Answered
OCR capabilities
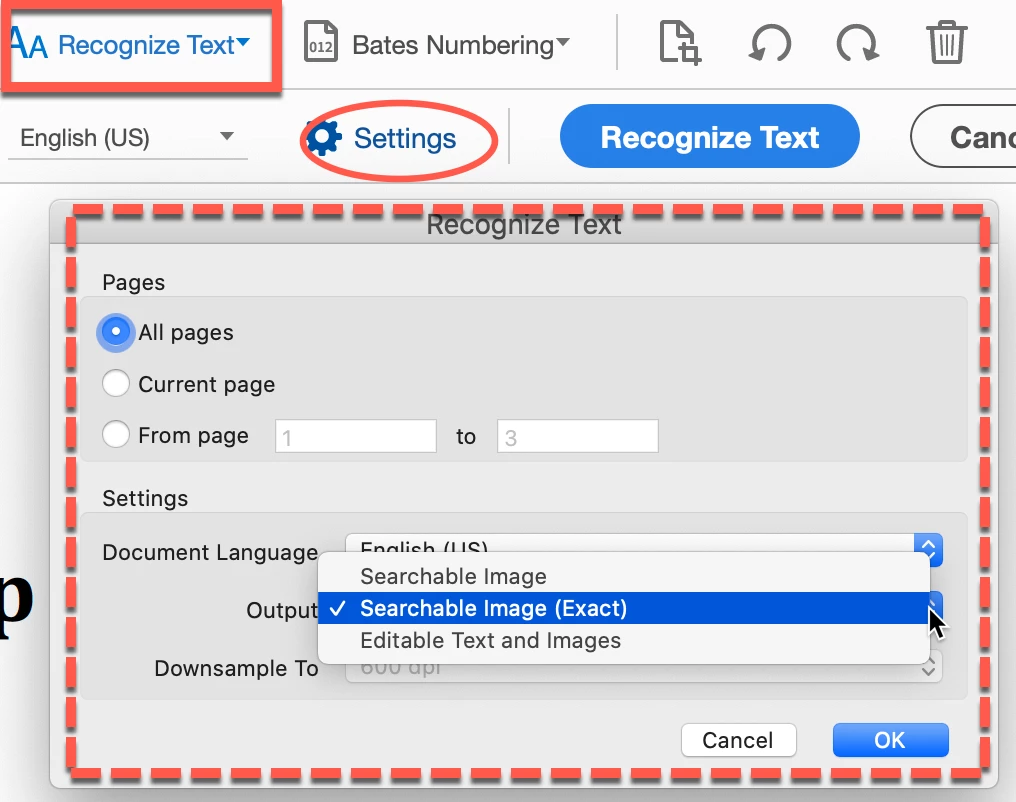
I have just subscribed to Adobe Acrobat PRO with big expectations on its OCR capabilities, but instead I am getting dissapointed fast. When aplying "enhace" to an existing B&W scanned .pdf document, Acrobat does recognize the text, but I was expecting that it woud make possible to completely substitute the old text by the new version. However, the old text remains there completely uneditable and unremovable. I have being playing with some of the settings like "background Removal" > high, but no change is noticable. I would apreciate any small advice in case I am missing something. Thanks!