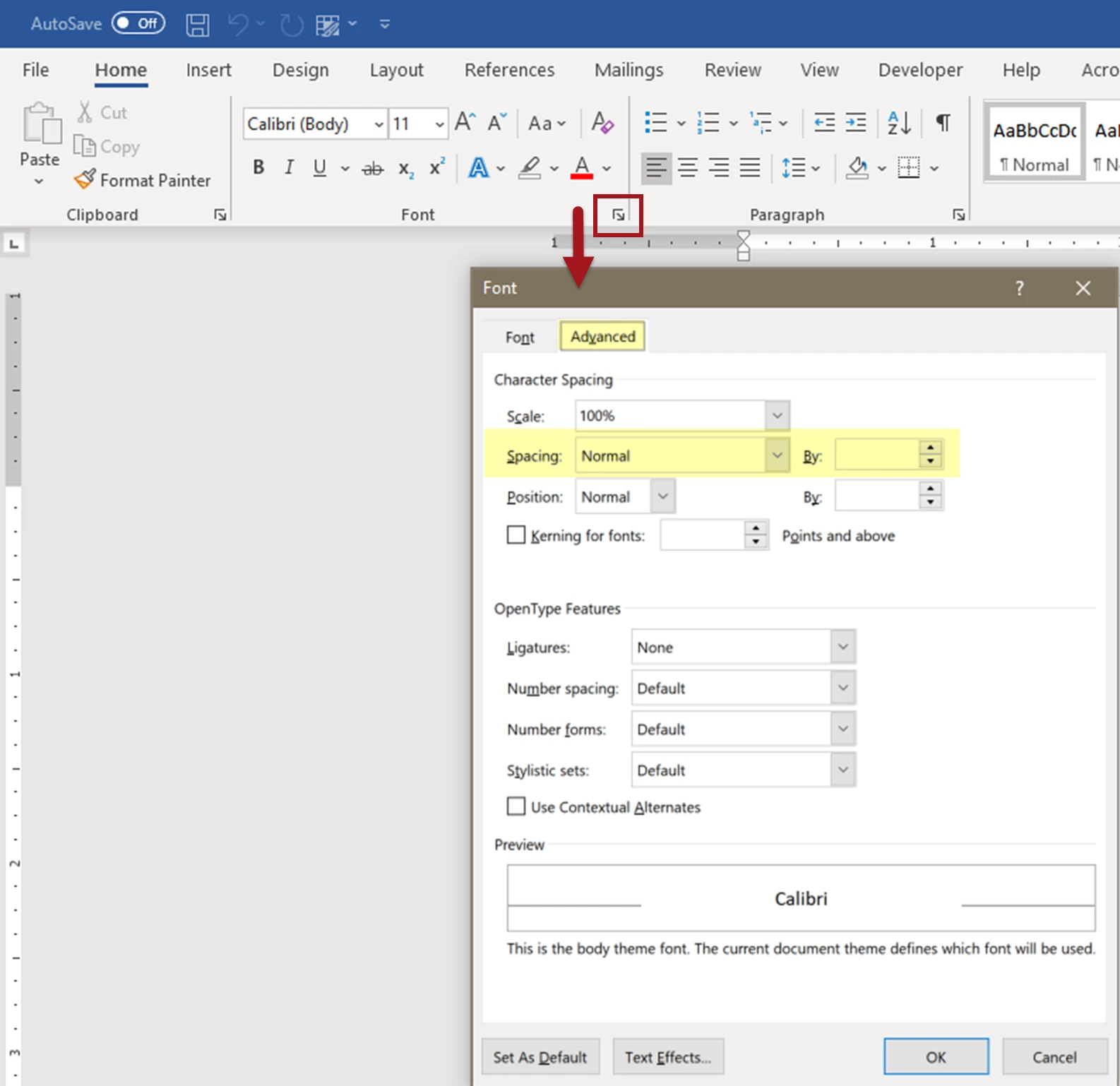
- Open Word's Font Panel (see screen capture below).
- Select the Advanced tab at the top.
- Set the Spacing to Normal and leave the "By" field blank.
- The text should snap and appear normal.
Hope this helps.

