Answered
TIFF画像をAcrobat DCでPDFにする際のOCRオフ
お世話になります。
スキャンしたPDFを開くときに、OCR機能をオフにするやり方はわかりました。
が、白黒画像(TIFF)として保存したファイルを、PDFで開くと、どうしても開くと同時にテキスト認識が始まってしまいます。
手元にあるTIFF画像をスキャンPDFとして取り扱いたいのに、不要なフォント情報が入ってしまうのです。
この機能をオフにすることはできないでしょうか。

お世話になります。
スキャンしたPDFを開くときに、OCR機能をオフにするやり方はわかりました。
が、白黒画像(TIFF)として保存したファイルを、PDFで開くと、どうしても開くと同時にテキスト認識が始まってしまいます。
手元にあるTIFF画像をスキャンPDFとして取り扱いたいのに、不要なフォント情報が入ってしまうのです。
この機能をオフにすることはできないでしょうか。
Windows 10+Acrobat DC Continious (2018.011.20038) で確認をしたのですが、
「スキャン補正」の「補正」→「スキャンした文書」で「テキスト認識」をOFFにしておけば、
「ファイルを結合」でOCR処理がなされることはありませんでした。
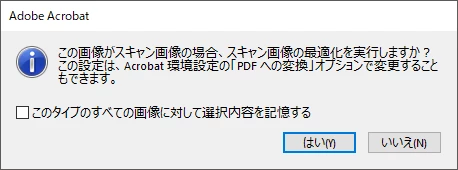
また、Acrobat DCのウィンドウへのドラッグドロップを行った場合、下記ダイアログは出ますが、
「いいえ」を押していればOCR処理が働くことはありませんでしたし、
その後ページサムネールに2値TIFFを入れてもOCR処理はされませんでした。
そうなると、バージョンとTIFF取り込み時のアプローチ方法が関わってきそうなので、
OSバージョン、Acrobat DCのバージョンなども踏まえて具体的な記載をしてみてください。
Already have an account? Login
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
