


Migrating from CF10 to CF12 - Monitor Your App!
I'm posting this for others that may follow or are having performance issues with CF12, although this probably relates to CF11 too.
I was having issues with my migration from CF10 to CF12, specifically around memory management. This is going from Java 7 to Java 8, so my JVM.config settings didn't carry over and the defaults were negatively affecting my apps performance.
I'm not pushing Fusion-Reactor specifically, I don't get paid by them, but it’s one of the first tools I recommend to those running CF. You really have to monitor your app to know what it’s doing. One of the things I really like about this tool is the section that monitors Memory Spaces. This changes based on the type of GC you’re doing.
My app performs best with -XX:+UseConcMarkSweepGC -XX:+UseParNewGC , so I have CMS Old Gen, Code Cache, Compressed Class Spaces, Metaspace, Par Eden Space and Par Survivor Space available in the tool. I tried -XX:+UseG1GC, but it was sporadic. I may revisit it later, but it just wasn’t working for me.
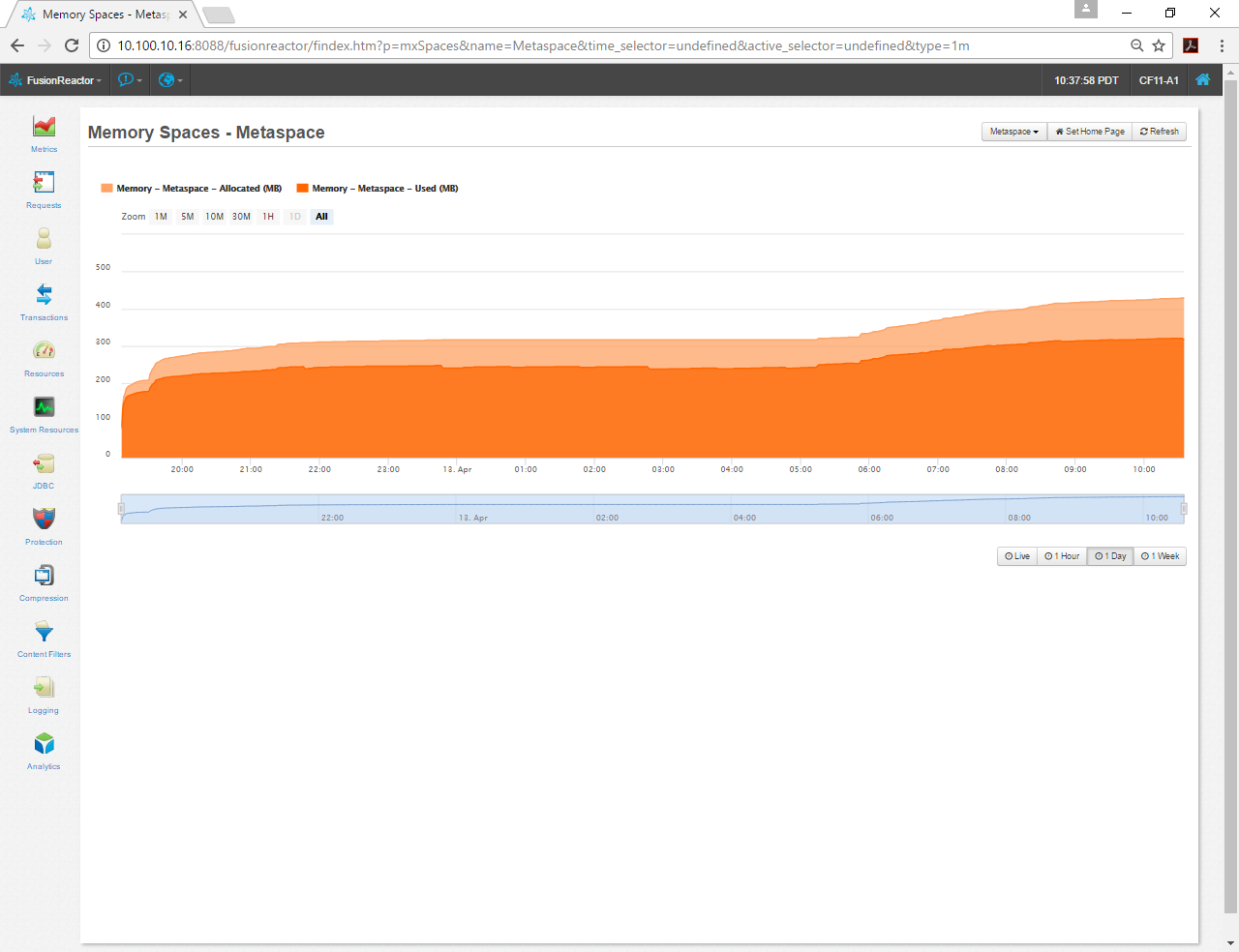
The first obvious thing was the Metaspace, the default size of -XX:MaxMetaspaceSize=192MB was too small. This instance has been running for a day and the charts shows I’m using closer to 320MB. I increased this setting with these two arguments -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m. These are pretty much a replacement for -XX:PermSize -XX:MaxPermSize in Java 7.
