

- Home
- InDesign
- Discussions
- Re: Is there any method to avoid hyphenation befor...
- Re: Is there any method to avoid hyphenation befor...

Copy link to clipboard
Copied
I am using FML Malayalam fonts (not based on Unicode) to design a newspaper. Hunspell dictionaries are totally useless for these kind of fonts. In Malayalam language some characters have to go along with other characters to make it meaningful. Eg. കാടി - in this word of four charecters the first and third characters are constants while second and fourth characters act like vowels. But we cannot seperate a constant from its vowel and these vowel charecters appear after almost every constants in every words.
In FML Malayalam fonts all characters appear seperately. The letters in this font are assigned to english letters and symbols.
Hence I am looking for a way to keep them together in every word throughout a document. I have already tried adding charecters with along with tildes to dictionary but that also doesn't work well as some charecters are assigned to symbols like '(,{,]', etc. As there are numerous words in the language, Adding words to dictionary with hyphenation properties is also not an easy option
I even tried using Nonbreaking hyphen feature but turns out that while joining one word, another two or more breaks.


 1 Correct answer
1 Correct answer

Instead of keeping together CV (consonant+vowel) pairs, maybe it's better to insert discretionary breaks after CV pairs:
Find what: [IJKLMNOPQRSTUWVXYZ\[\\\]\^_`abcdefghijkl¡¢£¤¥\¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ ×ØÙÚÛÜÝÞßàáâãäåï∙]\K([mnopqruvwxyz])
Change to: $1~k
Which paraphrases as 'Find V preceded by C, replace the V with itself and discretionary line break'. Note the added backslashes before [ \ ] and | -- these are special symbols in Grep, and you need to indicate that you're
... 12
Replies
12
12
Replies
12

