
Question
Issue with visualizing JSON to html
I'm having problems is in the interpretation of the json. In the attached example (which were generated by an Adobe community user) I can see page 108 from the document correctly visaulised, but in my case it looks like this:

I'm using php for the html code:
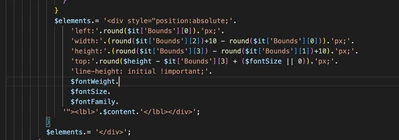
Can anyone guide me a bit about the coordinates and if I should create any other element apart from the "div"?
Thanks
Mark