

- Home
- Acrobat
- Discussions
- Re: Extract PDF Pages Based on Content
- Re: Extract PDF Pages Based on Content

Copy link to clipboard
Copied
Every fall and winter I have to work with PDF files that are hundreds of pages. Last fall I came across a java script that I was able to run and it worked beautifully. In the last year, I have either lost more brain cells or acrobat dc doesn't work the same way as acrobat X. I need to find a way to extract the pages based off of a word search and save those pages to another file. I would appreciate any suggestions. Also, I have added the java script that was used last year. Thanks in advance for your help.
// Iterates over all pages and find a given string and extracts all
// pages on which that string is found to a new file.
var pageArray = [];
var stringToSearchFor = "Total";
for (var p = 0; p < this.numPages; p++) {
// iterate over all words
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
pageArray.push(p);
break;
}
}
}
if (pageArray.length > 0) {
// extract all pages that contain the string into a new document
var d = app.newDoc(); // this will add a blank page - we need to remove that once we are done
for (var n = 0; n < pageArray.length; n++) {
d.insertPages( {
nPage: d.numPages-1,
cPath: this.path,
nStart: pageArray
nEnd: pageArray
} );
}
// remove the first page
d.deletePages(0);
}



Copy link to clipboard
Copied
I assume you were running the script as an Action in Acrobat XI (as described in my blog post). You can do the same thing in Acrobat DC. Just download the SEQU file again (from here: Extract PDF Pages Based on Content - KHKonsulting LLC) - then make sure that the filename is ExtractPagesWithString.sequ (when I download the file using Safari on a Mac, it appends .xml at the end - in that case, just rename the file so that it has the .sequ extension again). Now you should be able to drag&drop the file on the new Acrobat DC icon or into the application window. You should get get a confirmation dialog (or two). Once the Action is imported, you should be able to run it. To find the Actions interface, type "Action" into Acrobat's tool search bar. You will find that at the top of the right hand pane, and at the top of the Tools collection when you click on Tools on the left side of the Acrobat window, or you can try to find the "Action Wizard" on the Tools page and click on it. You can now run the Action on one or more files, but it will always just search for the string that I've put into the code. To change that. select to edit the Action. Let's assume that you click on the Action Wizard on the Tools page. You should now see the following:

