

- Home
- Acrobat Reader
- Discussions
- Extract Pdf API is not extracting text from header...
- Extract Pdf API is not extracting text from header...
Extract Pdf API is not extracting text from headers

Copy link to clipboard
Copied
I have extracted the attached pdf file and got a json & excel tables.
The tables are extracted perfectly. (The attached pdf has removed sensitive numbers in the table)
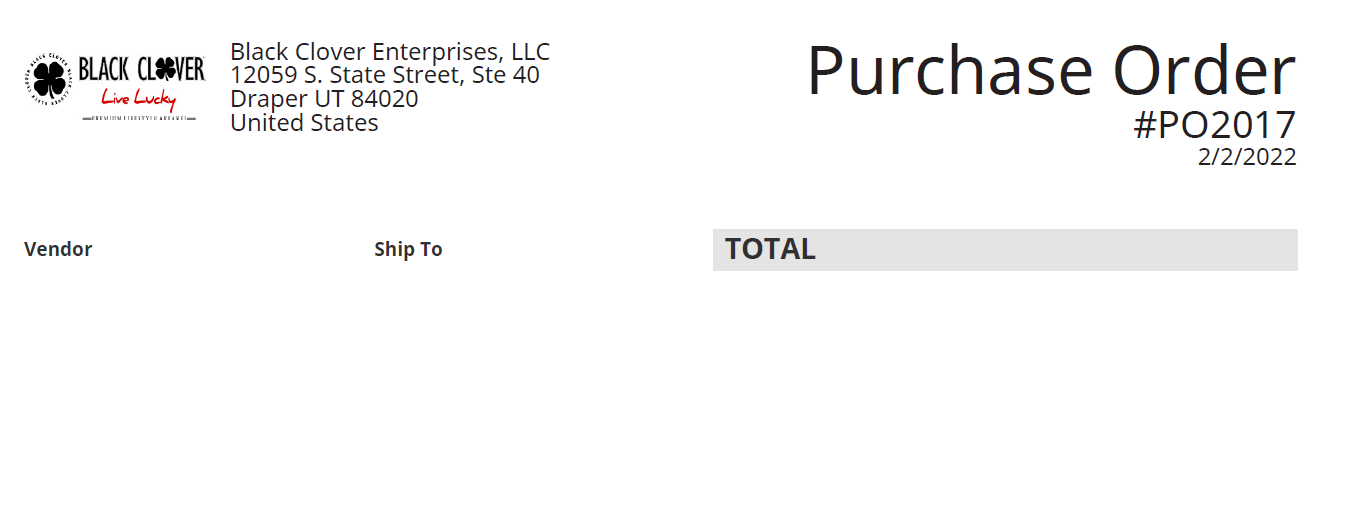
But it seems to be ignoring the header (attached pic) completely,
including the part below.
"Purchase Order
#PO2017
2/2/2022"
Other simple tools have no problem extracting the text from the pdf file.
I think this issue is related to the link below.
"not extracting text from footer"
the only difference is that mine is a header (a little bit long header)
Can anyone help with this?


 3
Replies
3
3
Replies
3

Copy link to clipboard
Copied
Hello,
Are you able to solve the issue? I am also having similar issue and not able to get information from the header. If no luch with this api have you explored any other tool which can solve this problem for us. Thanks

Copy link to clipboard
Copied
Same here. Seems like something that's actively ignored in the parsing. A simple flag in the oprions to get the headers and footers would be great. Really a big issue here with what seems like an easy solution and even though the community seems to have been asking for it for a while, it still isn't available.

Copy link to clipboard
Copied
The Extract PDF API is nothing to do with Acrobat or Acrobat Reader (despite any name suggesting otherwise). That means it is outside our knowledge, and the chances of getting help here are very small.
Please try the "Acrobat Services API" forum https://community.adobe.com/t5/acrobat-services-api/ct-p/ct-Document-Cloud-SDK?page=1&sort=latest_re...

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices
{kind=link}