

- Home
- InDesign
- Discussions
- Re: Slug need only for cover page while exporting
- Re: Slug need only for cover page while exporting
Slug need only for cover page while exporting

Copy link to clipboard
Copied
Hi All,
I need slug information only for cover page (page 1). Rest of pages need not the slug portions. I cant able to figure how to give page range for this slug informations.
Tried coding:
var myDocument = app.activeDocument;
var myFileName;
var myPDFExportPreset = app.pdfExportPresets.item("[Smallest File Size]");
if (myDocument.modified == false) {
myFileName = myDocument.fullName + "";
if (myFileName.indexOf(".indd") != -1) {
var myRegularExpression = /.indd/gi;
myFileNamePDF_Print = myFileName.replace(myRegularExpression, ".pdf");
}
with(app.pdfExportPreferences) {
pageRange = "1"
includeSlugWithPDF=true;
}
with(app.pdfExportPreferences) {
pageRange = "3-6"
includeSlugWithPDF=false;
}
myDocument.exportFile(ExportFormat.pdfType, new File(myFileNamePDF_Print),false,myPDFExportPreset);
} else {
alert("Save your file before continuing");
}
Thanks,
K


 15
Replies
15
15
Replies
15

Copy link to clipboard
Copied
The slug is a document-global setting.
One thing you can do is export two PDFs (one for the cover, including the slug area and one for the body, without slug) and combine them afterwards.
Another would be to make your cover page bigger as to "fake" the slug area, and export the pdf, but this will mess up the pdf page/trim etc boxes.
Copy link to clipboard
Copied
Thanks Vamitul, so for i am doing the combine work (creating two pdf and then combine) manually. So trying to simplify the work.
Copy link to clipboard
Copied
You could via a single script:
1) export the cover
2) export the body
3) create a new document
4) import the cover in the new document
5) import the body in the new document
6) export the new document as "final" pdf.
Copy link to clipboard
Copied
Thanks Vamitul, but it will lost the resolution.
Do we have any other suggestions please?
Copy link to clipboard
Copied
If you are "loosing resolution" you are doing the pdf export wrong. Check out http://www.indesignjs.de/extendscriptAPI/indesign12/#PDFExportPreference.html

Copy link to clipboard
Copied
Vamitul wrote:
(…)
Another would be to make your cover page bigger as to "fake" the slug area, and export the pdf, but this will mess up the pdf page/trim etc boxes.
Hi Vamitul,
I'm trying to understand that particular issue (as I'm not very skilled in PDF exporting.) What exactly would be messed up with respect to the result obtained by combining two distinct PDFs?
Say I have faked in InDesign a slug area on page 1, as you suggest. Something like this:

After exporting these pages I get this result:
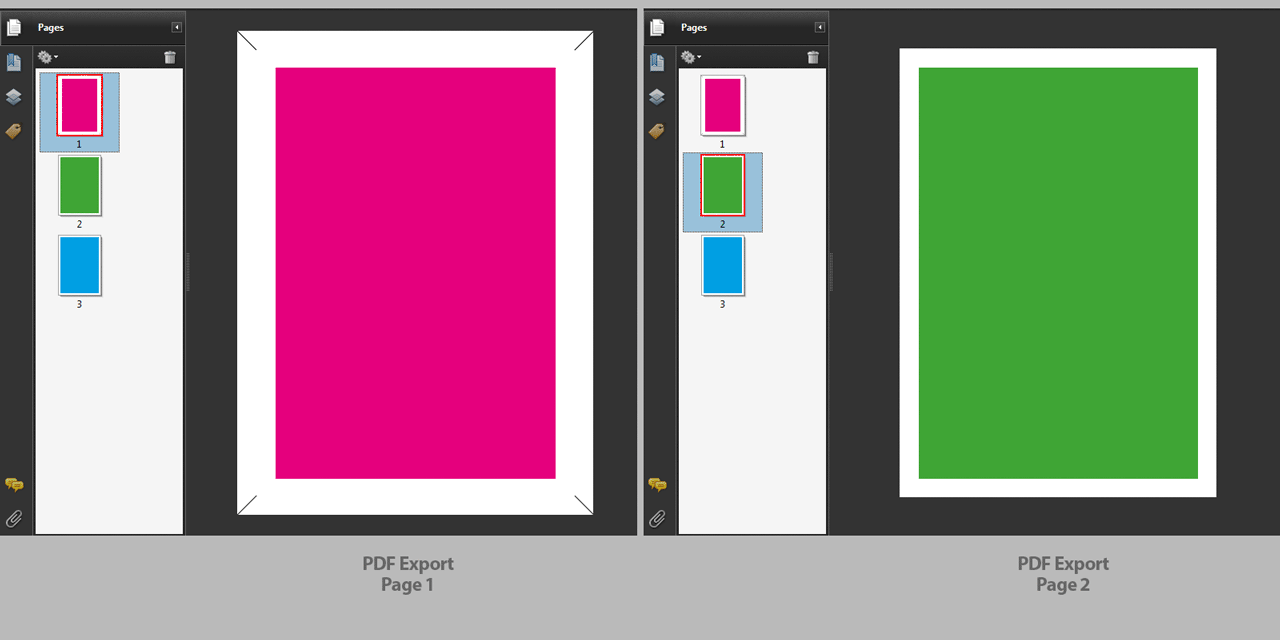
I do not pretend there is no problem, my problem is I can't figure out what is the problem 😉
Thank you to enlighten me.
Best,
Marc
Copy link to clipboard
Copied
Marc, the PDF only looks ok, but the Trim Box for the first page is messed up. More info on the various PDF Boxes: The PDF page boxes: MediaBox, CropBox, BleedBox, TrimBox, ArtBox
Just please don't ask me how to view the page boxes in this "new and improved" Acrobat Pro, because i can't find it.
Copy link to clipboard
Copied
Ok, thanks.
So the question amounts to, could we hack PDF's inner data in a way that restores actual values for page size, bleed, slug etc?
(Or something like that.)
Copy link to clipboard
Copied
So the question amounts to, could we hack PDF's inner data in a way that restores actual values for page size, bleed, slug etc?
Sure. But it requires writing a jsx PDF parser. Not quite impossible, particularly that there are a number of JS based parsers on GitHub, but I never had the energy and the need to go into it in more detail.
You, on the other hand, I can't think of anyone better suited to build such a thing 

Copy link to clipboard
Copied
Vamitul wrote:
So the question amounts to, could we hack PDF's inner data in a way that restores actual values for page size, bleed, slug etc?
Sure. But it requires writing a jsx PDF parser. Not quite impossible, particularly that there are a number of JS based parsers on GitHub, but I never had the energy and the need to go into it in more detail.
You, on the other hand, I can't think of anyone better suited to build such a thing
Hi Vamitul,
interesting. There is one attempt to parse a PDF file with ExtendScript in Scott Zanelli's famous MultiPageImporter script. However, it will fail if the PDF is saved with Acrobat's "optimize" feature. I do not test if InDesign is able to export PDFs like that.
Regards,
Uwe
Copy link to clipboard
Copied
Uwe, I'm not familiar with Scott Zanellis' script, but I do know all the issues I've encountered in my own scripts when trying to determine the page count of a pdf file (after a lot of frustration, i've given up and used the same method as the sample script - import pdf pages until they repeat). That is because the PDF standard is fairly lax and with a lot of fallbacks, and different vendors implement different ways of representing the structure of the document (Corel being the worst example I encountered, followed by MS Office's pdf export engine).
In this particular case, however:
1. we know that the source pdfs come from InDesign, so they are quite close to the standard.
2. The definition of the Page object and the Page Boxes objects is one of the few things in the standard that leaves little room for "creative interpretation".
Copy link to clipboard
Copied
After having a quick look through the PDF specs and documentation (http://wwwimages.adobe.com/content/dam/Adobe/en/devnet/pdf/pdfs/PDF32000_2008.pdf ), post-editing the boxes does not seem so difficult:
you need to find the page tree (something like <</Count 1/Kids[13 0 R]/Type/Pages>> where each part of the Kids array is a reference to a page dict). Using that dict reference you can then find the actual page object that looks like:
13 0 obj
<</ArtBox[0.0 15.0518 396.975 367.209]/BleedBox[0.0 0.0 453.54 380.0]/Contents 233 0 R/CropBox[0.0 0.0 453.54 380.0]/Group 234 0 R/LastModified(D:20160205132408+02'00')/MediaBox[0.0 0.0 453.54 380.0]/Parent 3 0 R/PieceInfo<</Illustrator 235 0 R>>/Resources<</ExtGState<</GS0 236 0 R/GS1 237 0 R/GS10 238 0 R/GS2 239 0 R/GS3 240 0 R/GS4 241 0 R/GS5 242 0 R/GS6 243 0 R/GS7 244 0 R/GS8 245 0 R/GS9 246 0 R>>/Font<</C2_0 226 0 R/TT0 225 0 R/TT1 227 0 R>>/ProcSet[/PDF/Text]/Properties<</MC0 228 0 R/MC1 229 0 R/MC2 230 0 R/MC3 231 0 R>>/Shading<</Sh0 247 0 R/Sh1 248 0 R/Sh2 249 0 R>>/XObject<</Fm0 250 0 R/Fm1 251 0 R/Fm10 252 0 R/Fm11 253 0 R/Fm12 254 0 R/Fm13 255 0 R/Fm14 256 0 R/Fm15 257 0 R/Fm16 258 0 R/Fm17 259 0 R/Fm2 260 0 R/Fm3 261 0 R/Fm4 262 0 R/Fm5 263 0 R/Fm6 264 0 R/Fm7 265 0 R/Fm8 266 0 R/Fm9 267 0 R>>>>/Thumb 268 0 R/TrimBox[0.0 0.0 453.54 380.0]/Type/Page>>
endobj
and there, as you can see you have all the boxes info, that you can modify to your hearts desire.
Copy link to clipboard
Copied
Vamitul wrote:
Marc, the PDF only looks ok, but the Trim Box for the first page is messed up. More info on the various PDF Boxes: The PDF page boxes: MediaBox, CropBox, BleedBox, TrimBox, ArtBox
Just please don't ask me how to view the page boxes in this "new and improved" Acrobat Pro, because i can't find it.
Hi Vamitul,
like Marc I'm trying to understand the problem.
The net format of a page will dictate the size and position of the TrimBox within the MediBox.
So your TrimBox on page one is not messed up. It's no bug.
It's simply the way InDesign is working.
Placed PDF files will be stripped off their initial PDF box information when printed or exported again.
And that's not only ok it is necessary. Otherwise placing PDFs of any kind would mess up our workflows.
So the whole exercise placing and exporting the PDFs again is fruitless and the assembling of pages should better be done with Acrobat Pro or a different PDF post-production tool.
Unless you want to write some pdfmark code, place it as EPS on every page, print to PostScript and distill to PDF.
I can remember that Robert Zacherl of Impressed GmbH, Germany did an EPS like that about 15 years ago.
But this is no solution today where transparency should stay intact and PDF export should be used instead of printing to PostScript, exporting to EPS and distilling to PDF.
Pdfmark code with imported EPS files on InDesign pages will be ignored by the PDF export mechanism.
FWIW: Here an impression of pdfmark code written in PostScript from 2004 where someone wanted to fix a bug with inDesign CS print to PostScript feature:
PDFX3 - Fehler im Begrenzugsrahmen - PDF in der Druckvorstufe - HilfDirSelbst.ch - Forum
Other workflows:
1. Editing the exported PDF by ExtendScript.
Would require some experimenting and knowledge of PDF.
I think, yes, that can be done.
2. Using BridgeTalk to force Acrobat Pro to change the TrimBox?
Only doable with Acrobat 7 or 8 on Windows; at least Kasyan Servetzky had a working solution for this. With an older version of inDesign. Cannot be done with current versions.
3. Using Acrobat Watched Folders with Acrobat Preflight automatisms?
Doable, but is that worth the effort? Maybe would also require some custom JavaScript for Acrobat…
Regards,
Uwe
Copy link to clipboard
Copied
And there is (or at least was) also a way to concatenate several PostScript files (with different PDFBox settings) using Acrobat Distiller. With Distiller 7 that once worked as expected. For Distiller 8 and 9 this method would require a change in com.adobe.distiller9.plist on Mac OSX. Did never test that with Windows. And I never tested this procedure with newer versions of Acrobat Distiller and newer OSX versions.
It was fun digging out this old method of the "Golden Age of PostScript" 🙂
As I said the method requires some preparation:
Acrobat Distiller restriction on directory access
Beginning with Acrobat 8.1, Distiller® restricts the directories that PostScript® file operators can access. The new default behavior limits directory access to the temp and font cache directories. Earlier versions of Distiller allowed PostScript file operators to have unlimited directory access.
The following Distiller settings enable unlimited directory access. Such unlimited access can pose security problems.
Microsoft® Windows®: -F command line option
UNIX®: -allowfileops command line option
Apple Mac OS: AllowPSFileOps user preference
The change in com.adobe.distiller9.plist should be done with the Property List Editor.app of Mac OSX. Don't know, if ExtendScript is able to it as well. At least you'd need some admin rights on the system, I think.
Here a screenshot from OSX 10.6.8 with an unchanged Adobe Distiller 9 plist file:
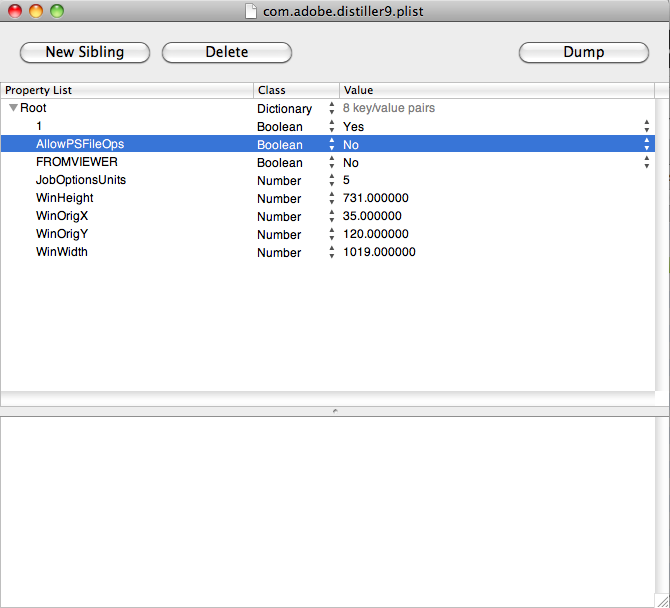
Property AllowPSFileOps should be changed from No to Yes.
The core of this method is the following text file, that will be:
1. Stored in a watched folder of Distiller with a dedicated joboptions-file
2. Can be dropped to Distiller
3. or opened with Distiller
and will concatenate all files with suffix *.ps in a folder you define in the text file by using the below PostScript functionionality.
Best use a text only file with a suffix that is not *.ps. For details read the instructions in the comment section below.
The name of the distilled PDF will be the name of that text file.
%!
% PostScript program for distilling and combining an entire folder or
% directory of PostScript files.
% When embedding font subsets, it is highly recommended you use this technique
% to distill multiple PS files so only one font subset is used for each font.
% Edit the next line to point to the folder containing the PS files:
/PathName (Macintosh HD:ACROBAT_Distiller9_RunDirEx:*.ps) def
/RunDir { % Uses PathName variable on the operand stack
{ /mysave save def % Performs a save before running the PS file
dup = flush % Shows name of PS file being run
RunFile % Calls built in Distiller procedure
clear cleardictstack % Cleans up after PS file
mysave restore % Restores save level
}
255 string
filenameforall
} def
PathName RunDir
% INSTRUCTIONS
%
% 1. Place all PostScript files to be distilled and concatenated in a single
% directory. For example, here are example names of PS files that might
% be used to distill a book:
%
% ac001.ps Cover
% bt001.ps Table of Contents
% ch001.ps Chapter 1
% ch002.ps Chapter 2
% ch003.ps Chapter 3
% in001.ps Index
%
% 2. Make a copy of this file and give it the name you want to have as the prefix
% for the resulting file. For example, you could name this file MyBook.txt.
%
% IMPORTANT: Don't use the .ps suffix if this file is in the same folder as the
% rest of your .ps files. The RunDir command will execute all files that end in
% .ps and this file will be distilled twice!
%
% 3. Redefine the variable "PathName" above to point to the folder/directory which
% contains your PS files.
%
% Macintosh pathname syntax: /PathName (Macintosh HD:Folder:*.ps) def
% Windows pathname syntax: /PathName (c:/mydir/*.ps) def
% UNIX pathname syntax: /PathName (.\\/mydir\\/*.ps) def
%
% Note: The syntax for Windows may look strange, but double escaping the
% backslash character is required when using filenameforall.
%
% 4. Distill the file on the machine running Acrobat Distiller.
Cheers,
Uwe
EDIT:
Added here the path to the plist in OSX 10.6.8
/User/[Username]/Library/Preferences/com.adobe.distiller9.plist
If you want to test this with e.g. newer versions of Distiller look for e.g.:
/User/[Username]/Library/Preferences/com.adobe.distiller10.plist
/User/[Username]/Library/Preferences/com.adobe.distillerDC.plist
So, yes ExtendScript has access to that plists.
Copy link to clipboard
Copied
Hello All,
Thank you for your contribution in this thread. I understood that we cant simply export the certain pages with slug are in Indesign.
So i decided to export the pages with slug and crop the unnecessary page slug using crop tool in Acrobat.
Regards,
K

 AdChoices
AdChoices