Click on the "Manage Actions" button and then select the "Extract Pages With String" Action and click on the "Edit" button:
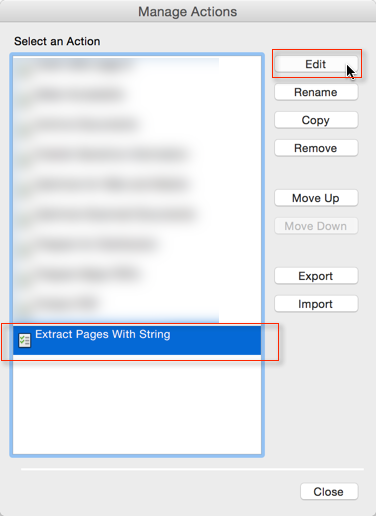
The next thing you will see is this:
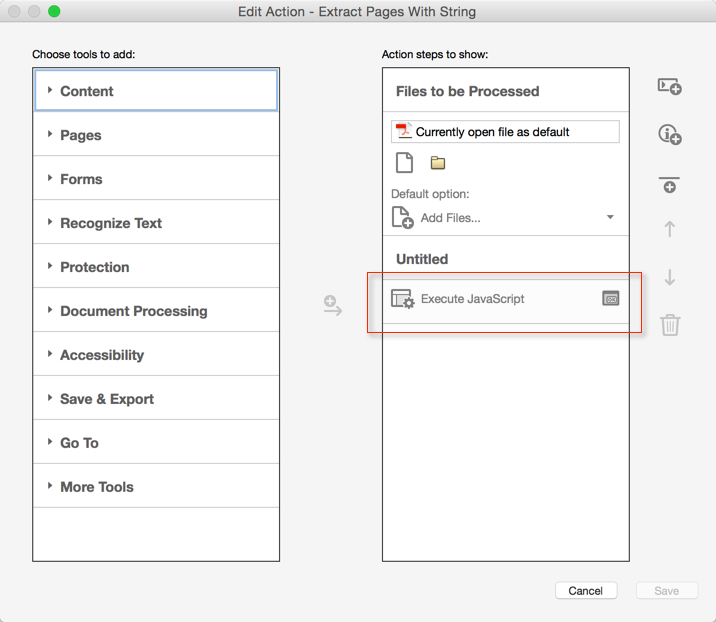
When you now click on "Execute JavaScript", this Action item will expand and will look like this:
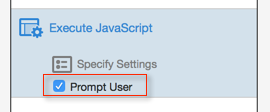
Make sure that "Prompt User" is checked.
Now you can save your modified Action. When you run the Action, you will see the JavaScript editor pop up:
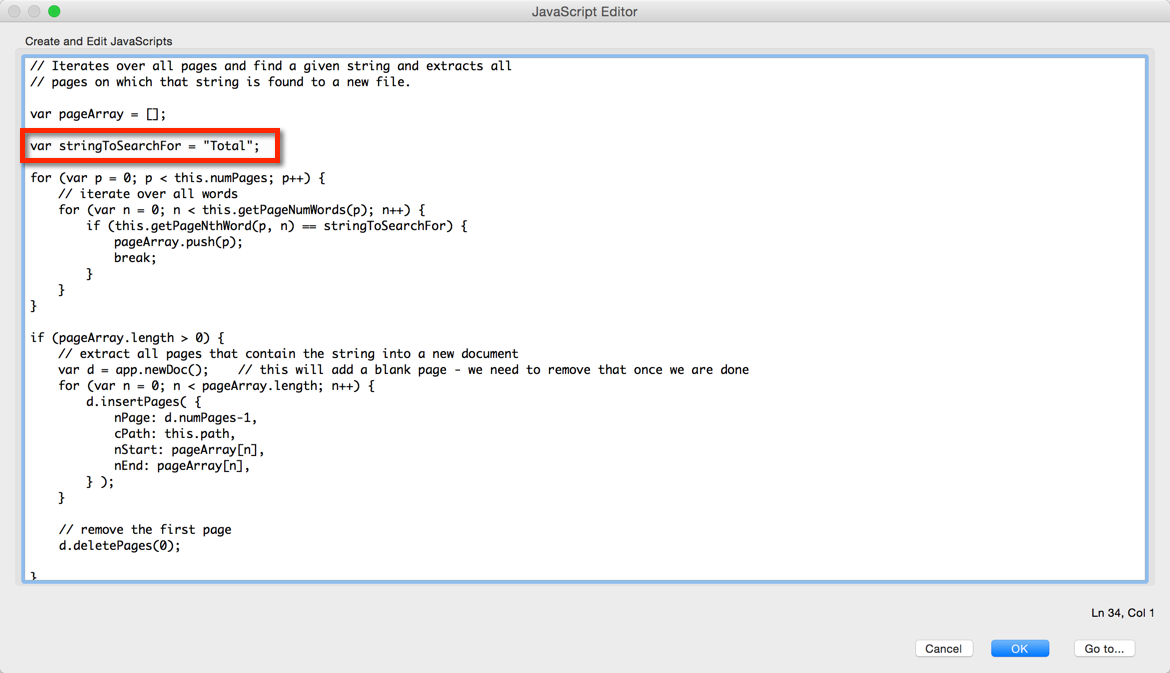
You can now change the "stringToSearchFor" variable and set it to whatever text string you want to search for and split the document at.
 37
Replies
37
37
Replies
37
Copy link to clipboard
Copied
I guess you found the script on my web site 
What exactly is different now vs. when you used this last year? As far as I know, the script should work without any changes in Acrobat DC. In order to help, I would need a better understanding of what exactly is happening.
Keep in mind that text extraction is a pretty complex task, and it only works correctly if the PDF file contains all the information needed to find text information. You can test this by doing a search in your PDF file (Ctrl-F or Cmd-F), then type in the term you are looking for. Can Acrobat find it? If not, then it's not the script's fault, it's the PDF file that cannot be searched.
Copy link to clipboard
Copied
First, I want to say that it worked perfectly last year so I’m sure it was me. It was a real time saver. I can’t seem to get to the right place to add the word that I need to search/extract. Also, I can’t find where to executing Java script in the newer version.
Copy link to clipboard
Copied
I assume you were running the script as an Action in Acrobat XI (as described in my blog post). You can do the same thing in Acrobat DC. Just download the SEQU file again (from here: Extract PDF Pages Based on Content - KHKonsulting LLC) - then make sure that the filename is ExtractPagesWithString.sequ (when I download the file using Safari on a Mac, it appends .xml at the end - in that case, just rename the file so that it has the .sequ extension again). Now you should be able to drag&drop the file on the new Acrobat DC icon or into the application window. You should get get a confirmation dialog (or two). Once the Action is imported, you should be able to run it. To find the Actions interface, type "Action" into Acrobat's tool search bar. You will find that at the top of the right hand pane, and at the top of the Tools collection when you click on Tools on the left side of the Acrobat window, or you can try to find the "Action Wizard" on the Tools page and click on it. You can now run the Action on one or more files, but it will always just search for the string that I've put into the code. To change that. select to edit the Action. Let's assume that you click on the Action Wizard on the Tools page. You should now see the following:
Click on the "Manage Actions" button and then select the "Extract Pages With String" Action and click on the "Edit" button:
The next thing you will see is this:
When you now click on "Execute JavaScript", this Action item will expand and will look like this:
Make sure that "Prompt User" is checked.
Now you can save your modified Action. When you run the Action, you will see the JavaScript editor pop up:
You can now change the "stringToSearchFor" variable and set it to whatever text string you want to search for and split the document at.
Copy link to clipboard
Copied
You are a life saver. I cannot begin to thank you enough for your help. I was messing up when I saved the SEQU file by letting it change the extension.