Copy link to clipboard
Copied
One of the things you could look at doing is create a character style that ONLY has the "No Break" option enabled, and then create a basic paragraph style in which you use apply this character style to the letter pairs that are not allowed to break using a GREP style, and use the basic paragraph style as the foundation for the core styles in your templates. E.g. base body-copy on it, and then you can base other styles on body-copy e.g. bulleted lists etc.
Character style:
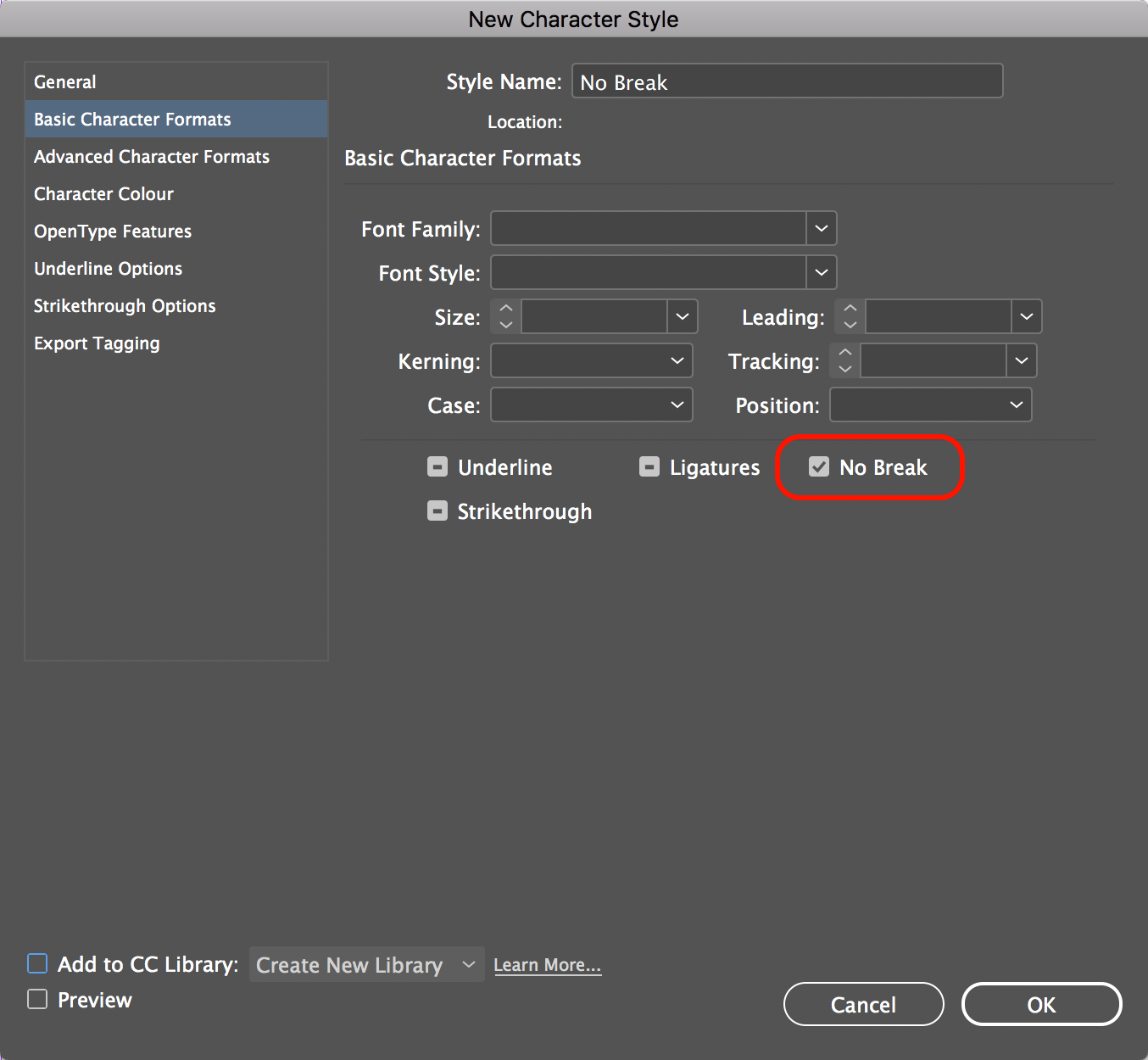
Paragraph style:
[1] Select the Character style
[2] enter the letter pair
[3] click New GREP Style to insert another one for the next letter pair, and repeat [1] and [2]
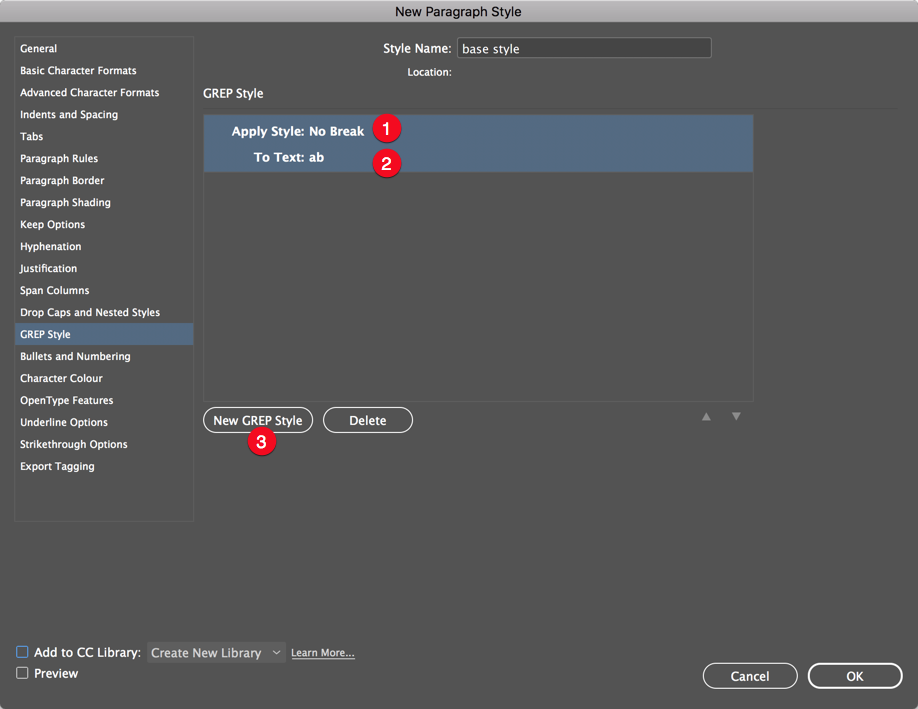
Copy link to clipboard
Copied
There are over 60 consonants in malayalam language, and over 20 vowels. The letters are assigned to all character keys on the keyboard. Even if I were to create pairs, I would have to make them for 60 consonants with these 20 vowels, thats 60*20=1200 pairs. Creating 1200 pairs of GREP styles is not feasible.
Copy link to clipboard
Copied
… But, in this case, play 1,200 pairs with 1 grep style is simple!
Best,
Michel, for FRIdNGE
Copy link to clipboard
Copied
Civi -- I don't think you should do this with a Grep style: it would slow down your documents if those documents are, say, 50 pages or more. What you want is simple enough with one Grep query that yo can save as a query. Or you could make it part of a bigger script to process a document, if you use any such script.
I don't know Malayalam, but you say that you want to keep together combinations of consonants and vowels. If I were to do for English I would use this query (in the Grep tab of the Find/Change dialog):
Find what: [bcdfghjklmnpqrstvwxz][aeiouy]
Change to: <no break>
The Find string paraphrases as 'a consonant followed by a vowel'. You say that Malayalam has more than 60 consonants and 20 vowels, but you need to enter them just once.
Peter

