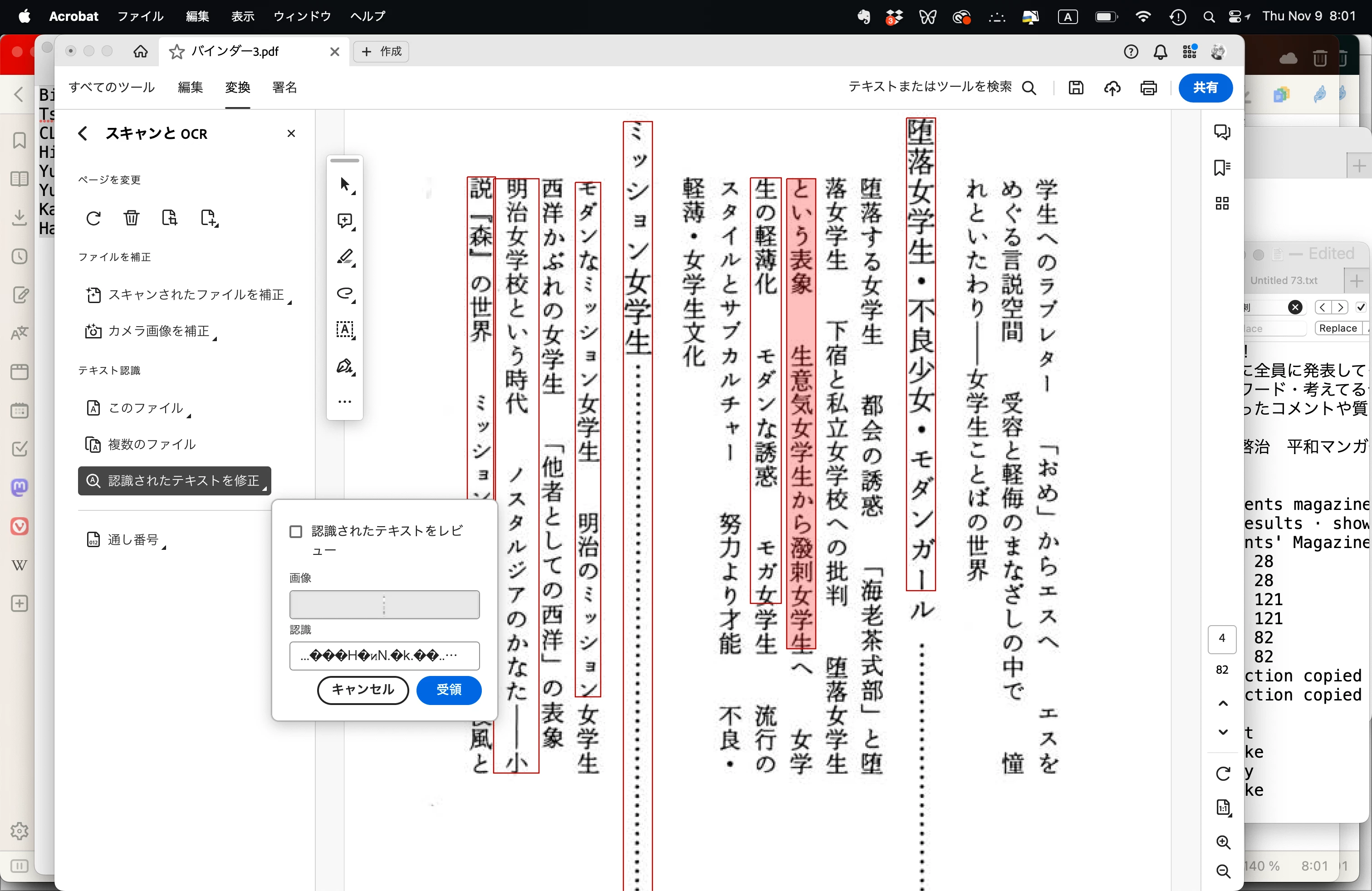
Answered
「認識されたテキストを修正」は日本語の場合文字化けする
MacOS用Acrobat Pro、 バージョン2023.006.20360を、2021年14インチMacBook Pro(M1)で使っています。OSはSonoma 14.0です。
スキャンした日本語の文章のOCRを修正したいのに、認識の正解率が99%であるにも関わらず、「認識されたテキストを修正」を使うと「認識」欄に表示されるのは「�����s��」などという典型的なもじばけです。しかも、「受領」をクリックしてしまうと、せっかく正しく認識された文字が「�����s��」に置き換えられてしまいます。ようするに「認識されたテキストを修正」機能をまったく使えません。むしろ使ってはいけません。唯一の確認する方法は、すべてのテキストをコピーしてワープロにペーストして見るしかありません。そしてそこで誤認識を見つけても、Acrobatでどう編集すれば良いか分かりません。きっと他の日本語ユーザもこの機能を使いたいはずです。みなさんはどうされていますか?