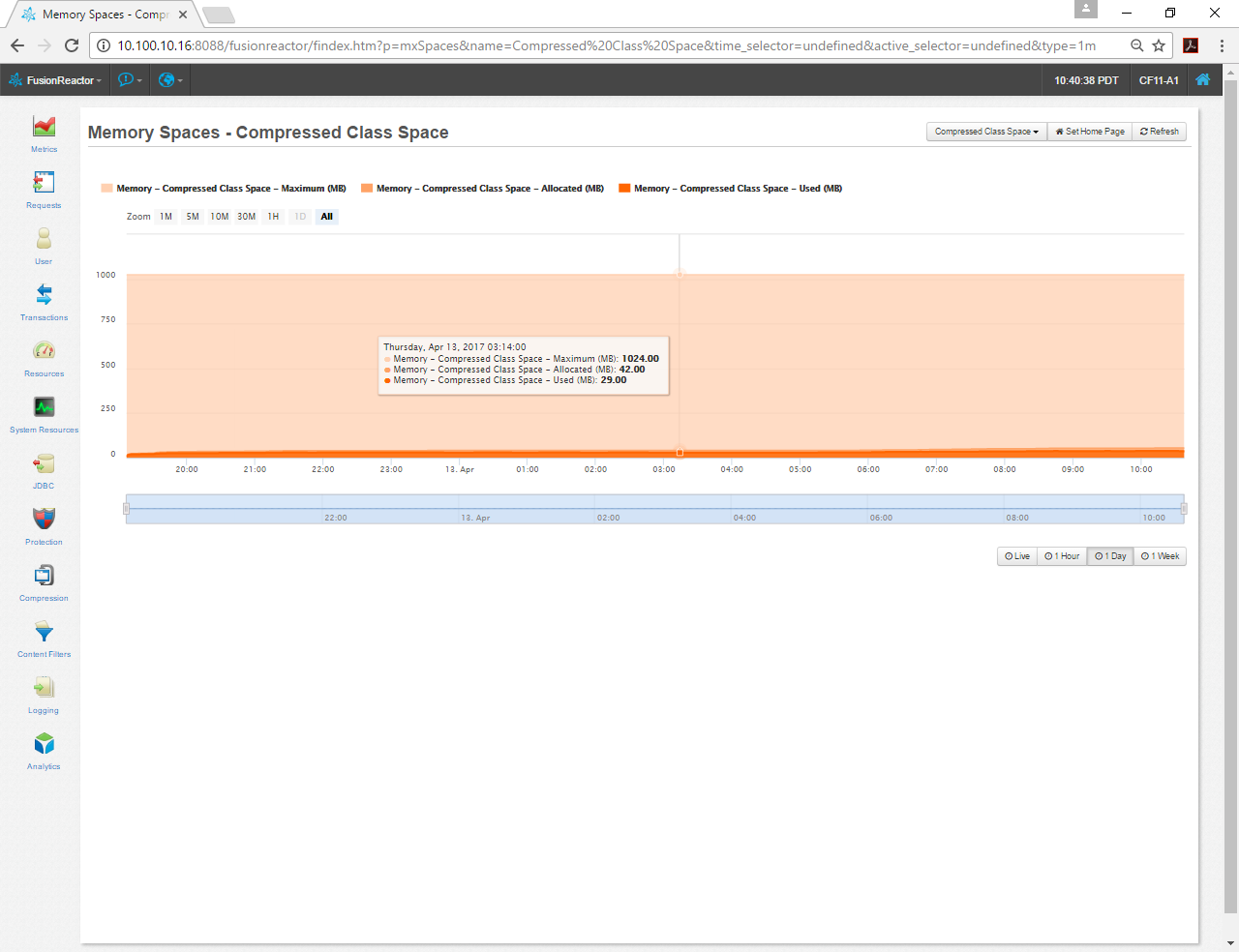
I next noticed that the Compressed Class Space defaults to reserving 1024MB in Java 8. According to my chart, I’m using less than 50MB. This seems like a waste of memory, so I’m going to reduce the default with the -XX:CompressedClassSpaceSize=128m argument.
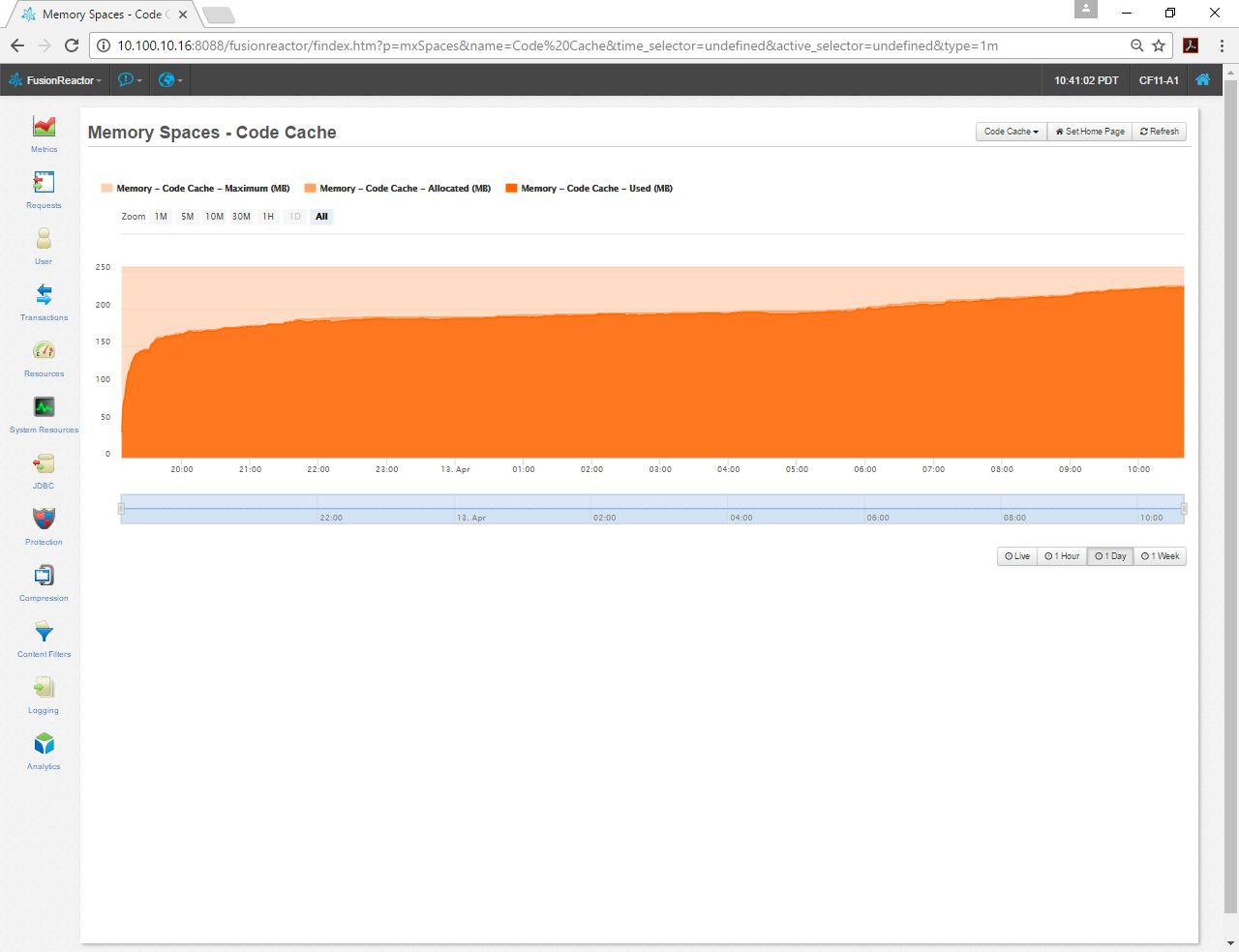
I then noticed that my Code Cache is a little close to maxing out, so I might increase that a little with the -XX:ReservedCodeCacheSize=384m argument.
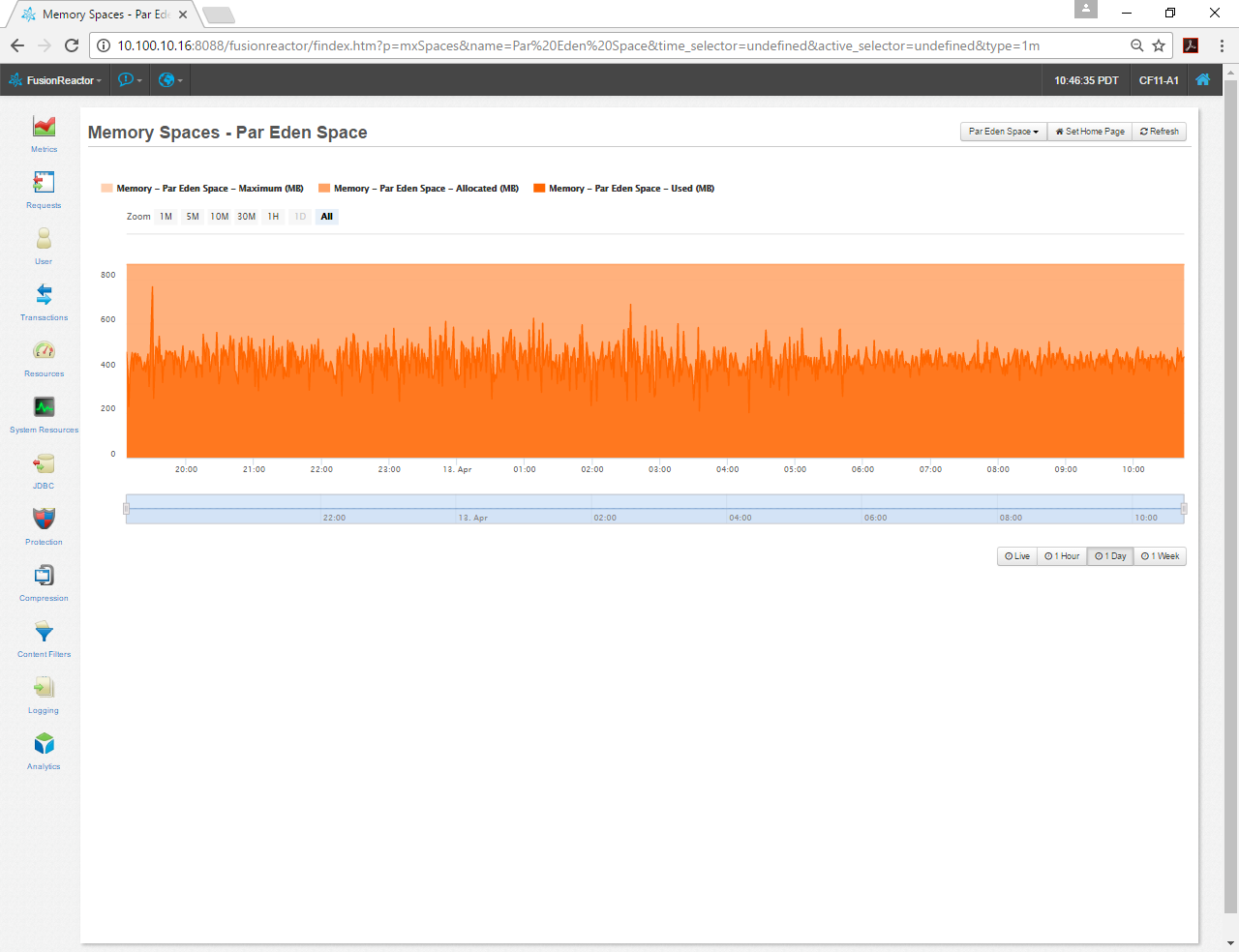
My Par Eden Space looks pretty good, so I’m going to leave that, but if I had issues I might look at these arguments and how they affect my app. -XX:NewSize=1024m -XX:MaxNewSize=2048m -XX:SurvivorRatio=6 -XX:TargetSurvivorRatio=100 -XX:-UseAdaptiveSizePolicy
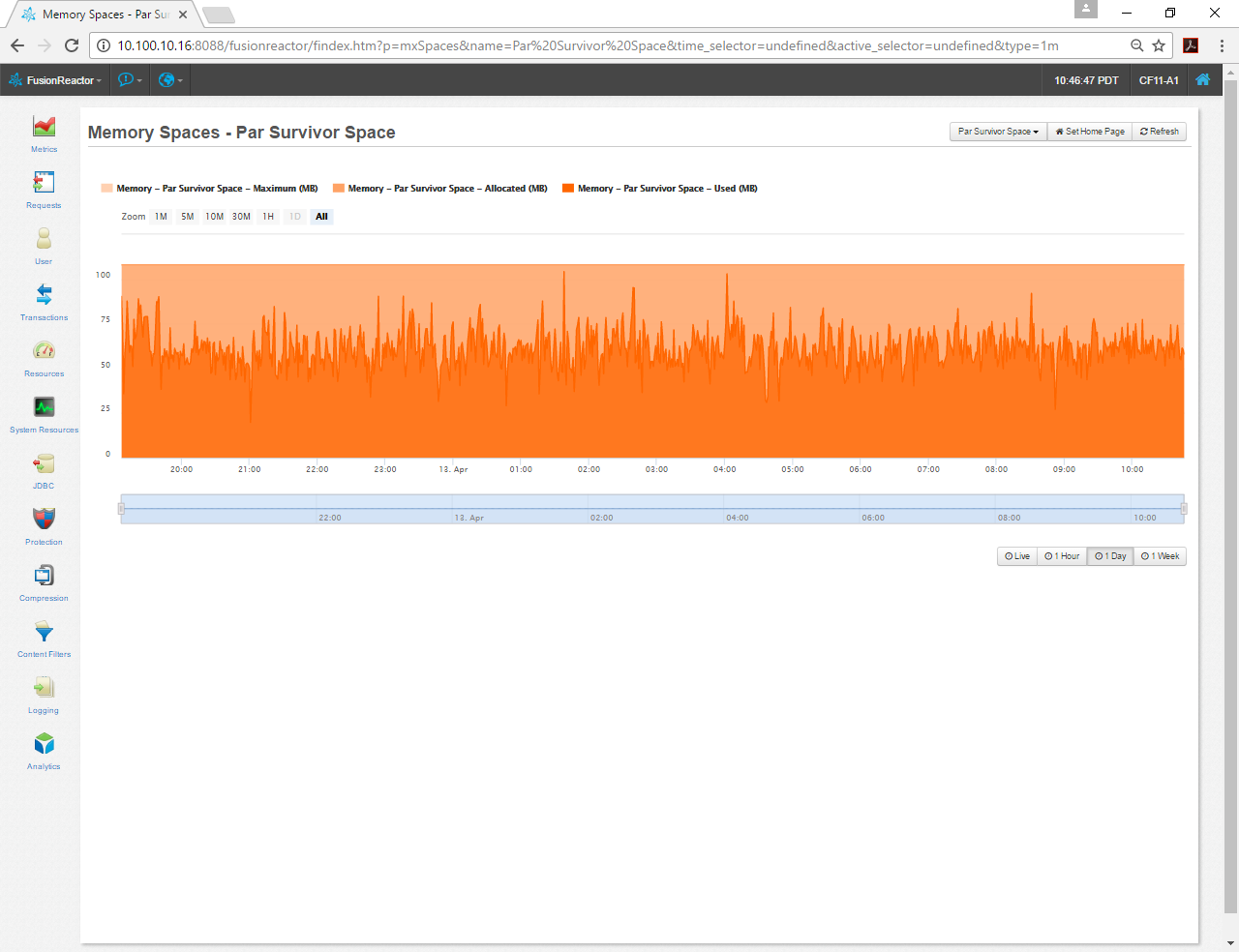
Par Survivor Space looks pretty good too, so I’ll leave it alone.
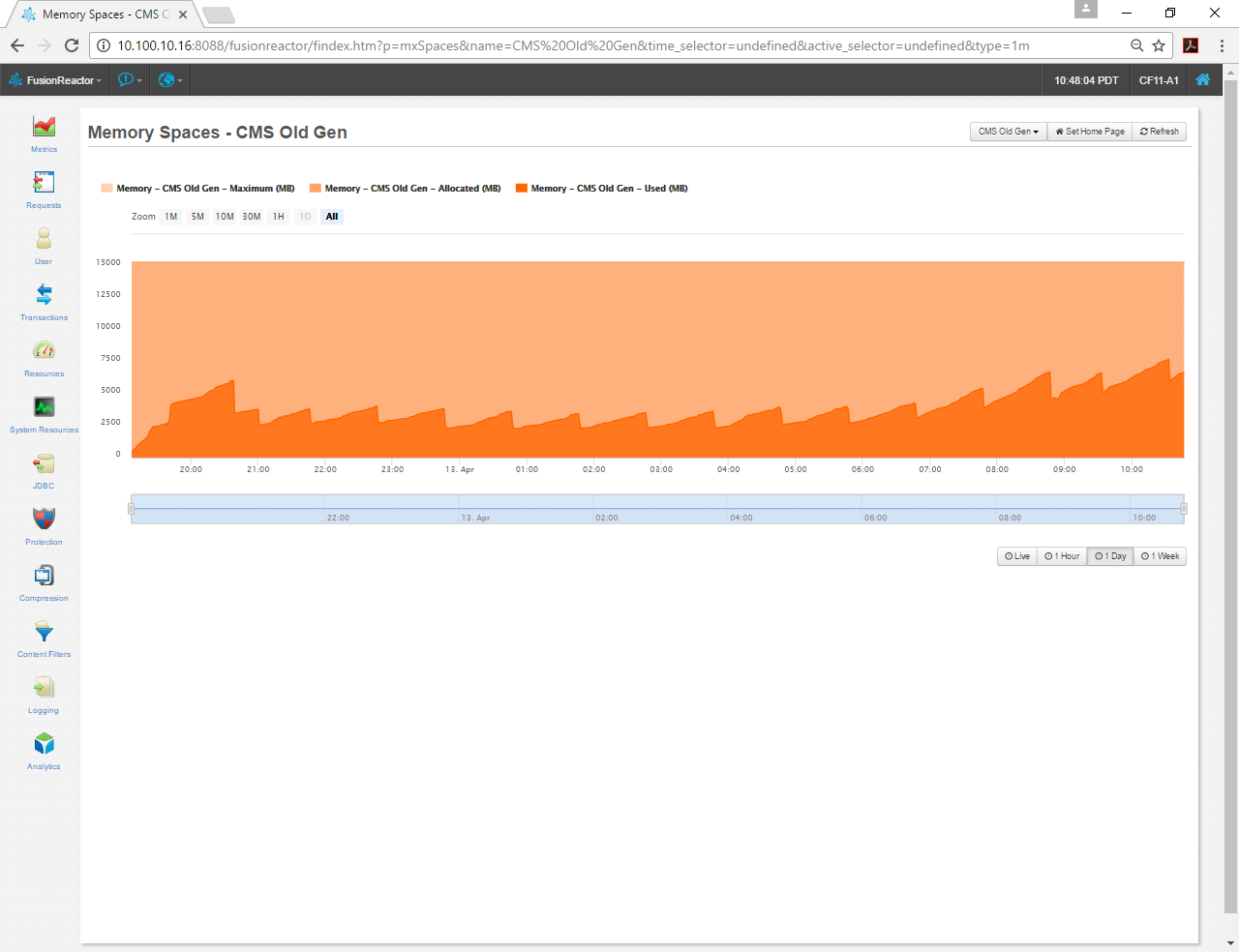
My CMS Old Gen, that’s set with the arguments -Xms16g -Xmx16g, has plenty of space and GC is doing its job. This instance has only been runnign for 24 hours, so I'll give it a few days. I don't want to give it too much space, because that can cause problems of its own. This app gets about 1 million requests a day and can vary on