Copy link to clipboard
Copied
One thing confuses me here 
What if a consonant followed by a vowel is the only possible situation in a language? If all words are made of such pairs? Well, most of them (who knows except OP)?
The result then would be effectively the same as just turning hyphenation off, wouldn’t it? Fully tied up with no break, like English words below: some, have, make…

Copy link to clipboard
Copied
I am working on a local newspaper, hence i have to keep text justified and there would be lot of spacing issues if I turn off hyphenations.
This is a sample of what I am working on

Copy link to clipboard
Copied
Hi Civi,
I would like to know if the steps suggested above worked for you, or the issue still persists.
Kindly update the discussion if you need further assistance with it.
Thanks,
Srishti
Copy link to clipboard
Copied
That also didnt work well as expected. As i had mentioned earlier, the malayalam letters are assigned to all keys on keyboard including the symbols.
These are the Malayalam consonants:
IJKLMNOPQRSTUWVXYZ[\]^_`abcdefghijkl¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåï∙
These are vowels that come before a consonant:
st{
And these are vowels that come after a consonant:
mnopqruvwxyz
I still hope there might be some method to get this working in InDesign.
Copy link to clipboard
Copied
Instead of keeping together CV (consonant+vowel) pairs, maybe it's better to insert discretionary breaks after CV pairs:
Find what: [IJKLMNOPQRSTUWVXYZ\[\\\]\^_`abcdefghijkl¡¢£¤¥\¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ ×ØÙÚÛÜÝÞßàáâãäåï∙]\K([mnopqruvwxyz])
Change to: $1~k
Which paraphrases as 'Find V preceded by C, replace the V with itself and discretionary line break'. Note the added backslashes before [ \ ] and | -- these are special symbols in Grep, and you need to indicate that you're looking for the literal characters. (That's probably why it didn't work for you earlier.)
This probably works better because keeping various combinations together doesn't guarantee that words will break at every permissible place.
Copy link to clipboard
Copied
That worked out pretty well and solved a majority of the problem.
But in this language, there are few vowels that go before the consonants (s,t,{) and few pairs pairs of vowels that hold consonants between them (s#m & t#m, (where # denotes the consonant)).
There are also few vowels(y,z) that come after the consonants that may sometimes come in between consonants and other vowels.
There is also a vowel (w) that may sometimes follow all other vowels.
There is also a vowel ({) that sometimes goes between the preceding vowel and the consonant.
eg: for the word 'chrome' or 'krom', malayalam looks like 'ക്രോം' (using keys t{Imw ) and for 'kyom', it looks like 'ക്യോം' (using keys tIymw ). In these words of 5 characters each, 'ക' is the only consonant,while the rest are vowel like characters. For the first word, there are 2 vowels preceding and conceding the consonant while there are 3 vowels conceding the second word.
I know this is too confusing, but that is how the language is. If I could get the code for fixing these characters, it would be extremely helpful.
Copy link to clipboard
Copied
You list some non CVCV patterns but not where those words with these patterns can be divided.
Copy link to clipboard
Copied
Sorry, know nothing about Malayalam language…
Speaking in terms of Latin languages, this will found any word character
a\K\w
or just any character
a\K.
that follows character a.
You can apply nobreak char style to it, and pairs aa, ab, ac, ..., az, a1, a9, or even a’, a:, a! and so on (using the second regex) will never break.
Also you can make it case-insensitive:
(?i)a\K\w
Hopefully this can help you to find a suitable solution.
Note: these regex will work on CS6 and higher. For lower versions you should use regular Positive Lookbehind: (?<=a)\w or (?<=a). instead of \K

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices