Question
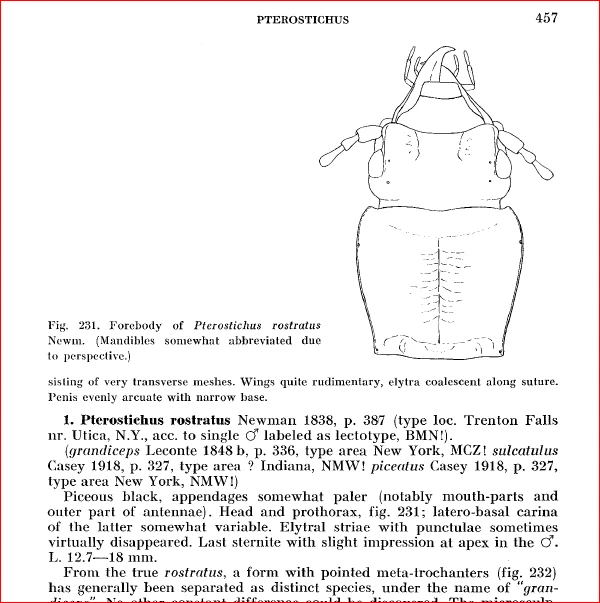
"cleaning up" pdf's of old, scan generated, scientific documents
Is there a process for "cleaning up" pdf's created from scaned documents? in this example ... an old scientific doument with symbols, latin names, etc.?
When I selected a section, then saved as PDF...... symbols, latin names, etc. are sometimes interperted incorrectly.
Any suggestions?