its workload, so I tend to oversize my heap. I may reduce it a little after I’ve monitored to see where it gets maxed out.
I'm going to give some credit to @carl_type3 for this post and re-post his suggestions that I came across while trying to figure out my new JVM settings for CF12. I found his post helpful and I hope you find this one helpful too. Good luck!
Here are some things to consider. CF11 is using Java 8? The RTM installer deployed Java 7 which is Oracle EOL. The refreshed CF11 installer deployed Java 8 (1.8.0_15).
It can be useful sometimes to set minimum and maximum memory the same.
-Xms6144m -Xmx6144m
Java 8 parameter MaxMetaspaceSize=192m is fair to say small so increase that and define an initial setting.
-XX:MetaspaceSize=312m -XX:MaxMetaspaceSize=640m
There are other Java memory spaces in use so you can tune those to match your load better.
-XX:ReservedCodeCacheSize=724m -XX:CompressedClassSpaceSize=296m
What values to use? Do some traditional Java monitoring to a log and read the log or enable JMX and use some JDK tools like jconsole.
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -verbose:gc -Xloggc:cfGC.log
-Dcom.sun.management.jmxremote.port=8709 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
Java manages objects with garbage collectors (GC). You could be experiencing a pause effect from GC routine. So perhaps try a newer or more modern garbage collector. For that you would remove -XX:+UseParallelGC.
-XX:+UseG1GC
Another idea for GC is to change to low pause. Ditto to remove -XX:+UseParallelGC.
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
Or stick with throughput GC -XX:+UseParallelGC but provide some tuning to it.
-XX:+UseParallelGC -XX:ParallelGCThreads=16 -XX:MinHeapFreeRatio=40 -XX:MaxHeapFreeRatio=70
The aforementioned G1GC and ConcMarkSweepGC also offer tuning settings, so search on those.
Sometimes Java 8 adaptive sizing does not suit the load after many GC cycles so you might like to manage the New part of heap (made up of Eden and 2 survivor spaces) by defining settings. Note not with G1GC.
-XX:NewSize=2048m -XX:MaxNewSize=2048m -XX:SurvivorRatio=6 -XX:TargetSurvivorRatio=100 -XX:-UseAdaptiveSizePolicy
Similarly tomcat offers performance settings by defining pool, thread size settings and timeout.
EG workers.properties
worker.cfusion.connection_pool_size = 400
worker.cfusion.connection_pool_minsize=100
worker.cfusion.connection_pool_timeout = 60
EG server.xml AJP section
maxThreads="400" minSpareThreads="100" connectionTimeout="60000"
HTH, Carl.