Question
Text Extraction from PDF
I am a Windows application developer using Visual Studio.
And trying to extract texts from a pdf file.
I get complete text extraction in ENGLISH language
But, not able to extract clean text in "SANSKRIT" and "GUJARATI" Languages.
I tried with different DLL libraries and functions.
Finally I got the problem and no Solution.
Problem : While extracting text from pdf, it does not give proper UNICODE of the character sometimes. SEE THE BELOW IMAGE.
THE PDF FILE HAS : 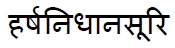
BUT THE TEXT FILE SHOWS : 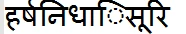
Kindly suggest the solution.