Copy link to clipboard
Copied
i dragged and dropped the ExtractPagesWithString.sequ onto the Adobe Acrobat DC shortcut and when i do I get some popup boxes.
I changed the java script where it says "Total" to "CA Total". I'm not sure the java script worked. Where does the completed file get saved?
Is something wrong?


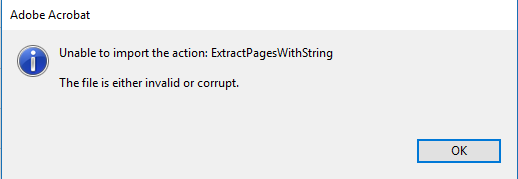
Copy link to clipboard
Copied
The last message clearly states that the action was not imported. So yes, there is something wrong. I assume you edited the SEQU file to make your change. In that process, you probably corrupted the XML structure of the file. I would recommend that you recreate the action from scratch in your version of Acrobat, using the script from the original action.
Copy link to clipboard
Copied
I recreated the SEQU file and changed the string to what I am looking for and I dragged and dropped the file into Adobe Acrobat DC and I am still getting the error message.
I have setup both Java scripts you reference but I have obviously missed something. I have included both scripts, the string I am looking for is in bold.
#1
// Iterates over all pages and find a given string and extracts all
// pages on which that string is found to a new file.
var pageArray = [];
var stringToSearchFor = "CA Total";
for (var p = 0; p < this.numPages; p++) {
// iterate over all words
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
pageArray.push(p);
break;
}
}
}
if (pageArray.length > 0) {
// extract all pages that contain the string into a new document
var d = app.newDoc(); // this will add a blank page - we need to remove that once we are done
for (var n = 0; n < pageArray.length; n++) {
d.insertPages( {
nPage: d.numPages-1,
cPath: this.path,
nStart: pageArray
nEnd: pageArray
} );
}
// remove the first page
d.deletePages(0);
}
#2
This XML file does not appear to have any style information associated with it. The document tree is shown below.
<Workflow xmlns="http://ns.adobe.com/acrobat/workflow/2012" title="Extract Pages With String" description="Looks for a certain string and extracts all pages that contain that string into a new PDF document. The document will be open in Acrobat when this Action is run, and needs to be saved. " majorVersion="1" minorVersion="0">
<Group label="Untitled">
<Command name="JavaScript" pauseBefore="false" promptUser="false">
<Items>
<Item name="ScriptCode" type="text" value="// Iterates over all pages and find a given string and extracts all
// pages on which that string is found to a new file.
var pageArray = [];
var stringToSearchFor = "CA Total";
for (var p = 0; p < this.numPages; p++) {
// iterate over all words
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
pageArray.push(p);
break;
}
}
}
if (pageArray.length > 0) {
// extract all pages that contain the string into a new document
var d = app.newDoc(); // this will add a blank page - we need to remove that once we are done
for (var n = 0; n < pageArray.length; n++) {
d.insertPages( {
nPage: d.numPages-1,
cPath: this.path,
nStart: pageArray
nEnd: pageArray
} );
}
// remove the first page
d.deletePages(0);
}
"/>
<Item name="ScriptName" type="text" value=""/>
</Items>
</Command>
</Group>
</Workflow>

Copy link to clipboard
Copied
Create a new action in the Action Wizard and add the JavaScript code to it.

Copy link to clipboard
Copied
This script won't work with a search term that's longer than one word. That will require a more complex code.

Copy link to clipboard
Copied
brother,can you tell me the way to extract and then delete the extracted pages from the main pdf,and save the extracted pages in seperate pdf? same as you mensioned+delete the extracted page from source file,please,please please,i will be forever grateful to you
Copy link to clipboard
Copied
You can find the Javascript debugger under Tools > Javascript.
Copy link to clipboard
Copied
Also, I am no expert but your tutorial worked so perfectly, I didn’t have to be.

Copy link to clipboard
Copied
Would you have a suggestion to delete the pages that contain that word "Total" and save the others?

Copy link to clipboard
Copied
I didn't know about this sequence. Very handy.
Can it also be used so that rather than looking for the word "Total", it could be used to find a regular expression/GREP?
Colin
Copy link to clipboard
Copied
It's possible, but if the search term is longer than one word it is quite complicated to implement it.

Copy link to clipboard
Copied
Is it possible to delete pages that contain 'Total'? Also, is it possible to delete full phrases from pages instead of the page itself?
Copy link to clipboard
Copied
- Yes, this is explained above. Read the full thread.
- That's possible, too, using the "Search & Remove Text" tool. However, it will not cause the rest of the text in the page to "re-flow". It will just leave a blank space in the middle of it, where the deleted text used to be.
Copy link to clipboard
Copied
-I couldn't find where they provided a solution to delete the pages containing 'Total'.. I prefer to just delete them, not extract them
-Thank you, I was able to find and use the 'search and remove text' tool.
Copy link to clipboard
Copied
This code should do the trick:
var stringToSearchFor = "Total";
pagesLoop:
for (var p = this.numPages-1; p>=0; p--) {
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
if (this.numPages==1) {
app.alert("Error! Can't delete the last page of the file.");
} else this.deletePages(p,p);
continue pagesLoop;
}
}
}
Copy link to clipboard
Copied
Yes I just found it under More Like This, at the top, it's beautiful, thank you. If I wanted to remove all pages that contain either 'Total', 'Microsoft PowerPoint' or 'CSI' would it be more efficient to do each one separately or combine them? I am processing a 4k page documents.. and if it's more efficient to combine them, how would I do that?
Copy link to clipboard
Copied
That would require a more complex script, especially if the search term is more than one word.
I can develop this code for you, for a small fee. You can contact me directly at try6767 at gmail.com to discuss it further.

Copy link to clipboard
Copied
Is there a way to extract the pages with the string and the pages that immediately follow it?
So for example, if page 3, and 7 contains the string 'Total' it will extract page 3, 4, 7, and 8?
Copy link to clipboard
Copied
You can certainly do that, it's just a matter of expressing this in a script. Let's assume that the page you find the term on is n, then you would extract n and n+1. I would check to make sure that there is actually a page n+1 in the document.
Copy link to clipboard
Copied
Karl,
Thank you for the fast reply! I am pretty much an amateur at Javascript and see references to 'n' in the script, but I am not sure where to add the 'n+1' reference in the above code.
Could you help?
-
- 1
- 2

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices