 Adobe Community
Adobe Community
- Home
- InDesign
- Discussions
- Two major issues with exporting Arabic/Farsi books...
- Two major issues with exporting Arabic/Farsi books...
Two major issues with exporting Arabic/Farsi books into epub

Copy link to clipboard
Copied
I am using Indesign 2022, A/E language, Ver 17.2 64-bit. I have been struggling to find the best possible way to export a 70-page book in Farsi/Arabic into an epub. Two issues are majorly affecting exporting an epub:
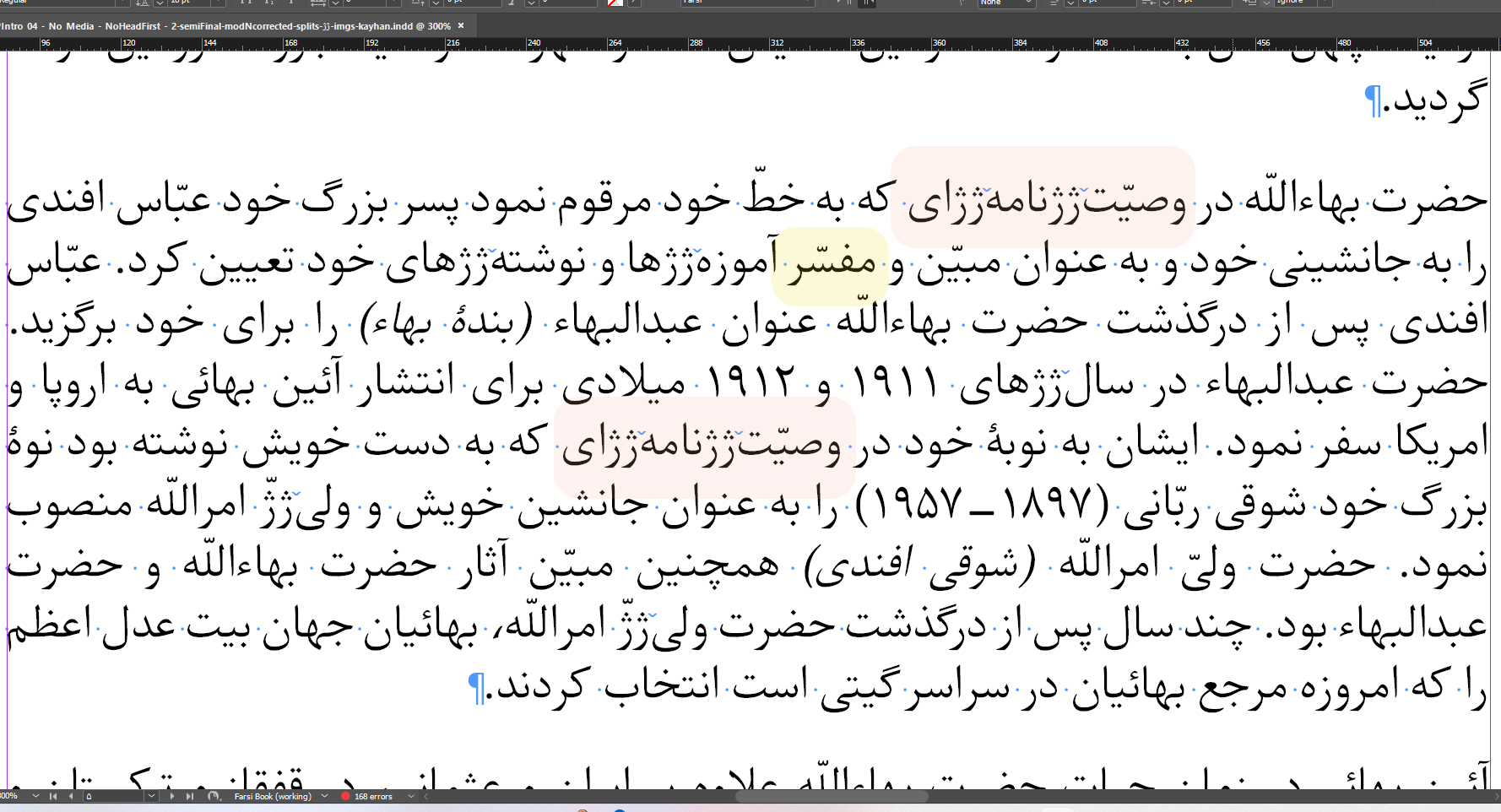
One: Indesign removes all non-joiner spaces. I have to add a new character instead of a non-joiner space and after exporting to epub, edit the book and replace the new character with non-joiner spaces. You can see the example in the image below, highlighted in pink. I have added (ژژ) in place of non-joiner space to be easily replaced after export. In a 70-page book, I had to change 700 occurrences.
Two: Indesign inserts span in the middle of the word in a sentence with no specifications or overrides and break the word. In the image below, the word مفسّر has been broken to مفسّر rendering the word meaningless. In English, such an example would be a break in between "wo" and "under." It needs to be noted that the book is set to RTL, paragraphs are right-justified, and the language is set to Farsi or Arabic.
I have added an image of what the text looks like in Indesign before export as well.
I hope someone can offer a solution


 6
Replies
6
6
Replies
6
Copy link to clipboard
Copied

Copy link to clipboard
Copied
Having followed several EPUB/RTL threads in recent months, I am coming to the conclusion that ID's export simply doesn't work reliably with RTL languages and layouts. I would guess that the variant processes are incomplete or at least incompletely tested.
Which means, I am not sure there is a fix for this.
I'd like to hear from anyone who's successfully exported an RTL document to EPUB with either no problems or readily fixable ones.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢
Copy link to clipboard
Copied
Hi NitroPress,
Eventually, I could correct the issues and create the book with no errors. I chatted with Adobe support to no avail as the follow-up emails I received blame the IDPF standard that has not concerned themselves as much with RTL with languages such as Arabic, Farsi, or Hebrew. However, I would like to ask how the non-joiner space gets wiped out when a document is exported into an epub?
The standards for XHTML and HTML are not that different. I create websites in HTML using non-joiner space all the time with no problems. So how come when it comes to exporting the similar text through Indesign, these spaces which are present in a PDF export are completely removed exporting to XHTML?
I can suggest minimizing too-complicated character styles in the text, which eliminates extra <span></span> in the content cutting down the breaks in words and sentences.
I am still open to any suggestion or guidance in streamlining exporting long documents (books and such) into epubs.
Copy link to clipboard
Copied
I had to look up (specifically) what a 'non-joiner space' is. As nearly as I can tell from little quick reading, it's a fairly new element in typography etc. and used mainly to interrupt ligatures, which I can see might be a more important issue in Farsi and Arabic. (It is, as I note, the very last item on the Special Character | Other menu. 🙂 )
A quick experiment of using one and export to HTML and EPUB shows it is not exported. Maybe this is a quirk of my English/LTR setup, but I'd suspect it's not fully supported in HTML, and thus stripped as an ID-level format element. (EPUB is, of course, XHTML/packaged web layout — I think you know that but I want this to be clear.)
I don't think there's a solution outside of editing the EPUB files after export. You could try a simple example, go in and add the non-joiner to an exported document, and see which if any EPUB and/or Kindle readers respect it. It may be supported, in HTML, only in advanced browsers.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢
Copy link to clipboard
Copied
Hi NitroPress,
I use the non-joiner in web design all the time. It is very simple for one of the Indesign developers to translate non-joiner to "&zwnj" (Zero-width-non-joiner in HTML) for XHTML. I have my website in Farsi as well as in English. You cannot find any issue with using the ZWNJ. (fa.zinatgroup.com)
There is more info on Wikipedia: https://en.wikipedia.org/wiki/Zero-width_non-joiner
Below, you can see the ZWNJ in different codes:
HTML Entity (decimal): ‌
HTML Entity (hex): ‌
HTML Entity (named): ‌
UTF-8 (hex): e2808c
UTF-8 (binary): 11100010:10000000:10001100
UTF-16 (hex): 0x200C
UTF-16 (decimal): 8204
C/C++/Java source code: "\u200C"
Copy link to clipboard
Copied
I have no argument; it does seem to be something that should be inherently supported. Puting in a feature request would be a good idea. (I'd guess it will take little more than adding it to a list of conversion items.)
But right now, it doesn't... so you need to consider a workaround until Adobe thinks it's worth addressing.
Something like a GREP or search-and-replace on the EPUB content file would be the direction I'd try.
—
╟ Word & InDesign to Kindle & EPUB: a Guide to Pro Results (Amazon) ╢

 AdChoices
AdChoices
{kind=link}
{kind=link}
{kind=link}
{kind=link}