


リンクをクリップボードにコピー
コピー完了
システムから出力したPDFファイルをAcrobat Pro 11 で表示すると正常に表示するのですが、Acrobat Reader DCで表示すると一部に□(四角)が表示されてしまいます。
Acrobat Pro 11の表示とReaderの表示が異なっている状態です。
また、該当のPDFファイルをIE上で表示すると□(四角)が表示されて異常な状態ですが、Chrome上で表示すると□(四角)は表示されません。
現象の解消方法があればお教えください。
Version情報
Acrobat Reader DC 15.0.16.20041
Acrobat pro 11.0.08


 1 件の正解
1 件の正解
返信遅くなり、申し訳ありません。
DBから文字を取得して表示するシステムとなっていますが、DB上では変な文字列は入っていませんでした。
こちらで色々と試してみたところ、一部の文章(□が出てくる所ではないところですが。。。)のフォントを「MS 明朝」から「MS P 明朝」へ変更したところ、現象が出なくなりました。
対処療法的ですが、こちらで様子を見る予定です。
ありがとうございました。
 10
返信
10
10
返信
10

リンクをクリップボードにコピー
コピー完了
いくつか気になる点があります。
- どのようなシステムから出力したのでしょうか?
- フォントは埋め込まれていますか?
- 埋め込まれていない場合、実際の表示フォントは何になっていますか?
- ReaderとAcrobatの閲覧しているPCは同一ですか?
- 異なる場合、フォント環境はどういう状況ですか?
- IEとChrome環境はReaderやAcrobatと同一PCですか?
- OS環境は何でしょうか?
まずはそれらについて確認されるのが望ましいです。
リンクをクリップボードにコピー
コピー完了
情報不足、申し訳ありません。
- どのようなシステムから出力したのでしょうか?
帳票ソフト Crystal Reportsを使用して出力するシステムです。
OSはWindows Server 2008です。
- フォントは埋め込まれていますか?
フォントは埋め込まれています。
- ReaderとAcrobatの閲覧しているPCは同一ですか?
異なります。
AcrobatのPC(サーバ)にReaderをインストールして開いてみた時には現象は出ませんでした。
- 異なる場合、フォント環境はどういう状況ですか?
これは何をお答えすればよろしいでしょうか?
それぞれのインストールされているフォントでしょうか?
- IEとChrome環境はReaderやAcrobatと同一PCですか?
Readerで試したPCと同一です。
Windows7端末において、Reader、IE、Chromeで試しました。
- OS環境は何でしょうか?
クライアントのOS環境はWIndows7です。
以上、よろしくお願い致します。
リンクをクリップボードにコピー
コピー完了
フォントが埋め込まれているとのことですが、
一旦、文書のプロパティで、フォントの状態を確認していただけますか。
埋め込まれている場合、一般には「(埋め込みサブセット)」として
表示されるようになっていますが、同様になっているかチェックしてください。
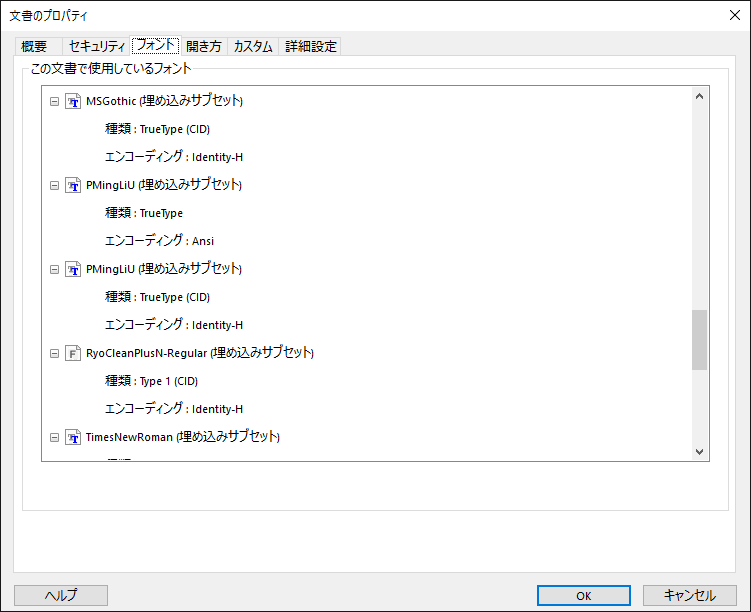
サーバ環境で開いている状態と、Windows 7で開いている状態が違うのは、
該当のフォントの有無ではないかと推測されます。
それが使用されているかどうかのように考えられるためです。
フォントが埋め込まれていない場合、Acrobatは、PC内にあるフォントを
適宜使って表示しますが、同一のフォントが無い場合は代替フォントになり、
そのフォントの該当文字コード内に字形がなければ、結果として文字は表示できません。
なお、Chromeで表示が異なるのは、Chromeが持つPDF表示機能での結果であり、
フォントがない場合の表示も異なっているからではないかと思います。
もうひとつ気になる点がありますが、
今回生成しているPDFは、製品版Acrobatを使って作成されているものでしょうか。
その際、どのような仕組みによって生成を行っているかも教えてください。
(対面・対話形式によるものなのか、リモートで自動化されているものか等)
リンクをクリップボードにコピー
コピー完了
以下に文書のプロパティ情報を添付いたします。
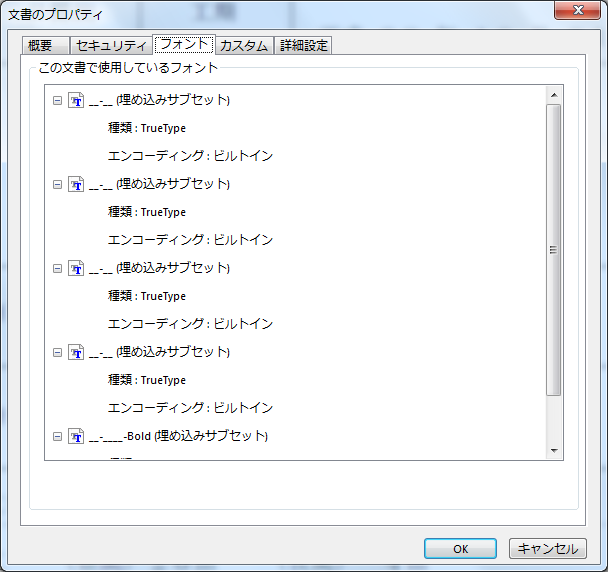
今回のPDF作成はシステムで自動化されています。生成はCrystalReportsという帳票ソフトの出力結果を
ASP.netを利用してPDF化しています。
よろしくお願い致します。
リンクをクリップボードにコピー
コピー完了
エンコーディングがビルトインなのが影響していると推測されます。
かなり以前の投稿ですが、類似の内容がありました。
ビルトインの場合、テキストエンコーディングがPDF内に内包されていますが、
それを正常に取り扱えるかはバージョンによって異なるものと思われます。
今回のケースにおいても、表示するバージョンが異なるため、
同様の可能性がありそうです。
また今回の場合、フォント名自体も正常とは言い難いと考えますので、
その影響もあるかもしれません。
どのエンジンで生成されたをご記載いただけませんでしたが、
Adobe純正でない、独自仕様のエンジンでPDFを生成した場合、
いわゆる互換PDFになりますので、その場合については
確実にAcrobatやReaderで表示できるかは、Adobeも保証していません。
よってその影響も考慮する必要があります。
ただ、通常版のAcrobatは、不特定多数のユーザーが利用したうえでサーバ上で
PDFを自動生成する利用としては認められていませんので、
そこについても考えなければなりません。

リンクをクリップボードにコピー
コピー完了
一部に□が表示されるということですが、期待通りの表示と比較されて、どんな文字が化けているかわかりますか?
- 特定の漢字・記号など
- 空白
それから、Adobe Reader DCとIEで、□が表示される場所は同じでしょうか?
もう一つ、文書のプロパティの概要のタブで、アプリケーションとPDF変換のところがどうなっているか教えて頂けますか?(スクリーンショットでもかまいません。CrystalReportsでしたら、CrystalReports自身で直接PDFを生成している可能性が高いと思いますが、それが確認できます)
リンクをクリップボードにコピー
コピー完了
一部に□が表示されるということですが、期待通りの表示と比較されて、どんな文字が化けているかわかりますか?
→上記は文字が化けて出ているというよりは特定の文章の後に□がくっ付いてしまっている状態です。
Unicode(PDFからコピーして調査)は、U+100000でした。
該当PDFの概要を貼り付けます。
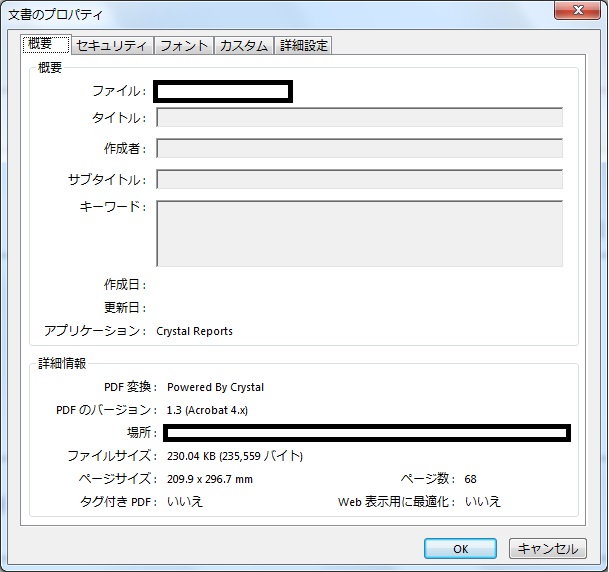
生成するエンジンですが、こちらでお分かりになりますでしょうか?
ちなみにCrystal Reports 2008を使用しております。
よろしくお願い致します。
リンクをクリップボードにコピー
コピー完了
NULL文字'\0'など、システム側で制御コードなどの不正な文字を埋め込んでいる可能性はありそうですね。
こういう文字を解釈しようとすると、表示されたりされなかったりするかと思います。
Crystal Reports 2008 の問題である場合、サービスパック適用状況の確認、システムの問題だとすると、コードの確認が必要かもしれません。開発者とコンタクトがとれる状況でしょうか?
リンクをクリップボードにコピー
コピー完了
返信遅くなり、申し訳ありません。
DBから文字を取得して表示するシステムとなっていますが、DB上では変な文字列は入っていませんでした。
こちらで色々と試してみたところ、一部の文章(□が出てくる所ではないところですが。。。)のフォントを「MS 明朝」から「MS P 明朝」へ変更したところ、現象が出なくなりました。
対処療法的ですが、こちらで様子を見る予定です。
ありがとうございました。
リンクをクリップボードにコピー
コピー完了
お世話になっております。
本現象ですが、Readerのバージョンにより、現象が出たりします。
11.0.12 現象出ません。
11.0.16 現象が出ます。
上記の2バージョンでは大きな差はあるのでしょうか?
よろしくお願い致します。

 AdChoices
AdChoices